Troubleshooting
Problem
Symptom

oc describe po zen-core | grep Image | grep zen-core@
Image ID: docker-pullable://docker-registry.default.svc:5000/test/zen-core@sha256:a136d6fc976790aafb07d9edf25aef4e85c90724c4212f92b7fa2911a1c7aef8 Image ID: docker-pullable://docker-registry.default.svc:5000/test/zen-core@sha256:a136d6fc976790aafb07d9edf25aef4e85c90724c4212f92b7fa2911a1c7aef8 Image ID: docker-pullable://docker-registry.default.svc:5000/test/zen-core@sha256:a136d6fc976790aafb07d9edf25aef4e85c90724c4212f92b7fa2911a1c7aef8
This can be observed when at least a couple of Cloud Pak for Data services are deployed and becomes more significant as the number of pods increases.
To determine if you are affected by this, run:
oc describe node | sed -n -e '/Allocated/,/Events/p' -e 's/Name:/\n---:>&/p'
and
oc get po --all-namespaces -o wide --no-headers | grep -v Comple | awk '{print $(NF-1)}' | sort | uniq -c
Please note if one node (in most cases a worker) is significantly more utilized than the rest. For example:
22 e1n1-1-control.fbond 22 e1n2-1-control.fbond 22 e1n3-1-control.fbond 125 e1n4-1-worker.fbond 44 e2n1-1-worker.fbond 55 e2n2-1-worker.fbond 49 e2n3-1-worker.fbond
Such heavy utilization of the node can lead to many negative implications, for example:
https://www.ibm.com/support/pages/node/6098818
3)
Running:
oc get po --no-headers --all-namespaces -o wide| grep -Ev '([[:digit:]])/\1.*R' | grep -v 'Completed'
shows pods in ImagePullBackOff/ErrImagePull state like:

Resolving The Problem
We are still working to complete resolve this issue in our repository, currently the best solution is to update the ImagePullPolicy of zen-core deployment from IfNotPresent to Always.
oc patch deploy zen-core -n zen -p '{"spec": {"template": {"spec":{"containers":[{"name": "zen-core-container", "imagePullPolicy":"Always"}]}}}}'
2)
To even the distribution, and reduce the workload on the workers, please consider the following steps:
a) Modify following parameters on each master node /etc/origin/master/yosemite-appmgnt-scheduler.json
MasterLastPriority - weight: 20 SelectorSpreadPriority - weight: 10 LeastRequestedPriority - weight: 10 BalancedResourceAllocation - weight: 5 Zone - weight: 20
Run the following commands after changes on each master node:
master-restart api master-restart controllers
This should have positive impact on the default scheduler behavior (more balances workload distribution).
Please sum up all the pods on the workers (in our example: 125+44+55+49 = 273), then multiply it with 1.1 factor (for example: 273*1.1 = 300), finally divide it by the number of workers minus one (300/ (4-1) = 100). This number is just an estimation, if you are planning to add more services in the near future, you may want to increase it.
c) Modify the worker node config-map as per https://docs.openshift.com/container-platform/3.11/admin_guide/manage_nodes.html#modifying-nodes
oc edit cm node-config-compute-crio -n openshift-node
add the following entries under kubeletArguments (make sure indentations are correct):
max-pods: - "<result of step b>" kube-reserved: - "cpu=500m,memory=512Mi" system-reserved: - "cpu=500m,memory=512Mi"
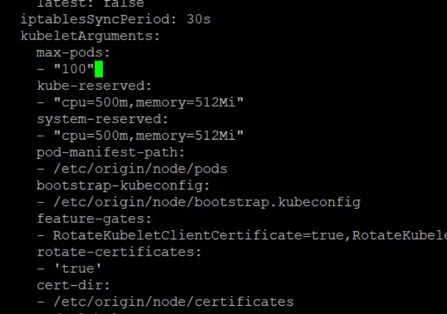
Upon this action, you should see many pods in OutOfpods state being migrated to less busy worker nodes.

3)
Run the following script to update the images with valid tags:
for node in $(oc get nodes | awk '/ Ready/ {print $1}' ) do echo $node ssh $node podman tag registry.access.redhat.com/openshift3/ose-deployer:v3.11.154 registry.redhat.io/openshift3/ose-deployer:v3.11 ssh $node podman tag registry.access.redhat.com/openshift3/ose-control-plane:v3.11.154 registry.access.redhat.com/openshift3/ose-control-plane:v3.11 done
Document Location
Worldwide
Was this topic helpful?
Document Information
Modified date:
16 July 2023
UID
ibm16218910