How To
Summary
Content Platform Engine 5.5.8 introduces a technology preview of a new content-based search feature that uses either the Elasticsearch search engine or the OpenSearch search engine. It can be used as an alternative to the IBM Content Search Services (CSS) for full text indexing and search.
This new content-based search feature operates similar to IBM Content Search Services. The Document class, along with the Annotation, Folder, and Custom Object classes, and the string properties of those classes can be enabled for full text indexing.
Full text search works similar in both the new content-based search feature and in IBM Content Search Services. For example, an SQL statement is used with a CONTAINS clause that specifies the full text search criteria. However, there are differences between Elasticsearch and IBM Content Search Services as the stemming algorithm is different. There are also differences in the query syntax.
Objective
This document provides insight into the new content-based search feature and aims to discuss the differences between it and IBM Content Search Services.
The search engine (Elasticsearch/OpenSearch content-based search and/or IBM Content Search Services) to object store mapping is as follows:
- The Content Platform Engine domain can support both the new Elasticsearch/OpenSearch content-based search feature and IBM Content Search Services.
- A domain can support one Elasticsearch/OpenSearch content-based search cluster.
- An Object Store can support either Elasticsearch/OpenSearch content-based search or IBM Content Search Services, but not both.
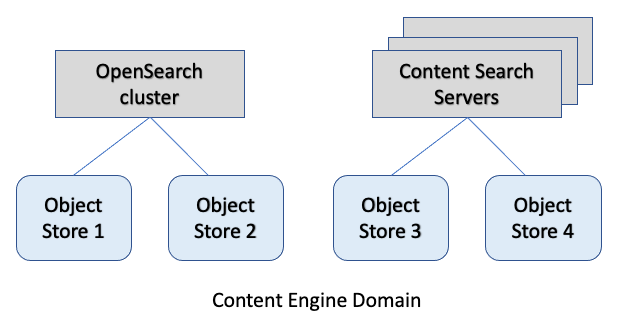
Elasticsearch/OpenSearch Index Areas
An Object Store can support one Elasticsearch/OpenSearch index area. The index area contains one Elasticsearch/OpenSearch index per enabled root class, for example, one index for Document and all subclasses of Document, one index of Custom Object and all subclasses of Custom Object. The IBM Content Search Services comparatively supports multiple index areas per object store, and multiple partitioned indexes per index area. The Elasticsearch/OpenSearch index scale-out is based on index sharding, which is controlled by Elasticsearch/OpenSearch, unlike IBM Content Search Services, where it is controlled by the Content Platform Engine.
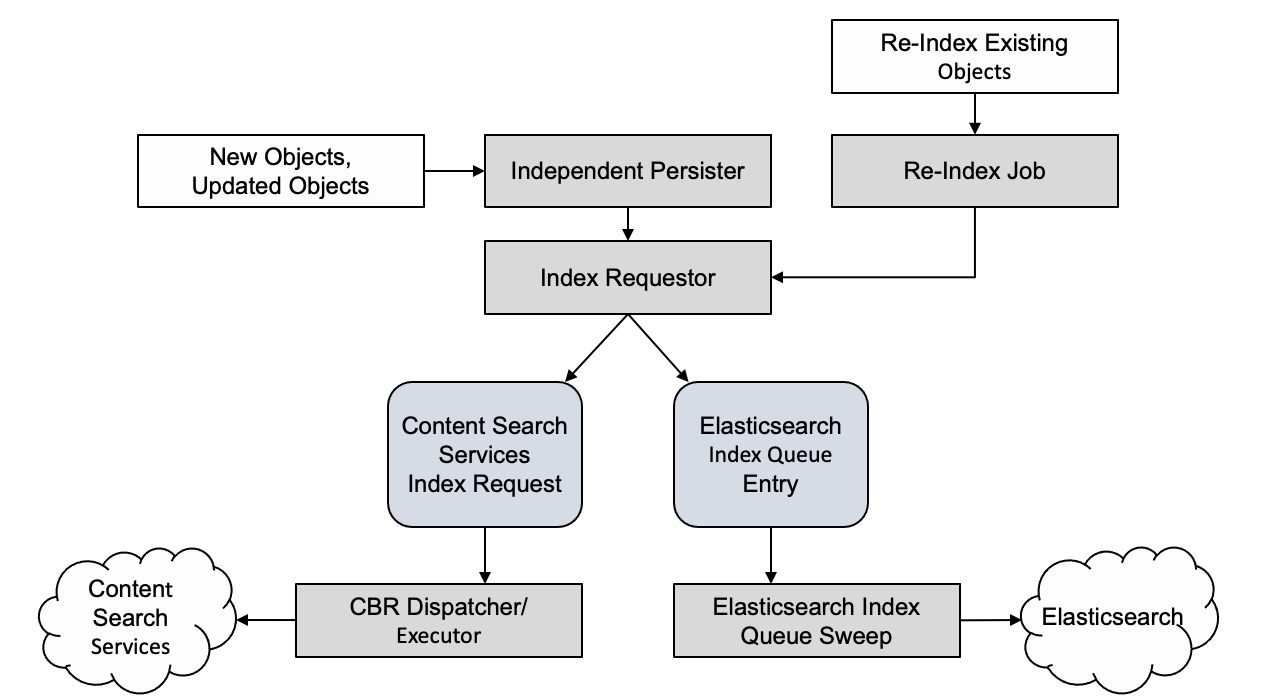
Indexing Pipeline
The indexing pipeline used for Elasticsearch/OpenSearch uses a queue sweep (Elasticsearch Indexing Queue Sweep) for indexing. The Content Platform Engine Object Persisters (server code that creates, updates, and deletes objects) create index queue requests for newly created, updated, or deleted objects that are Content Based Retrieval(CBR) enabled. An Index Job creates queue entries when you perform a class initial index or reindex. The index entries are processed by the indexing queue sweep, which indexes the content and properties that use the OpenSearch REST API.
The diagram illustrates the indexing pipeline for Elasticsearch/OpenSearch and for IBM Content Search Services.
Environment
Only releases that support the "Point in Time" search feature are officially supported. The releases include:
- OpenSearch 1.3.x and later
- Elasticsearch 7.10.x and later
Note: You can use OpenSearch or Elasticsearch releases that do not support Point in Time search to explore the technology preview feature. However, this might result in inaccurate search results for large result sets and would not be supported by a future GA release of the feature.
In the technology preview, ACCE does not display the Elasticsearch/OpenSearch content-based search configuration options by default. To enable the configuration options in ACCE, a JVM parameter must be set on all Content Platform Engine servers in the domain (a restart of the Content Platform Engine is required to activate the parameter):
com.filenet.acce.enableElasticsearch=true
Steps
Note: For the purposes of this document, the terms "Elasticsearch" and "OpenSearch" are interchangeable.
You have to configure the OpenSearch cluster to allow access by the Content Engine. The Content Engine supports both IP-based security and username/password based security.
For IP-based security, access to the OpenSearch cluster is controlled by client IP addresses that can access the cluster(normally within a VPN). As a result, the Content Engine OpenSearch cluster object is created without specifying a username or password.
For username/password based security, credentials need to be created on the OpenSearch cluster to allow access by the Content Engine. The specified credentials are set as the username/password properties of the Content Engine OpenSearch cluster object. The REST API Usage table in this technote describes the end points and index resources used by the Content Engine. The credentials that you create on the OpenSearch cluster must grant the Content Engine permissions to use those end points.
Note: In the technology preview, the Content Engine does not sign OpenSearch REST requests, and does not support the AWS security model that requires request signing.
- Create an OpenSearch cluster at the domain level - You can create an OpenSearch cluster by selecting Domain -> Global Configuration -> Administration -> Elasticsearch Clusters in the ACCE console. There can be a single OpenSearch cluster per domain and the cluster can be shared by multiple object stores. The cluster definition specifies a single host name(an OpenSearch load balancer), or a list of host names. If a list of host names is supplied, the Content Engine manages requests across the set of hosts in round-robin basis. Note that a port needs to be specified to access the cluster, and the port number must be appended to the host name (for example, hostname: 9200).
- Create OpenSearch index area at the object store level - You can create an index area from ObjectStore -> Administrative -> Index Areas in the ACCE console. It is important to consider the number of shards and replicas per index when you create the index area, since these values cannot be changed without reindexing once the index is created (see Best Practices section).
- Enable OpenSearch at the object store level - You can enable OpenSearch at the object store level from ObjectStore -> Text Search in the ACCE console. It is important to consider the OpenSearch analyzers that you choose when you enable OpenSearch at the object store level. The analyzers are applied to the index when objects are first indexed, and if the analyzer list is changed, the objects must be reindexed(see Best Practices section).
- Enable CBR on classes and properties. Once a class is enabled for CBR, newly created objects of the class are automatically indexed.
- Index existing objects. If there are existing objects for classes that are CBR enabled, you can index those objects by selecting Index Class for CBR by using ACCE.
- Monitor Elasticsearch Indexing Queue Sweep by using ACCE.
Additional Information
Refer IBM Documentation topic CBR Queries to understand how the
The syntax of the
CONTAINS(d.*,'documenttitle.english:arches')
The query syntax used within the
Selecting the proper number of shards for an index area
The Content Engine takes advantage of OpenSearch index sharding to achieve index scale-out. It is important to use enough shards when you create the index area, since the number of shards cannot be changed without performing a full reindex. The OpenSearch administrator needs to determine the correct number of shards for the index area based on predicted ingestion volume, number of shards the cluster can manage, and so on. The number of replicas need to be considered when you create the index area, since they provide high availability for the indexed data.
Selecting the proper language analyzers for the object store
OpenSearch uses analyzers for indexing and for searching. The analyzers used by the Content Engine are set at the object store level, and are applied to all CBR enabled classes of the object store. For more information about Analyzers, refer to OpenSearch documentation.
If the analyzer list changes, a reindex is required. It is suggested to use one language analyzer (or more if your documents are in multiple languages, for example, you can use English and French) plus the simple analyzer (which breaks tokens on punctuation).
However, using the simple analyzer can cause problems with searches not finding strings with numbers. For example, ‘J02’ is being tokenized as just ‘j’. This causes the search results to match far more documents than expected. To avoid the problem, the usage of simple analyzer has to be carefully reviewed before setting it up, to match expectations on the content-based search requirements. Without the simple analyzer (English analyzer only), sentences that lack spaces between the punctuation will not be tokenized as expected.
Indexing Queue Sweep maximum workers
The indexing queue sweep is automatically created during OpenSearch indexing. The sweep is defined with a default of two workers. In many cases, you need to increase the number of workers to improve indexing throughput. It is difficult to estimate if an increase in the indexing queue workers impacts indexing throughput, or if the increase in the workers has a negative impact on other Content Engine operations. It is recommended that you increase the number of workers incrementally while you monitor the system by using System Dashboard (if available), or monitoring Content Engine system resources (CPU, memory, and other resources).
Tuning Content Based Retrieval indexing with Elasticsearch for high volume workload
For high volume ingestion, migration, or re-indexing scenarios, the default configuration for the Elasticsearch Indexing Queue Sweep may not be sufficient. When a large number of documents get into the system, the number of indexing requests can start to build up. This can cause a significant delay in document's availability to be searched. The following changes can help improve indexing throughput rate.
- Increasing the number of sweep workers - If necessary, you can increase the number of sweep workers, which is the preferred method of tuning indexing performance. To change the maximum number of sweep workers, go to Object Store > Sweep Management > Queue Sweeps > Elasticsearch Indexing Queue Sweep > Properties > Maximum Sweep Workers.
- Tuning Bulk batch size - The indexing rate can also be affected by tuning the BulkAPI batch size. This BulkAPI batch size controls the size of batches that Content Engine submits for indexing to Elasticsearch cluster. The default BulkAPI batch size is 40 documents and you can adjust the value by using the JVM argument
ecm.elasticsearch.bulkapi.max.batch.size for Content Platform Engine.
Point in time search and continuation queries
The Content Engine relies on point in time search to provide accurate search results for continuable queries. If a version of OpenSearch is used that does not support point in time search, the Content Engine limits continuable queries to a single round trip to OpenSearch. This causes a partial result set to be returned, or cause the query to fail. To ensure accurate query results, only an official release that supports Point in Time searches (see Supported Opensearch releases) must be used.
Read Time-out
In some cases, OpenSearch related Read timed out error messages might appear in the Content Engine logs. This happens during indexing, when it takes longer than the default read timeout value of 90 seconds to complete an operation on the OpenSearch side. The read timeout value can be changed by setting the JVM on all Content Engine servers (changed to 120 seconds in the example):
-Decm.elasticsearch.read.timeout.ms=120000
Index Statistics
In the technology preview, you can retrieve the count of objects in an OpenSearch index in ACCE by selecting the Properties Tab under ObjectStore -> Index Area. Edit the Elastic Search Indexes property and select an index from the list(select Elastic Search option 1 for documents, option 2 for annotations, option 3 for custom objects, and option 4 for folders). You can now find the count of objects under the Indexed Object Count property. You can also change your index selection from the Index tab under ObjectStore -> Index Area.
Alternatively, you can also use the OpenSearch REST API directly to retrieve the count of objects in an OpenSearch index, for example, you can query the
Content Truncation
The Content Engine limits the size of an indexing request sent to OpenSearch by truncating the extracted content if needed. This is done to avoid exceeding the OpenSearch maximum payload size (see OpenSearch
-Decm.elasticsearch.content.payload.max.chars=77000000
This section describes the OpenSearch REST API used by the Content Engine. This is provided for OpenSearch system administrators to determine how to select and apply the proper permissions to the OpenSearch users. The permissions are used by the Content Engine to access the OpenSearch cluster, create indexes, and so on.
|
Action |
Description |
End Point |
Method |
|
Get basic cluster information |
Used to test cluster existence, obtain cluster name, software version number and distribution type. |
[Cluster Base URL]/ |
GET |
|
Create index |
The index name is always prefixed by 'fncm_' (only access to indexes with names that begin with 'fncm_' is needed by Content Engine). |
/<index-name> |
PUT |
|
Delete index |
/<index-name> |
DELETE |
|
|
Update index mapping |
Define the properties and analyzers of the index. |
/<index-name>/_mapping |
PUT |
|
Get index mapping |
Get the index mapping of the index. |
/<index-name>/_mapping |
GET |
|
Close or open index |
Future, not used in 5.5.8. Close index to perform maintenance operation, open index when completed. |
/<index-name>/close /<index-name>/open |
POST |
|
Update index settings |
Future, not used in 5.5.8. |
/<index-name>/_settings |
PUT |
|
Get index settings |
Get the settings of the index. |
/<index-name>/_settings |
GET |
|
Index object create |
Index a new object. |
/<index-name>/_doc/<object_id> |
PUT |
|
Index object update |
Update the indexed data of an existing object. |
/<index-name>/_update/<object_id> |
POST |
|
Index object delete |
Delete the indexed data of an existing object. |
/<index-name>/_doc/<object_id> |
DELETE |
|
Search |
Search without point in time context. Also used to get single object by object_id, and a set of objects by their object_Ids). |
/<index-name>/_search |
GET |
|
Point in time search |
Search with point in time context. |
/_search |
GET |
|
Count objects |
Count the number of objects that satisfy a query string. |
/<index-name>/_count |
GET |
|
Get index statistics |
Get the approximate number of objects in an index and the size of the index. |
/_cat/indices/<index-name> |
GET |
|
Get number of indexed documents |
Count the number of documents in the index. |
/_cat/count/<index-name> |
GET |
|
Get indexes |
Get list of indexes. |
/_cat/indices |
GET |
|
Check whether index exists |
Test index existence. |
/<index-name> |
HEAD |
|
Initiate point in time search |
Initiate a point in time search, obtain a point in time ID (to be used with point in time search). |
/<index-name>/_pit |
POST |
|
Delete point in time search |
Delete point in time search reference. |
/<index-name>/_pit |
DELETE |
Document Location
Worldwide
Was this topic helpful?
Document Information
Modified date:
18 July 2022
UID
ibm16528340