
Conducting research at the utility scale requires being able to perform a large number of utility-scale workloads. Because each of those workloads may take tens of hours to run from start to finish, our fleet of quantum systems must check off a few important boxes. Our systems must offer a sufficient number of utility-scale processors, they must be stable, and they must be available around the clock — 24/7.
IBM® has spent the past year working to meet each of these criteria. As a result, we now have the largest fleet of 100+ qubit systems in the world, lead the industry in available machine time on our systems, and have achieved over 95% uptime across our systems. These qualities allow our service to support a varied set of execution modes, a framework we offer to optimize the process of running different kinds of utility-scale workloads.
In this blog post, we’ll take a look at three new and improved execution modes Qiskit users can employ when running quantum workloads. These include job mode, session mode, and batch mode. Each of these provides different kinds of efficiencies depending on the type of workload a user wants to run. But before we learn more about these individual modes and the types of workloads they’re useful for, let’s first take a moment to define what execution modes are, and how they benefit our users.
What are execution modes?
You can think of an execution mode as the rules or procedures that govern how a user’s quantum circuits will run on quantum and classical resources. When IBM put the first quantum computer in the cloud in 2016, users could only execute circuits as individual jobs. In 2022, we introduced a new kind of execution mode — Qiskit Runtime sessions — which for the first time allowed Qiskit Runtime users to efficiently run iterative, multi-job workloads on quantum hardware.
Since then, we’ve been working to see how we can use execution modes to optimize the user experience even further. The three execution modes detailed in this blog post will give users more flexibility than ever in choosing how the circuits they want to run should be grouped together or divided up for optimal execution.
Job mode: All the context you need in a single primitive request
We’ve put a lot of effort into developing execution modes to help users run complex multi-job workloads, but simple standalone jobs are still vitally important. They’re foundational for learning, since every quantum novice starts out by submitting standalone jobs, and they’re also the most cost-effective method for running initial experiments and tests. Users rely on standalone jobs for testing and debugging circuits — a crucial process when transitioning smaller workloads to the utility scale.
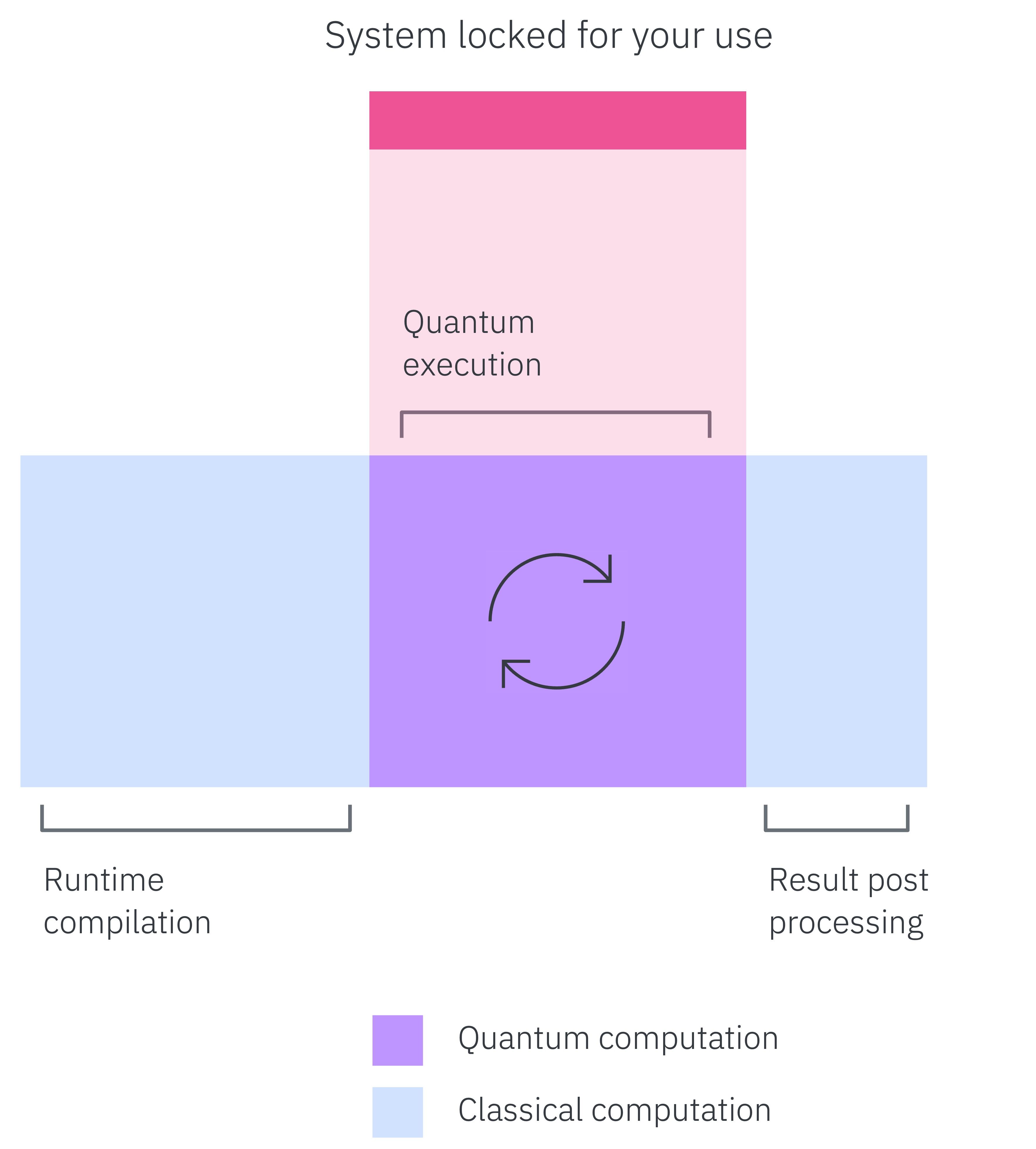
As we began looking for ways to further optimize the execution of individual jobs, we found that we could actually break down the base construct we call a “job” into three runtime steps occurring after transpilation: (1) runtime compilation, (2) quantum execution, and (3) the post-processing required to generate results.
In the past, a user’s job would “lock” the system during the time required for these three steps to take place. But we found we could help users employ their system capacity more efficiently if we used the three-step framework to define the system lock at a finer level. In the new job mode, we exclude runtime compilation and classical post-processing from the lock period, increasing the total work users can run on quantum systems when submitting individual jobs.
Batch mode: Multi-job workloads submitted all at once
Batch mode is a context manager that allows users to more efficiently run experiments comprising multi-job workloads. These workloads are made up of independently executable jobs that have no conditional relationship with each other.
With batch mode, users submit their jobs all at once. The system parallelizes or threads the pre-processing step of each primitive job to more tightly package quantum execution across jobs, and then runs the quantum execution of each job in quick succession to deliver the most efficient results. We believe this framework will be especially helpful for improving execution efficiency in utility-scale workloads.
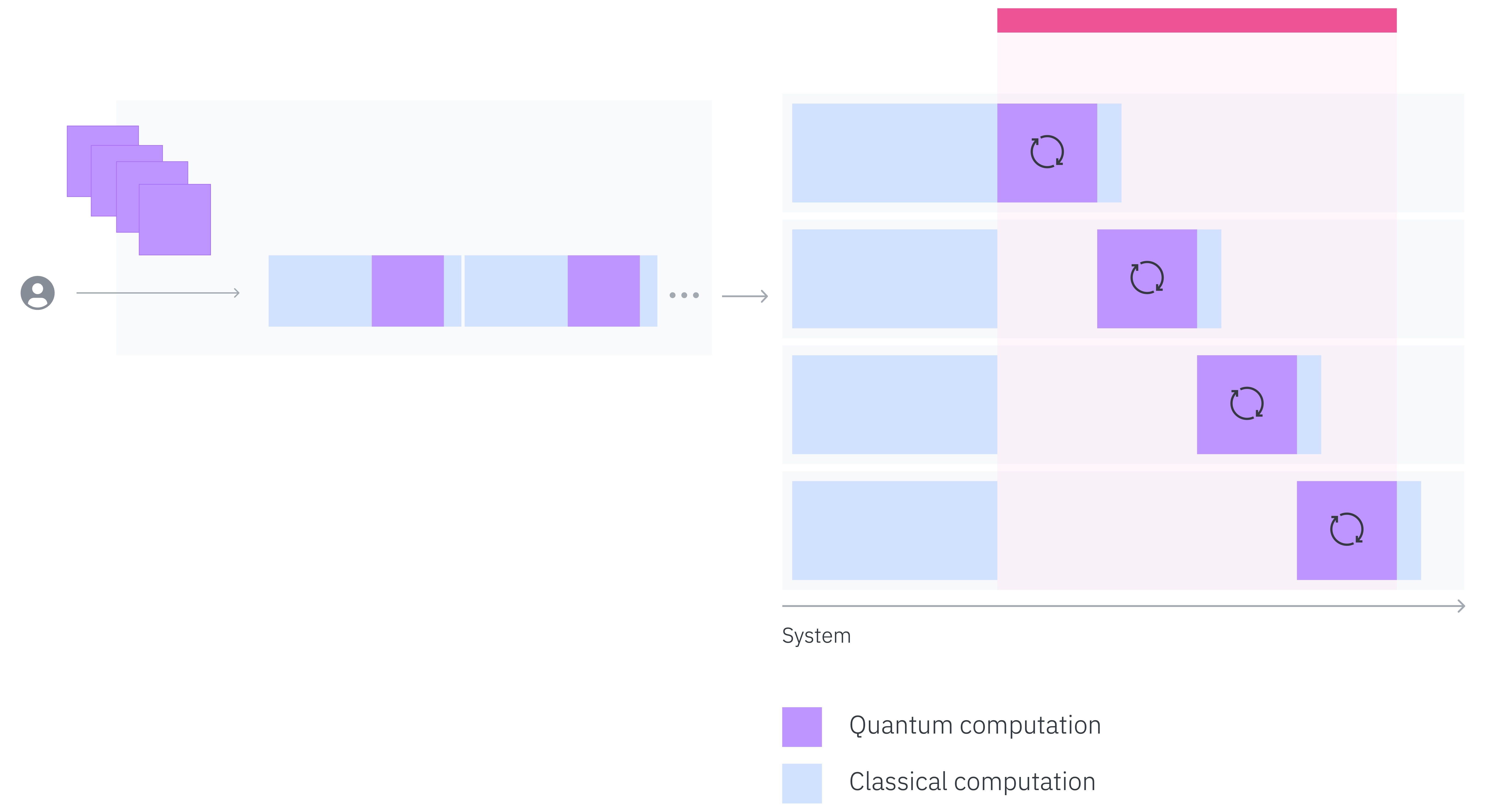
The example below shows how you can divide up a long list of circuits into multiple jobs and run them as a batch to take advantage of this parallel processing.
from qiskit_ibm_runtime import SamplerV2 as Sampler, Batch
max_circuits = 100
all_partitioned_circuits = []
for i in range(0, len(circuits), max_circuits):
all_partitioned_circuits.append(circuits[i : i + max_circuits])
jobs = []
start_idx = 0
with Batch(backend=backend):
sampler = Sampler()
for partitioned_circuits in all_partitioned_circuits:
job = sampler.run(partitioned_circuits)
jobs.append(job)Find more details of the new batch mode in our documentation, here.
Session mode: Multi-job workloads with conditional updates
With session mode, we’ve made some key improvements to the Qiskit Runtime sessions execution mode originally introduced in 2022. These improvements serve to remove artificial latencies involved in running iterative workloads, and help to make those workloads more reliable and predictable.
Iterative workloads are multi-job workloads that we prepare in a recursive fashion. We set up these workloads so that the results of one job determines conditional updates the system will make to the inputs of the next, with subsequent results determining subsequent inputs until the experiment converges. Popular examples of this framework include widely-used quantum algorithms like VQE and QAOA. We developed Qiskit Runtime sessions to help users manage this iterative process more efficiently.
The original Qiskit Runtime sessions functioned as a context manager that allowed users to manage iterative workloads and the jobs they contain as a single experiment. Once the first job of the workload began, all subsequent jobs were processed with priority, minimizing unnecessary queue time.
Now, to increase the efficiency, reliability, and predictability of Qiskit Runtime sessions even further, we’re extending the notion of “locking” a system to our new session mode. With session mode, systems won’t just prioritize jobs grouped together in a session, but instead will give your workload exclusive and dedicated use of the system from the start of your first job until the end of your last.
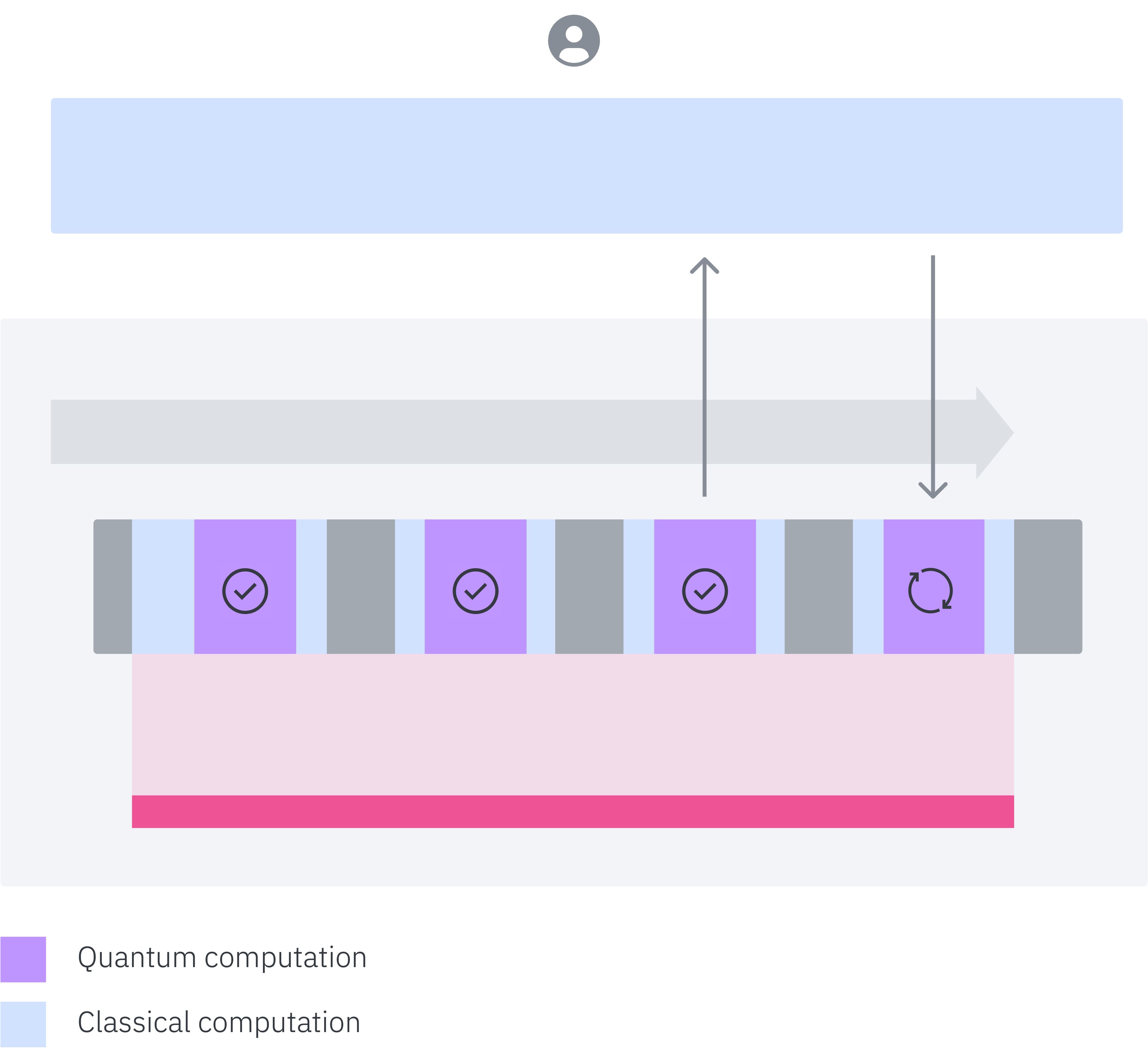
In other words, using the new session mode means the system will be locked to your session. This will give users a more granular understanding of how their job loops in an iterative routine, which in turn will help users better estimate their session runtimes. Notably, these dedicated sessions are now thread safe, meaning users can run multiple workloads inside a session. Because our stack permits multiple parallel pipelines of execution for both the runtime compilation and post-processing steps, the new session mode gives you exclusive access to these resources and enables more efficient use of the overall system time by running multiple jobs at once.
Let’s take a look at some example code to see how that works. The two code blocks below show how to run two VQE algorithms in session mode using threading. The first step is to import the tools we need to run our algorithm. Here, we’ll use EfficientSU2 as our ansatz, and SparsePauliOP as our operator class:
# General imports
import time
# Pre-defined ansatz circuit and operator class for Hamiltonian
from qiskit.circuit.library import EfficientSU2
from qiskit.quantum_info import SparsePauliOp
# The IBM Qiskit Runtime
from qiskit_ibm_runtime import QiskitRuntimeService
# SciPy minimizer routine
from scipy.optimize import minimize
# Define the Hamiltonian, ansatz, and initial parameter value.
hamiltonian = SparsePauliOp.from_list(
[("YZ", 0.3980), ("ZI", -0.3980), ("ZZ", -0.0113), ("XX", 0.1810)]
)
ansatz = EfficientSU2(hamiltonian.num_qubits)
num_params = ansatz.num_parameters
x0 = 2 * np.pi * np.random.random(num_params)
# Optimize the circuits
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
ansatz = pm.run(ansatz)
# Define the cost function
def cost_func(params, ansatz, hamiltonian, estimator):
pub = (ansatz, [hamiltonian], [params])
result = estimator.run(pubs=[pub]).result()
energy = result[0].data.evs[0]
return energyOnce we’ve established our inputs, we can set up our session and start running multiple iterative workloads:
# Example: running 2 VQEs in a session using threading.
# Job tags are used to differentiate the workloads.
from concurrent.futures import ThreadPoolExecutor
from qiskit_ibm_runtime import EstimatorV2 as Estimator
def minimize_thread(estimator, method):
return minimize(cost_func, x0, args=(ansatz, hamiltonian, estimator), method=method)
with Session(backend=backend), ThreadPoolExecutor() as executor:
estimator1 = Estimator()
estimator2 = Estimator()
# Use different tags to differentiate the jobs.
estimator1.options.environment.job_tags = ["cobyla"]
estimator2.options.environment.job_tags = ["nelder-mead"]
# Submit the two workloads.
cobyla_future = executor.submit(minimize_thread, estimator1, "cobyla")
nelder_mead_future = executor.submit(minimize_thread, estimator2, "nelder-mead")
# Get workload results.
cobyla_result = cobyla_future.result()
nelder_mead_result = nelder_mead_future.result()For more details on the new session mode, be sure to refer to our docs, here.
Boosting efficiency for utility-scale workloads
We believe the new execution modes we’ve introduced will be invaluable to users as they begin exploring more utility-scale workloads. They provide a convenient framework for executing individual jobs, multi-job workloads containing iterative jobs, and multi-job workloads containing independently executable jobs. At the same time, the new execution modes also boost the reliability, predictability, and efficiency of those jobs to help ensure our users get the most out of our systems.
Comparing the benefits of different execution modes.
| Mode | Usage | Benefit |
|---|---|---|
| Job mode | Quantum computation only. | For small numbers of jobs. Easiest to use when running a quick experiment. May run in less time than batch mode, and may be the fastest option for small jobs. |
| Batch mode | Quantum computation only. | Up to 5x faster for utility scale jobs. For large numbers of non-iterative jobs, using a batch will reduce the total time required. The entire batch of jobs is scheduled together and there is no additional queueing time for each. Jobs in a batch are run close together. |
| Session mode | Classical and quantum computation. | Gives complete and consistent control over classical and quantum resources, allowing you to optimize your workflow for a consistent experience at a higher cost. Dedicated and exclusive access to the system during the session active window, and no other users’ or system jobs can run. |
Be sure to check our documentation for more details and ample code examples showing how to leverage the new execution modes in your experiments.



