WML Accelerator can be used along with IBM Watson® Studio Local or WML in IBM Cloud Pak for Data. Using WML Accelerator adds various enhancements to your AI platform
including accelerating the model training process, combining speed and accuracy to drive value and
time to market.
The GPU acceleration
that is provided by
WML Accelerator allows for your AI
platform to scale up and down automatically which allows for more GPU allocation and availability
helping a data scientist get faster results and reach a better level of model accuracy. Added
benefits of
WML Accelerator include:
- Helps data scientists optimize the speed of training by automating hyperparameter searches in
parallel.
- The elastic distributed training capability helps with distributing model training across
multiple GPUs and compute nodes, dynamically allocating and distributed to training jobs. Training
jobs can be added or removed seamlessly, where elastic distributed training handles the GPU
distribution for models that are built on stand-alone systems and makes the distribution apparent to
the user.
If
you plan on using WML Accelerator with IBM Watson Studio Local or WML, you must complete the following
installation.
Before you begin- Ensure that your system meets all requirements: Hardware and software requirements.
- Ensure that you have set up your system: Set up your system (Manual install).
- Consider user authentications when installing WML Accelerator with IBM Watson Studio Local or IBM Watson Machine Learning:
- To create a Spark instance group using the templates provided, make sure to configure a
pluggable authentication module (PAM), like LDAP, for user authentication: Configuring user authentication for PAM and default clients.
LDAP is required to enable impersonation with authentication for LDAP or OS execution users.
- User authentication can be handled by PAM, otherwise, the cluster administrator must add each
user to WML Accelerator.
Steps:- Install IBM Watson Studio Local: Installing IBM Watson Studio Local.
- Log in to the host as root or as a user with sudo permissions.
- Download the appropriate install package on the master host. If you are entitled to the packages, download it from Passport Advantage Online or Entitled Systems Support (ESS). If you want to evaluate the product, download the evaluation
packages from the WML Accelerator
1.2.1 Evaluation page.
- Set the EGO_TOP environment variable to be the path where you will install
IBM Spectrum Conductor™ Deep Learning Impact. If not set, the default is
/opt/ibm/spectrumcomputing.
- Extract the component packages.
- Log in to the master host with root or sudo to root permission.
- Run the WML Accelerator install package to extract the
install files:
- Entitled version
-
- Evaluation version
-
Note: WML CE
1.6.1 and the WML Accelerator license will be installed to $EGO_TOP/ibm-wmla/1.2.1/license. The default install location for IBM Spectrum Conductor Deep Learning Impact and IBM Spectrum Conductor is
/opt/ibm/spectrumcomputing.
- The WML Accelerator license panel is displayed. Review
the license terms and accept the license.
- Configure the system for IBM Spectrum Conductor Deep Learning Impact: Configure a system for IBM Spectrum Conductor Deep Learning Impact.
- Install IBM Spectrum Conductor by following
the instructions in one of these topics, depending on your environment:
- Entitle IBM Spectrum Conductor: Entitle IBM Spectrum Conductor.
- Update the public key for IBM Watson Studio Local.
- Get the standalone IBM Watson Studio Local
certificate:
wget -e https://ws_host:ws_port/auth/jwtcert
where
ws_host and ws_port is the IBM Watson Studio Local host IP address and port.
- Get the public PEM key from the certificate:
openssl x509 -pubkey -in jwtcert -noout >new_pub_key.pem
- Locate the JWT key file in IBM Spectrum Conductor Deep Learning Impact:
$>cat /opt/wmla/ego_top/dli/conf/dlpd/dlpd.conf |grep DLI_JWT_SECRET_KEY
"DLI_JWT_SECRET_KEY": "/dlishared/public_key.pem",
- Update JWT public file with the new certificate:
cat new_pub_key.pem > /dlishared/public_key.pem
- Update permissions of the JWT key file.
chmod 777 /dlishared/public_key.pem
- Restart dlpd service:
source /opt/wmla/ego_top/profile.platform
egosh user logon -u Admin -x Admin
egosh service stop dlpd
sleep 5
egosh service start dlpd
- Create a dedicated user for IBM Watson Studio Local named wml-user, for example,
from IBM Spectrum Conductor complete the following:
Note: - Each IBM Watson Studio Local user that wants to run training
jobs, must be added to WML Accelerator with a matching user
name. You can use a common LDAP server for both IBM Watson Studio Local and WML Accelerator for storing user
credentials.
- Multiple users can be created to assign roles that can restrict access within the WML Accelerator environment. For example:
wml-user and wml-admin.
- In the cluster management console, select .
- Click the Create New User Account icon in the
Users column.
- Fill in the fields, specifying wml-user as the account name.
- Click Create.
- Select the user wml-user and enable either the consumer user role
or the data scientist role.
- Log in as wml-user and create a Spark
instance group for distributed training. In this step, the
wmla-ig-template-2.3.3 template is used to create a Spark instance group that
is used by WML when pushing training jobs to WML Accelerator.
- Select the Workload tab and click .
- In the Instance Group List tab, click New.
- Click the Templates button to load the wmla-ig-template-2.3.3 template.
- Click Use to select and use the wmla-ig-template-2.3.3 template.
- Provide a name for the instance group, for example: wml-ig.
- Provide a directory for the Spark deployment. The wml-user user must
have read, write, and execute permissions to the directory specified and its parent directory.
- Set the execution user to wml-user.
- Provide a Spark version and configure Spark. By default, the template uses Spark version 2.3.3 and is configured for single node training
using Python 3.6. If you change
the Spark version, these configurations are lost and must be configured manually. Or if you want to
use a different training type or a different Python version, you must configure additional
parameters as follows.
- Under Consumers the Enable
impersonation to have Spark applications run as the submission user option is enabled. This option is required for IBM Watson Studio Local
and requires the use of LDAP.
- Under Resource Groups and Plans enable GPU slot allocation and specify
the resource group from which resources are allocated to executors in the instance group.
Make sure that the CPU executors resource group contains all the CPU and GPU
executor hosts. If you do not do this, GPU slots are used for the shuffle service.
- Select a CPU resource group for use by Spark executors (CPU slots).
- Select the previously created GPU resource group for use by Spark executors (GPU
slots).
- Create the Spark instance group by clicking Create and Deploy Instance
Group.
- Log in as wml-user and create a Spark instance
group for elastic distributed training. In this step, the
wmla-ig-edt-template-2.3.3 template is used to create a second Spark
instance group that will be used by WML when pushing elastic distributed training jobs to WML Accelerator.
- Select the Workload tab and click .
- In the Instance Group List tab, click New.
- Click the Templates button to load the wmla-ig-edt-template-2.3.3 template.
- Click Use to select and use the wmla-ig-edt-template-2.3.3 template.
- Provide a name for the instance group, for example: wml-ig-edt.
- Provide a directory for the Spark deployment. The wml-user user must
have read, write, and execute permissions to the directory specified and its parent directory.
- Set the execution user to
wml-user.
- Provide a Spark version and configure Spark. By default, the template uses Spark version 2.3.3 and is configured for single node training
using Python 3.6. If you change
the Spark version, these configurations are lost and must be configured manually. Or if you want to
use a different training type or a different Python version, you must configure additional
parameters as follows.
- SPARK_EGO_EXECUTOR_SLOTS_MAX must be set to 1.
- SPARK_EGO_EXECUTOR_SLOTS_RESERVE must be set to
1.
- SPARK_EGO_GPU_EXECUTOR_SLOTS_MAX must be set to
1.
- SPARK_EGO_GPU_EXECUTOR_SLOTS_RESERVE must be set to
1.
- SPARK_EGO_EXECUTOR_IDLE_TIMEOUT must be set to
6000.
- SPARK_EGO_CONF_DIR_EXTRA must be set to
${DLI_SHARED_FS}/conf. For example, if DLI_SHARED_FS is
set to /gpfs/dlfs1 for deep learning, then set
SPARK_EGO_CONF_DIR_EXTRA to /gpfs/dlfs1/conf.
- SPARK_EGO_AUTOSCALE_GPU_SLOTS_PER_TASK is set to 1
.
- SPARK_EGO_ENABLE_PREEMPTION is set to true.
- SPARK_EGO_APP_SCHEDULE_POLICY is set to
fairshare.
- When using fairshare, make sure that you:
- Do not disable reclaim for the executor consumers and do not set
SPARK_EGO_RECLAIM_GRACE_PERIOD. Use the default IBM Spectrum Conductor reclaim settings for the
consumer.
- Do not change the SPARK_EGO_SLOTS_REQUIRED_TIMEOUT value for a Spark instance
group with fairshare.
- Framework plugins do not support a Spark instance group where the
SPARK_EGO_APP_SCHEDULE_POLICY is configured for
fairshare. Framework plugins only support Spark instance group that are
configured with fifo.
In addition to these configurations, also consider the following:
- By default, the Spark instance group uses Python 3.6 . If you want to use Python 2.7, set the
PYTHON_VERSION environment variable to python2. To add
this environment variable, do the following:
- In the parameter drop down, select Additional Environment Variables and
click Add an Environment Variable.
- Set the Name to PYTHON_VERSION and the
Value to python2.
- Click Save.
- If you want to set additional Spark parameters, refer to Creating a Spark
instance group to use GPUs.
- Under Consumers the Enable
impersonation to have Spark applications run as the submission user option is enabled. This option is required for IBM Watson Studio Local
and requires the use of LDAP.
- Under Resource Groups and Plans enable GPU slot allocation and specify
the resource group from which resources are allocated to executors in the Spark instance group.
Make sure that the CPU executors resource group contains all the CPU and GPU
executor hosts. If you do not do this, GPU slots are used for the shuffle service.
- Select a CPU resource group for use by Spark executors (CPU slots).
- Select the previously created GPU resource group for use by Spark executors (GPU
slots).
- Create the Spark instance group by clicking Create and Deploy Instance
Group.
- After successfully creating an instance group for both
distributed training and elastic distributed training, you can set up resource sharing between both
instance groups so that all workloads have access to available resources.
- Open and edit the ego.conf configuration file to set
EGO_ENABLE_BORROW_ONLY_CONSUMER to Y. Save your changes
and close the file.
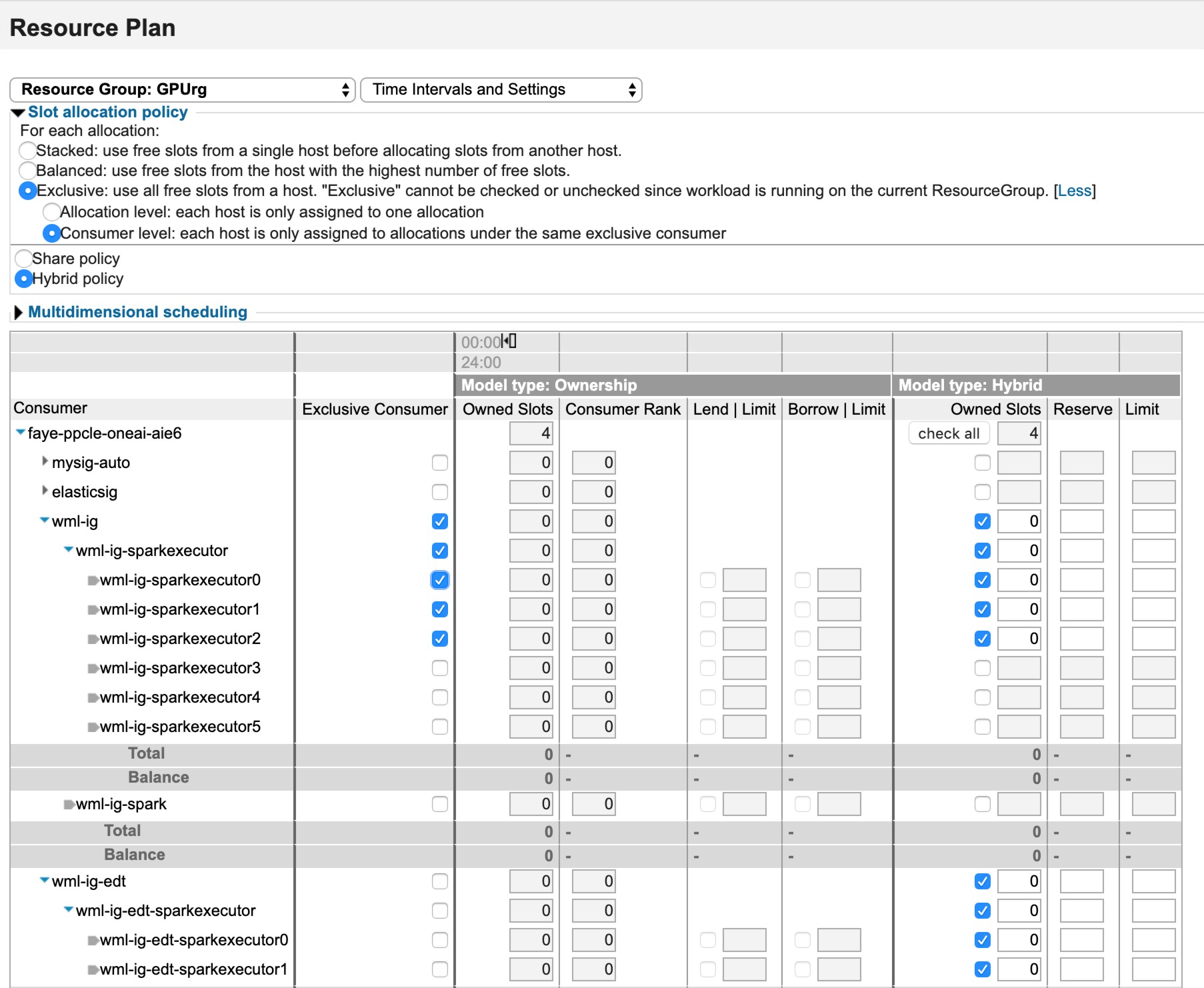
- In the consumer plan, update slot formation for both instance groups.
- For the elastic distributed training Spark instance group, for the top consumer, specify
0 for owned slots.
- For the other Spark instance group, for the top consumer specify 1 for
owned slots.
- Set the limit for the distributed training consumer as the total number of slots in
the GPU group minus 1.
- After updating ego.conf, the consumer can be modified from the
cluster management console. Set non-master workloads to 0 for share ratio.
- Enable the following so that for non-elastic distributed training jobs, if a job
allocates 4 GPUs then it allocates the whole host exclusively. Configure the
wml-ig and wml-ig-edt GPU resource plan.
- From the Resources menu, select
.
- Configure the resource plan for wml-ig and
wml-ig-edt as follows:
- Set the reclaim grace periods for wml-ig and
wml-ig-edt.
- From the Resources menu, click
Consumers.
- Set Reclaim Grace Period to 596 hours at
the consumer level for wml-ig and for each child consumer belonging to
wml-ig.
- Set Reclaim Grace Period to 120 seconds
at the consumer level for wml-ig-edt.
- Configure GPU mode to exclusive across all nodes. From the command line interface, do the
following:
- Set GPU mode to exclusive process mode.
nvidia-smi -c 1
- Ensure GPU mode is set to exclusive process mode.
nvidia-smi
- Restart ego.
- Connect Watson Machine Learning with WML Accelerator. Run the updateWMLClusterdetails.sh
command line utility which allows IBM Watson Studio Local to
locate and use a WML Accelerator instance.
- Use SSH to remotely access the Watson Machine Learning host from the master
host.
- Switch to the IBM Watson Machine Learning directory.
cd /ibm/InstallPackage/components/modules/wml
- Run the following
command:
./updateWMLClusterdetails.sh <wmla_host> <wmla_ port> <wmla_default_ig> <wmla_default_edt_ig> <wml_external host adress>
where: wmla _host is the IP address that can be accessed from WML cluster in WML Accelerator cluster master host
wmla_ port is the port exposed by WML Accelerator for the deep learning rest API. By default this is
set to 9243
wmla_default_ig is the Spark instance group name created in WML Accelerator for single and distributed jobs. For example:
wml-ig
wmla_default_edt_ig is the instance group created in WML Accelerator for elastic distributed training jobs. For example:
wml-ig-edt
wml_external_host is the external host name of a modified IBM Cloud Pak for
Data console URL that can be accessed from WML Accelerator.
For
example:updateWMLClusterdetails.sh https://wmla-master.example.com 9243 wml-ig wml-ig-edt
Learn
more about running the command line utility: Setting up WML Accelerator with IBM Watson Studio Local
After you have successfully connected
WML Accelerator with IBM Watson Machine Learning and Watson Studio, here are a few links to get you
started: