White Papers
Abstract
Probabilistic matching measures the statistical likelihood that two records are the same. By rating the similarity of the two records, the probabilistic matching method is able to find non-obvious correlations between data; two records may belong to the same person even if their attribute values are not the same.
This differs from Deterministic matching uses a series of rules, like nested if statements, to run logical tests on the data sets and seek a clear Yes or No result (no Maybe).
This technical document reviews the process that MDM uses to perform this probabilistic matching.
Content
Master Data is the core demographic data about people, organizations, or products which is stored and shared across multiple systems to support critical business processes. Within IBM Initiate Master Data Service, this data is classified as:
1. Matching Data which is used by the Algorithm to search, match, and link records.
2. Payload Data which is not used by the Algorithm for matching or linking, and can't be used for searching.
The probabilistic matching algorithm is configured to focus on key data elements (matching data) and it is configured during go-live but if needed, it may be modified thereafter. In a regular database, there maybe be hundreds or thousands of attributes associated with a member but very few will be matching data (say 10 attributes). The generally used matching data attribute for a person includes name, address, social security, phone number, birth date etc.
When we compare, search, match or link, these 10 or so attributes are used and the rest are ignored. Theoretically you may define as many attributes as matching data as needed, but adding more attributes may not result in much more accurate matching and can slow down the system significantly due to the additional required processing.
The Algorithm:
Algorithm defines the core logic for matching and searching. It sends data through a series of three steps, which break the data down, organizes the records, and compare data for overall match. These three steps are listed below:
Standardization: Re-structures data for consistency(does not alter data displayed). It converts data to simplest form for more efficient utilization during matching process.
Bucketing: Organizes records with similar data into an index for faster retrieval during searches.
Comparison: Defines the method for comparing data to assess the level of match. It compares pairs of records using the probabilistic method to calculate a score.
The algorithm is defined in the 'Algorithms' tab of the configuration pane in workbench and the following screen shot demonstrates the set-up for person legal name:
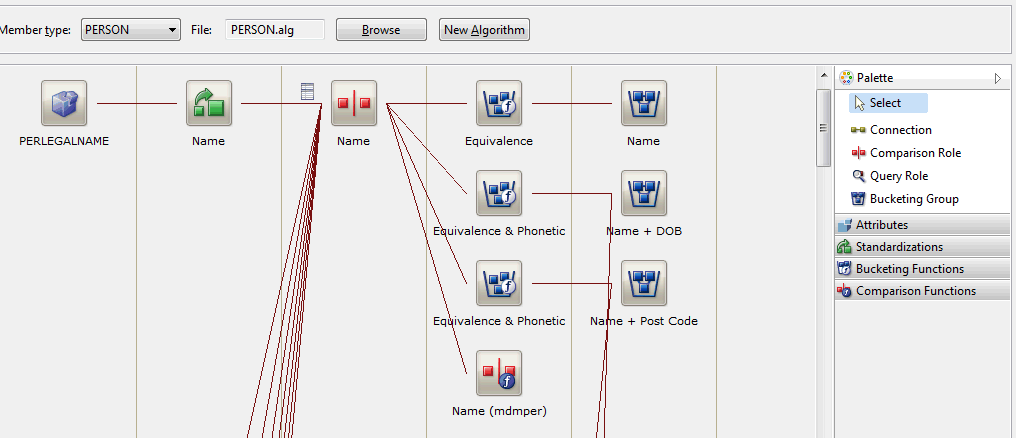
For discussion, let's use the following simpler use case:

The Attributes row merely tells us which attribute we are using; attributes added here are the ones referred previously as Matching Data.
Standardization:
The second column is for standardization and here we specify how the data is pulled from the attribute, formatted for more efficient comparison, and stored in the MEMCMPD table according to the role number. Standardization provides a wide array of of functions and some of the use cases include:
- Case Conversion: Converts Karen Jones to JONES:KAREN
- Truncation of Values: Converts (312) 832-1212 to 8321212
- Anonymous Values: Removes Phones with (000) 000-0000
- Validating Data Length: Rejects SSNs that do not have 9 digits
- Validating Data Format: Rejects e-mail addresses without an @ sign
- Nickname/Equivalency Translation: Converts values like Apartment to APT, West to W
We bundle certain in built functions with the workbench to accomplish this processing and a typical set-up looks like the following (PXNM is the standardization function here):

Standardized data is stored in the cmpval field of the mpi_memcmpd table and the stored data has the following characteristics:
- Attributes are delimited by carats “^”
- Tokens within the attributes are delimited by colons “:”
- ‘OR’ is indicated by a tilde “~”
- Strings must be less than 256 characters in length. If there are more than 256 characters, a second line in is created
Following are some examples of the standardized strings (mpi_memcmpd table) for the following fields: LastName, FirstName, MidInitial, Suffix, SSN, Gender, ZipCode, StreetLine1, HomePhone, MobilePhone, EyeColor:

Along with performance, one of the benefits of standardization is that the following addresses will be identical after standardization and hence we will have better matching results:
1. 208 West Chicago Apt. #3, Oak Park, IL 60302
2. 208 W. Chicago Ave. Apartment 3, Oak Park, IL 60302
3. 208 Wst. Chicago, Apt. 3, Oak Park, IL 60302
4. #3 – 208 W Chicago Avenue, Oak Park, IL 60302
Bucketing:
The bucket function pulls data from MEMCMPD table, transforms it according to the bucketing function design (As Is, Sorted, YYYYMM, Equivalence & Phonetic), then sends data to the bucketing group, which creates the actual buckets. The standardized string is fed into the bucketing function and based on the chosen function, it is processed, and combined with other strings to get a final string. The bucket value goes through a 64 bit hash function and saved into the mpi_memktd table along with the memrecno. Following is an example of how one such bucket is set up with Equivalence & Phonetic bucketing function:

The main purpose of buckets is to improve the performance during searches and during entity management. Since we are doing probabilistic matching, so theoretically we need to compare each search criteria and member undergoing entity management process to every other member in the database. Standardizing, comparing, generating scores, and then picking the highest scoring ones would be a time consuming process when it is spread across hundreds of millions of members. So instead, we create buckets from the search criteria or members undergoing entity management, and compare them against only those members which share a common buckets. So instead of doing hundreds of millions of comparisons, we only do a few hundred/thousand. The rationale being that if members don't even share a single bucket, then they will not score high upon comparison and so we can leave them out. But we cast a wide net by comparing each member which shares a common bucket so as to get stable and reliable results.
The database (membktd table) store a hash value and not the actual bucket value because number comparisons are faster than string comparisons. It should be noted that there is no way to reverse engineer the bucket value from the bucket hash. Since bucket value and role are not stored in the database, therefore they can not be retrieved using Java code or SQLs. The output for mpimshow and some analytic queries in the workbench do contain bucket values and bucket roles but they are not pulled from the database. Rather, we get them by re-deriving the member data on the fly. The application looks up member data, standardizes it, generates bucket information (including bucket value and bucket role), and finally a bucket hash. All this is done in real time and displayed as part of the output. SQLs and standard code like memget or memsearch do not re-derive member data and hence we can not get certain bucketing information from them. To run the mpimshow utility, go to the MAD_ROOTDIR\bin directory, load environment variables like MAD_ROOTDIR, MAD_HOMEDIR, MAD_CTXLIB, and use the following syntax to run it: mpimshow <entity type> <memrecno>. You may dump the output to a file: mpimshow EntityId MemberData -html > c:\temp\mpimshow\MemberData.html.
Here are some of the examples of bucket values and corresponding hashes for the following combination:
NAME: Alec Speegle SSN: 780-54-7291 DOB: 1982-05-02 ZIP: 85038 PH: (312) 271-6291

The bucket value may contain a single token e.g. a single date for a date of birth or it may be multi-token. Ccertain attributes like name (first, middle, last name, suffix, and prefix) or address (apartment, street, city, state, etc) tend to have multiple tokens in the bucket value. Similarly if we bucket multiple attributes together (like Name + DOB), then they will have multiple tokens. The number of buckets can grow if we keep all possible combinations slowing down run time processing and so we have the option to define how many to use:
Maximum Tokens: Defines the total number of tokens that can be used simultaneously
Minimum Tokens: Defines the minimum number of tokens required to generate a bucket
The system dynamically creates each unique permutation of tokens Max/Min settings exist at the Bucket Function and Bucket Group levels.
Following are some of the available bucket functions:

Comparison:
After the data has been standardized and the comparison string has been formed, the actual comparison process is performed. The comparison process uses a defined set of comparison functions and results in a cumulative score being returned for each candidate that indicates the probability of being the same member. The cumulative score returned for each record represents a comparison of that record against the trigger record. (A trigger record, or trigger member, is the record which initiated the interaction and against which the software compares the other candidates.) Scores can be positive or negative; the higher the score to the positive side, the more likely the records represent the same member.
The comparison function queries through MEMBKTD to locate a list of candidates to consider for matching. The MEMCMPD entries for those candidates are them compared and a score is issued for each record. During entity management (say after a memput interaction), the following scenarios are possible depending upon the comparison score generated:
- Members are linked (scoring above auto-link threshold)
- A task is created (scoring between auto-link and clerical review thresholds)
- No action is taken (scoring below clerical review, thus are likely not the same member)
The auto-link and clerical review thresholds are set in workbench under the Threshold tab as shown below:

Following are the types of tasks which may be created:
1. Potential Duplicate task
When two or more records from the same source have a comparison score above the clerical review threshold and below the auto-link threshold, the engine joins them into a Potential Duplicate task. These can also be created when same source linking is disabled but they score above the auto link threshold.
2. Potential Linkage task
When two or more records have a comparison score above the clerical review threshold and below the auto-link threshold, and the records are from different sources, the engine joins them into a Potential Linkage task.
3. Potential Overlay task
The engine detects overlays by comparing updated demographic data associated with a single Source ID. However, if data elements—such as name, Social Security number and phone—are completely different, the engine flags these records as Potential Overlays.
4. Review Identifier task
The engine detects unique identifiers by comparing records and tracking duplication of these identifiers, such as Social Security number.
There are several forms of comparisons:
- Exact Match: Do the two values match, Yes or No?
- Starts With: Do the two values start with the same initial or digits?
- Edit Distance: How many edits does it take to make the values match?
- Phonetics: Do the values have the same key sound markers?
- Equivalency: Could one of the values be a nickname or alias?
These techniques are bundled into a set of functions that blend approaches
- Name (comprehensive): Approach uses all five methods, best match wins
- Address & Phone: Uses all methods for address, but edit distance for phone
- Date: Approach blends exact match and edit distance
During comparison, we use edit distance widely as a measure of similarity between two strings by counting the number of edits needed to make the strings match. There are four kinds of edits:
- Transposition: Two adjacent characters that are swapped (STEIN vs. STIEN)
- Insertion: Need to add another character (MARGRET vs. MARGARET)
- Deletion: Need to remove and extra character (662071 vs. 66271)
- Replacement: Swap out a character with another one (GORDON vs. GORTON)

After matching all available attributes, each one is scored individually, and then a final score is calculated by adding all the individual scores. It is important to note that all matches are not scored equally. In US, 'John Smith' is a very common name and so having a match on John Smith does not inspire as much confidence that it is the same person as a match on 'Manteshwar Sidhu' would. Therefore a match on the less frequent names within your database would yield a higher score.
We use a concept of weights which represent the hub’s confidence that a single value can uniquely identify a record (highly unique data has a high score). Weights are calculated based on their data and algorithm. Weights are stored in database tables – when data is compared, the scores are pulled. Following are the tables where weights are stored:

The structure and working of these tables can get complicated and you may refer to the information center for details on how they work. These weights are not generated by default and we have to do it manually. The most common way of generating weights is through the 'Generate Weights' job in the workbench. Following are the steps associated with weight generation:

Since these weights are not dynamic but a snap shot in time, so we need to regenerate them on a regular basis. Following are some of the scenarios which should trigger weight regeneration:
- If you have added or changed comparison function or comparison code in your Algorithm
- When your population has grown by more than 20% of the original population
- After a sufficient amount of time has passed since you last calculated weights, say 2 years.
- When you have added a new source, especially one that comes from a different geographical area (the East Coast has different name, phone and address distributions than the West Coast)
- When you are upgrading to a new version
Once you regenerate the weights, your current existing data may no longer be in keeping with the new weights. Therefore we need to run Bulk cross match (BXM) to compare member records in binary on the file system. There are three components to a BXM for a transitive linking entity:
1. Compare Members in Bulk (mpxcomp): pulls matched records and scores them
2. Link Entities (mpxlink): checks scores against thresholds to create entities or tasks
3. Load UNLs to DB (madunlload): Loads the entities and tasks into the database
Transitive entities operate on the “glue member” concept in that a record only must match one other record in the entity set. For example, if Member A and Member B match and Member B and Member C match, it is assumed that Member A and Member C match. This match can be achieved by comparing above the auto-link threshold or by manual linking. But we also have non-transitive or "strong" entities require all records match above the auto-link threshold with all other records in the entity set. As with transitive, members of a non-transitive or strong entity can only belong to one entity set at a time (one Enterprise ID). The steps for running BXM for non-transitive linking are:
1. mpxcomp
2. mpxlink with "Generate BXM output" and "Generate entBktd information for non-transitive enties" options and -noentlink, noentxeia selected.
3. mpxcomp
4. mpxsort
5. mpxlink without "Generate BXM output" and "Generate entBktd information for non-transitive enties" options selected
Flow:
When we run a search, the specified attribute values are standardized and then the corresponding buckets are generated depending on the bucketing function specified in the algorithm. When the buckets are generated, they go through the hash function to create the corresponding bucket hash. The system looks up the distinct memrecno which share any bucket hash with the search criteria. As a final step, the system would compare the search criteria against all the distinct member records returned earlier and generate a score (using weights) for each member. Then it sends back the results in the descending order of the scores generated.
Similarly whenever we modify a member using member level interactions such as memput, memupdate, etc, entity management is triggered which utilizes probabilistic matching. The attribute values we use for the interaction, say memput, are standardized, subsequent buckets created, a list of members sharing a bucket generated and then the members compared. If any of the members score above the auto-link threshold, then this new member will join the existing entity of the members. If it scores between clerical review and auto-link threshold, a task would be generated with the nature of the task dependent on additional factors discussed earlier. Other-wise if none of the members score higher than clerical review, a new entity would be persisted for that member.
For memupdate, a special scenario exists where the member was part of an entity but it's comparison score is low now. In this case an overlay task would be created to highlight this inconsistency.
We can draw a couple of insights from this architecture:
1. If an attribute does not have any associated buckets, then it can not be searched against and will not be considered for entity management.
2. The greater the number of buckets, the more comparisons are needed and therefore more CPU intensive and slower it is.
Following are some of the techniques for buckets for performance optimization:
1. Tweaking bucket design by combining multiple tokens.
2. Disabling features like Sorted and Phonetic bucketing.
3. Add frequently used values to the anonymous list (mpi_anon) so that buckets for these values are not created or considered when they values are encountered.
4. Running Frequency Based Bucketing to disable large buckets and only have buckets with fewer than a given number of members. As a general rule, we recommend not having any buckets with more than 2000 members because the more frequent a bucket, the lower the generated score, and to be a match, we will need additional shared buckets. The following technical note covers frequency based bucketing in greater detail: http://www-01.ibm.com/support/docview.wss?uid=swg21655423.
Probabilistic Match or Search:
Probabilistic matching/search is a technology that relies on statistical theory to provide highly accurate matching results and is well adapted for searching data with inconsistently populated fields, or data that has not been cleansed or standardized. Three key phases from a performance perspective:
1. Candidate selection using a wide search in the suspect pool to locate potential matches followed by a retrieval of normalized comparison strings and return to application host.
2. Cross match fields and composite a score for each candidate representing the statistical probability of a match. Typical comparisons involve exact, nickname, name-to-initial matches, frequency-based comparisons, typographical errors and phonetic equivalencies.
3. Attribute retrieval of requested rows from the production database corresponding to the fields requested for all matches during the search.

Features of Candidate Selection (Database IO Intensive):
* Selection process used to narrow the dataset population down to a candidate group.
* Select comparison strings for candidates. Can be time consuming if the candidate population is large.
* Read heavy phase against a narrow working set focused on: MPI_BKTD2, MPI_CMPD1, and MPI_CMPD.
* Heavy random row reads against narrow selection working set.
* Elevated latencies in this phase typically due to very large candidate populations – e.g. big buckets.
Features of Cross Matching and Scoring (CPU Intensive):
* Cross compare returned candidate strings at the application tier.
* CPU intensive, though this represents <5% of the total transaction duration.
* CPU intensive at the application tier for short bursts. Latency values are typically < 10 ms.
Features of Attribute Retrieval Step (Database IO Intensive):
* Time spent waiting on rows to be returned from the database depending on what data the service layer requested.
* Can be extremely IO intensive if the matched rate is high and the requestor pulls a large number of rows per member.
* Typically reads heavily against attribute tables.
* Heavy random reads against attribute tables. This is a wide working set focused on payload data.
* Elevated latencies are typically due to large numbers of attributes per match, with a large match population.
Product Synonym
MDS;Master Data Service;MDM;MDM SE;MDMSE;Master Data Management;IBM Infosphere Master Data Service;MDM Standard Edition;MDM Hybrid Edition;Initiate;Hybrid;Physical MDM;Virtual MDM;Hybrid MDM;PME Engine;Big Match
Was this topic helpful?
Document Information
Modified date:
27 April 2022
UID
swg27043172