Question & Answer
Question
Overview of MQ and IIB High Availability Using a Hardware Load Balancer
Answer
On Demand Consulting
Author: Marilza Maia
IBM Integration Bus (IIB) High Availability (HA)
This paper defines a couple topology options for IBM Integration Bus (IIB) high availability and resiliency integration infrastructure using a hardware load balancer, MQ/JMS client and web services.
1 Levels of availability
Typically, a single integration server restart takes 1-2 minutes if it has 10-100 message flows in-flight at the time of a failure. An integration node could take 5-10 minutes to restart, also depending on the number of in-flight message flows. A whole system may take approximately 10-20 minutes to restart. Based on IIB availability requirements, workload, and estimated restart time you can determine your target availability. The table below lists six classes of "9s" and their correspondent percentage of uptime and downtime in hours.
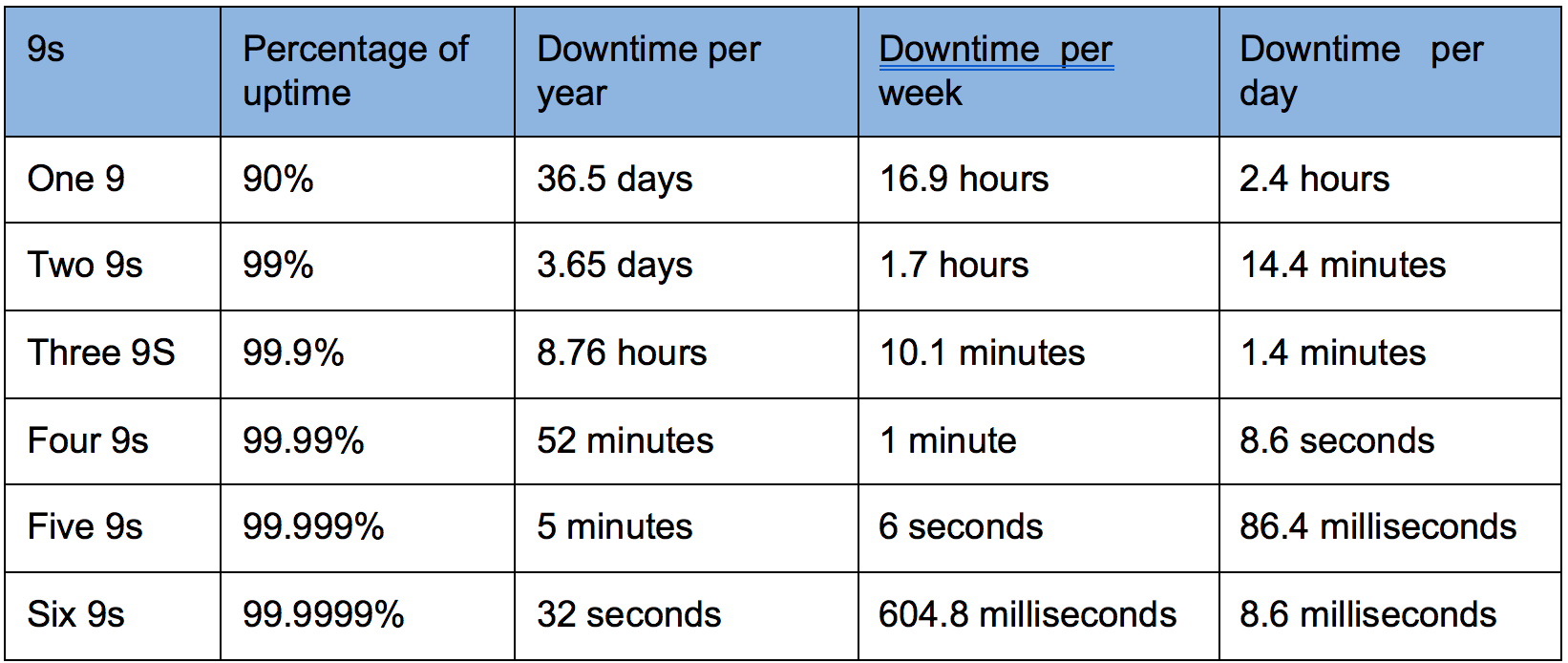
Table 1 - High Availability - Six classes using 9s notation
The highest the uptime percentage the more complex the HA configuration gets and the more product licenses is required.
2 High Availability (HA) Topology Options
Typically applications connect to IBM Integration Bus (IIB) using IBM MQ and standard JMS or web services (SOAP/HTTP). IIB HA topology described here is broken down into two different patterns:
ðØ Asynchronous
ðØ Synchronous
2.1 Asynchronous Pattern
The HA topology options for asynchronous application integration pattern are:
ð§ Active/Active using multi-instance queue manager multi-instance Integration Node and a queue manager gateway (when using MQ Cluster).
ð§ Active/Passive using multi-instance queue manager and multi-instance Integration Node.
Either one of the two patterns provide fully redundant instance of each node. Let's discuss each configuration approach:
2.1.1 Active/Active configuration with IIB and IBM MQ
Some customers like to use a hardware load balancer to balance the workload between two or more queue managers.
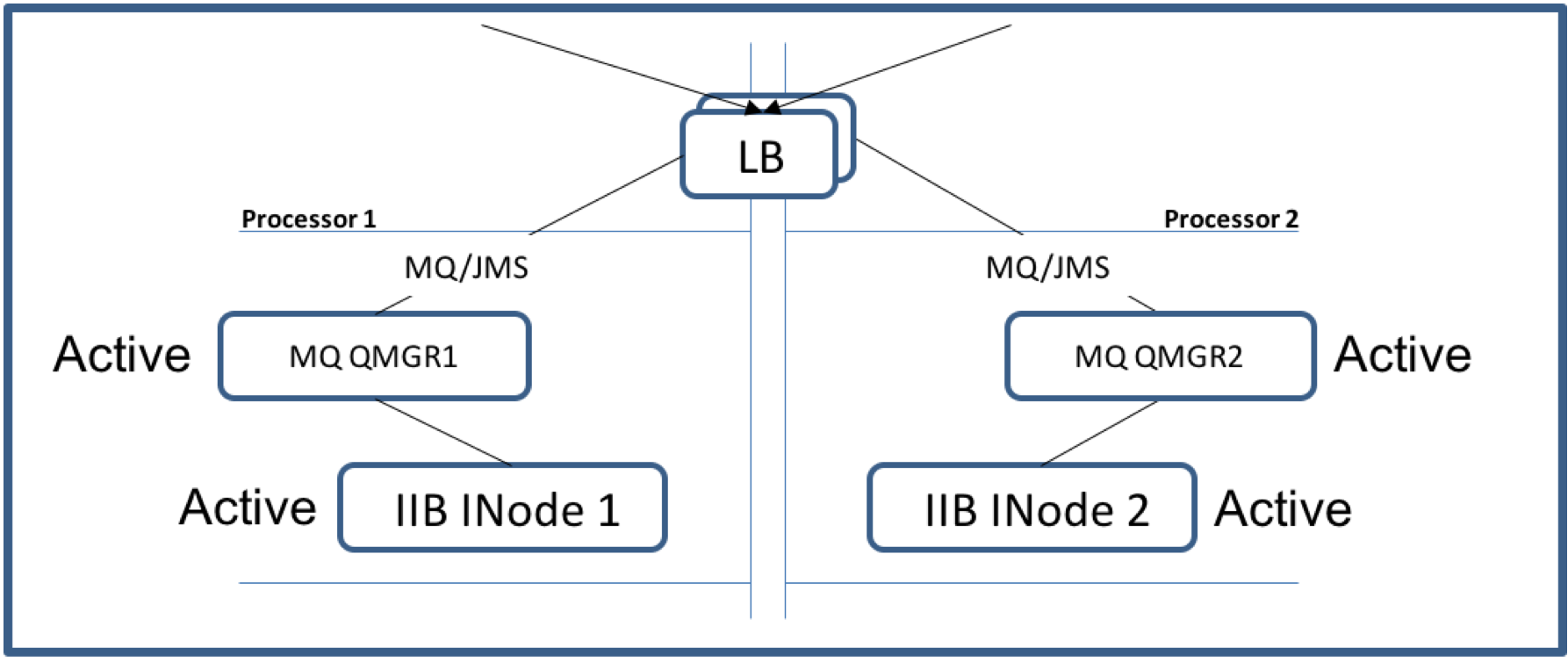
Figure 1 - IIB/MQ Active/Active HA Configuration
Unfortunately a hardware load balancer doesn't work with a Client MQ JMS. Here's why:
When connecting to a queue manager via a hardware Load Balancer using the MQ classes for JMS you will get unexpected results as a JMS Connection and
JMS Session may not be routed to the same queue manager.
When defining the Connection Factory with transport=client and channel as a server connection (SVRCONN) the transport between the application and the queue
manager is TCP/IP. The MQ JMS high level transport contract consists of a JMS Connection JMS Session and a JMS Put/Get. Because the MQ JMS Connection
and Session use different TCP sockets the load balancer can potentially route each request to a different queue manager.
The MQ code has to check and report an error if the session isn't connected to the same queue manager as its original Connection.
The reliable way to implement an asynchronous Active/Active HA configuration is to use a queue manager gateway with MQ cluster.
2.1.2 Active/Passive configuration with IIB and IBM MQ
This is how an asynchronous MQ HA should be configured. Typically IIB/MQ HA Active/Passive configuration uses multi-instance Queue Manager and Multi-Instance
Integration Node. That is a queue manager and integration node start active in a processor while a standby queue manager and Integration node are started as
standby in a different processor. See figure below - IIB/MQ Active/Passive HA Configuration. The active and standby queue managers share the same queue manager
data and logs so that when a failure of the active queue manager occurs the standby queue manager will take over and the load balancer will automatically route the
messaging traffic to the failed over queue manager.
Author: Marilza Maia
IBM Integration Bus (IIB) High Availability (HA)
This paper defines a couple topology options for IBM Integration Bus (IIB) high availability and resiliency integration infrastructure using a hardware load balancer, MQ/JMS client and web services.
1 Levels of availability
Typically, a single integration server restart takes 1-2 minutes if it has 10-100 message flows in-flight at the time of a failure. An integration node could take 5-10 minutes to restart, also depending on the number of in-flight message flows. A whole system may take approximately 10-20 minutes to restart. Based on IIB availability requirements, workload, and estimated restart time you can determine your target availability. The table below lists six classes of "9s" and their correspondent percentage of uptime and downtime in hours.
Table 1 - High Availability - Six classes using 9s notation
The highest the uptime percentage the more complex the HA configuration gets and the more product licenses is required.
2 High Availability (HA) Topology Options
Typically applications connect to IBM Integration Bus (IIB) using IBM MQ and standard JMS or web services (SOAP/HTTP). IIB HA topology described here is broken down into two different patterns:
ðØ Asynchronous
ðØ Synchronous
2.1 Asynchronous Pattern
The HA topology options for asynchronous application integration pattern are:
ð§ Active/Active using multi-instance queue manager multi-instance Integration Node and a queue manager gateway (when using MQ Cluster).
ð§ Active/Passive using multi-instance queue manager and multi-instance Integration Node.
Either one of the two patterns provide fully redundant instance of each node. Let's discuss each configuration approach:
2.1.1 Active/Active configuration with IIB and IBM MQ
Some customers like to use a hardware load balancer to balance the workload between two or more queue managers.
Figure 1 - IIB/MQ Active/Active HA Configuration
Unfortunately a hardware load balancer doesn't work with a Client MQ JMS. Here's why:
When connecting to a queue manager via a hardware Load Balancer using the MQ classes for JMS you will get unexpected results as a JMS Connection and
JMS Session may not be routed to the same queue manager.
When defining the Connection Factory with transport=client and channel as a server connection (SVRCONN) the transport between the application and the queue
manager is TCP/IP. The MQ JMS high level transport contract consists of a JMS Connection JMS Session and a JMS Put/Get. Because the MQ JMS Connection
and Session use different TCP sockets the load balancer can potentially route each request to a different queue manager.
The MQ code has to check and report an error if the session isn't connected to the same queue manager as its original Connection.
The reliable way to implement an asynchronous Active/Active HA configuration is to use a queue manager gateway with MQ cluster.
2.1.2 Active/Passive configuration with IIB and IBM MQ
This is how an asynchronous MQ HA should be configured. Typically IIB/MQ HA Active/Passive configuration uses multi-instance Queue Manager and Multi-Instance
Integration Node. That is a queue manager and integration node start active in a processor while a standby queue manager and Integration node are started as
standby in a different processor. See figure below - IIB/MQ Active/Passive HA Configuration. The active and standby queue managers share the same queue manager
data and logs so that when a failure of the active queue manager occurs the standby queue manager will take over and the load balancer will automatically route the
messaging traffic to the failed over queue manager.
- In the Unix OS the recommendation is to only copy /var/mqsi/registry and /var/mqsi/components to the shared file system. Do not copy everything from /var/mqsi directory though. The two processors need to be identical for the Active/Passive HA topology to work properly including ODBC configuration and SSL.
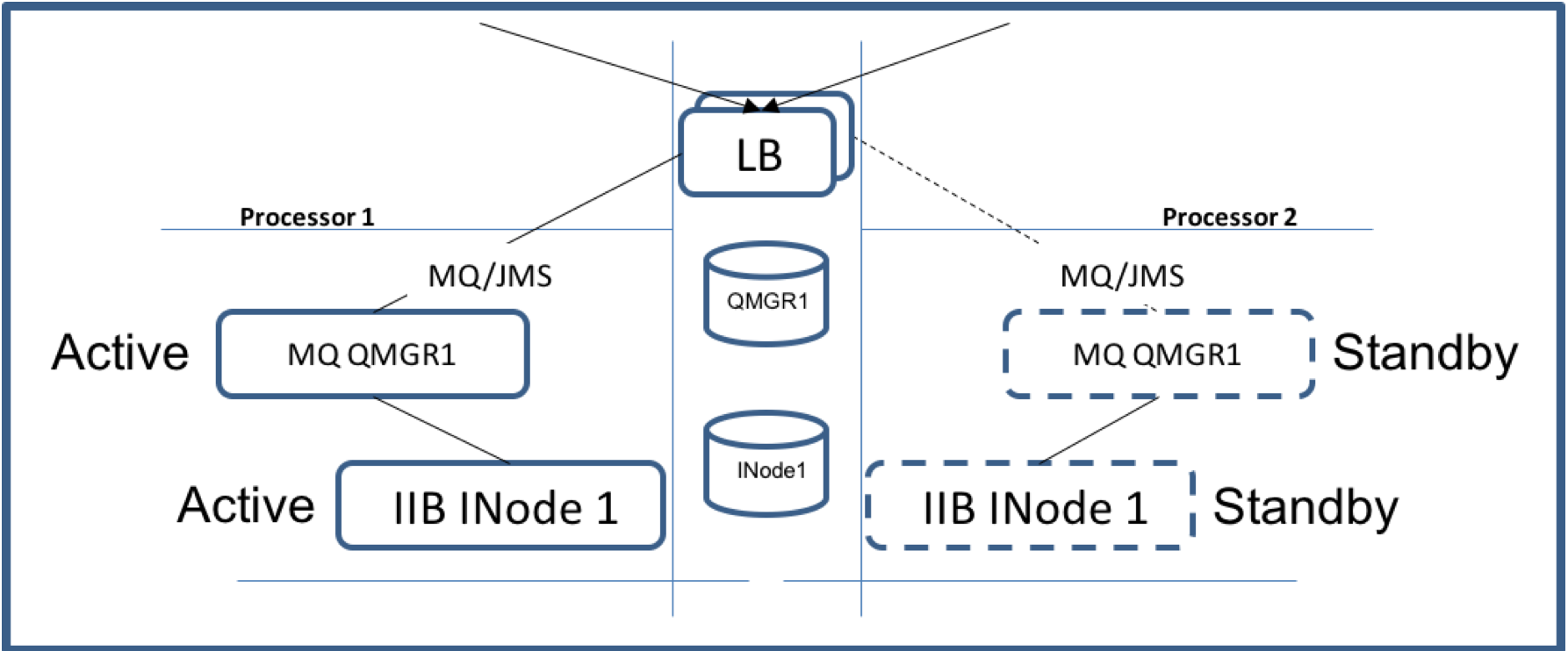
Figure 2 - IIB/MQ Active/Passive HA Configuration
IBM Integration Bus is designed to work well with multi-instance queue managers. Ideally you should make the Integration Node a queue-manager service so that
MQ will automatically start IIB integration node after a failure. Here's what happens after a failure:
The standby queue manager is ready to take over as soon as a failure of the active queue manager is detected. The active and standby (Passive) components often
exchange heartbeat information. If a specific number of heartbeats are missed the standby components take over as active components.
In an Active/Passive configuration where the IIB broker is configured as a queue-manager service the integration components queue manager and integration node
failover as a unit. The Integration Node and its Integration Servers as well as the MQ Messaging runtime (queue manager) failover together.
Once an integration component failover takes place the standby components becomes active. The load balancer should route the new traffic to the standby queue manager.
Client applications are automatically reconnected to the standby queue manager. If the application is not automatically reconnected verify that the DefReconn (MQRCN_YES) is
set up in the MQClient.ini file. Automatic reconnection can be enabled administratively using the "DefReconn" parameter of the channels stanza MQClient.ini by defining DefReconn (MQRCN_YES).
There is no automatic fail-back to the original machine after the problem that caused the failover is resolved. The failed queue manager and integration node must be
manually restarted after a failure. If there is a need to make the original machine retake control the current active queue manager must be manually stopped. In summary
any time the state of a queue manager needs to be changed from standby to active the current active queue manager must be manually stopped or crashed due to some
sort of unplanned failure.
2.1.3 Testing the HA Active/Passive Configuration
Test the Failover process without the applications to validate the configuration. Use the MQ HA sample programs to test the failover process. For more information
see the IBM MQ High Availability sample programs in the following link:
http://www.ibm.com/support/knowledgecenter/SSFKSJ_9.0.0/com.ibm.mq.dev.doc/q024200_.htm
From a command prompt type the following:
SET MQSERVER=connectionName/TCP/VIP(Port #)
In the same DOS window run the MQ sample application amqsphac queuename qmgrname to put messages into a "test" queue.
In a different DOS window Set MQSERVER then run amqsghac queuename qmgrname to get the messages from a "test" queue.
While the sample programs amqsphac and amqsghac are running simulate the missing heartbeat by stopping the active queue manager and observing
the results of a failover.
Here's what should happen once the active queue manager is stopped:
- In IBM Integration Bus the whole Integration Node fails over as a unit. All Integration Servers owned by that Integration Node as well as the MQ Messaging runtime (queue manager) will failover together.
- Ensure that all components queue manager and Integration node switch to the standby processor.
- Ensure that the Load Balancer (LB) routes the new traffic to the standby queue manager.
Once you're satisfied with the failover test return to the queue manager that originally failed. Observe the fail back results by ensuring that no messages
were lost during any take over and that the applications are always reconnected when an automatic switch takes place from one physical machine to another.
You can also use the IH3 support pack to test your HA configuration:
Download IH3 from http://www-01.ibm.com/support/docview.wss?uid=swg24000637
IH3 requires that the data portion of a message be entered into a file. The file may contain one or more messages. If multiple messages are added in the file a
delimiter needs to be added to separate the messages. IH3 reads the message(s) from the file and writes them into a queue. See the sample file below.
The file contains three messages separated by "#@" delimiter.
Start rfhutilc.exe to get the GUI shown below. Click on the down arrow of the Queue Manager box to get the server connection information then enter the queue
name and click on the "Load Q" button.
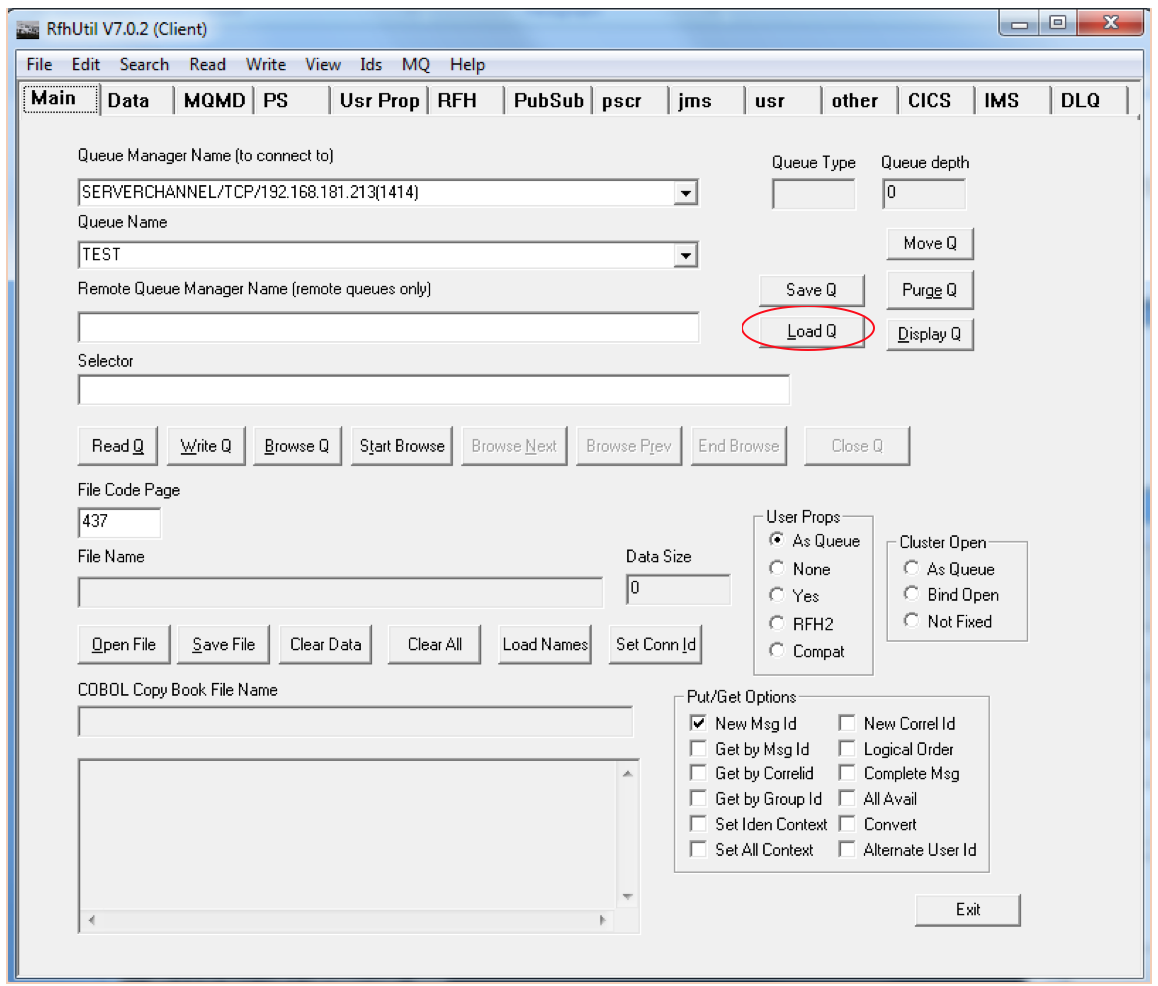
When clicking on the Load Q button the follow window is rendered:
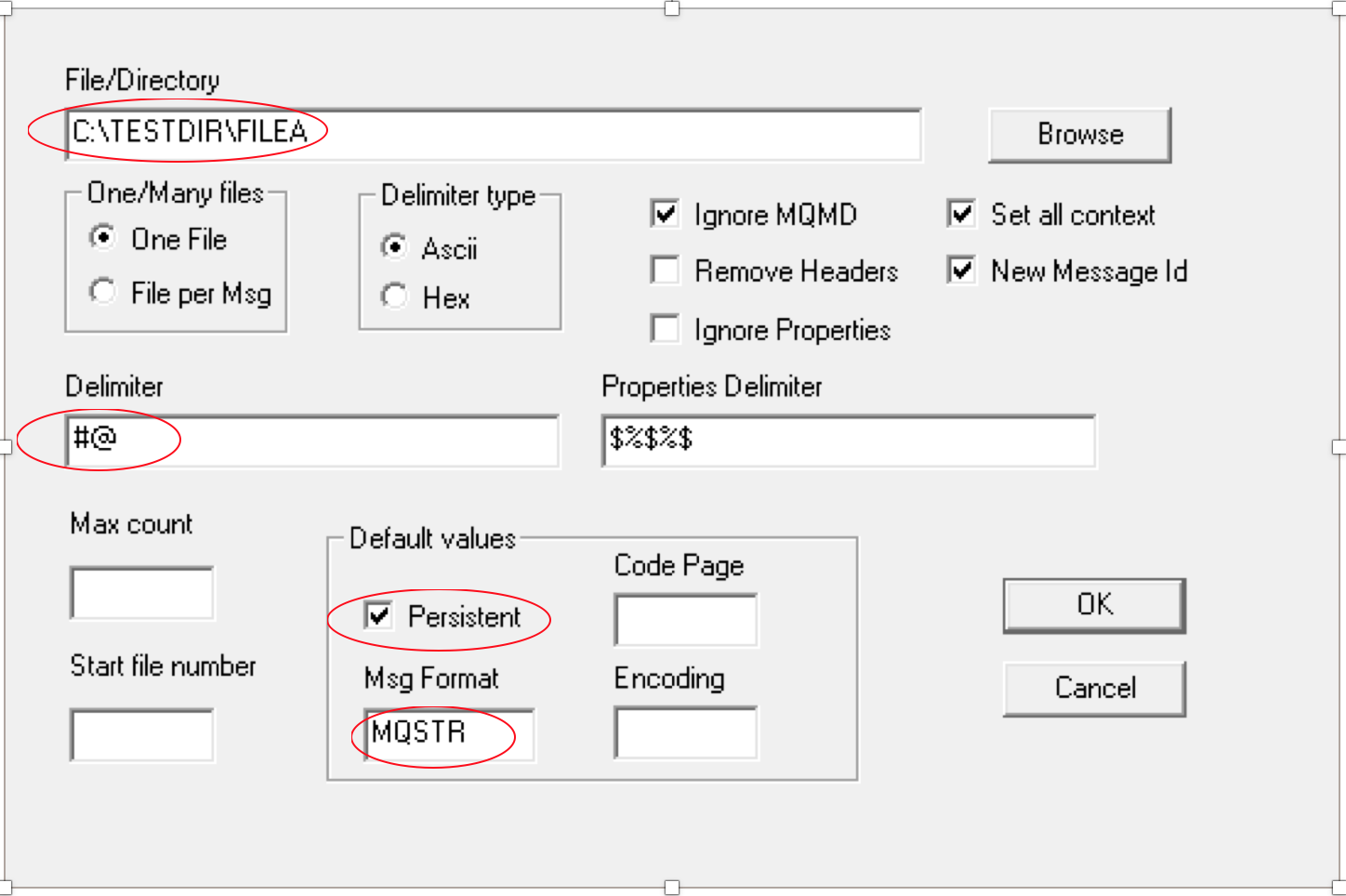
Provide the File/Directory name delimiter default values and click "OK". The messages in the file will be put into the specified queue. The appropriated message flow will retrieve the messages from the queue and process them.
2.2 Synchronous Integration Pattern
The HA topology options for synchronous application integration pattern are:
ð§ Active/Active using multi-instance Integration Node.
ð§ Active/Passive using multi-instance Integration Node.
2.2.1 Active/Active configuration using multi-instance Integration Node
Active/Active HA topology is very straightforward where a workload balancer distributes requests across multiple active systems.
When using an Active/Active configuration in a synchronous mode new requests can be serviced immediately after a planned or unplanned
outage as there should always be an active instance of an integration component available. This is often called continuous availability.
See figure below - IIB Active/Active HA Configuration.
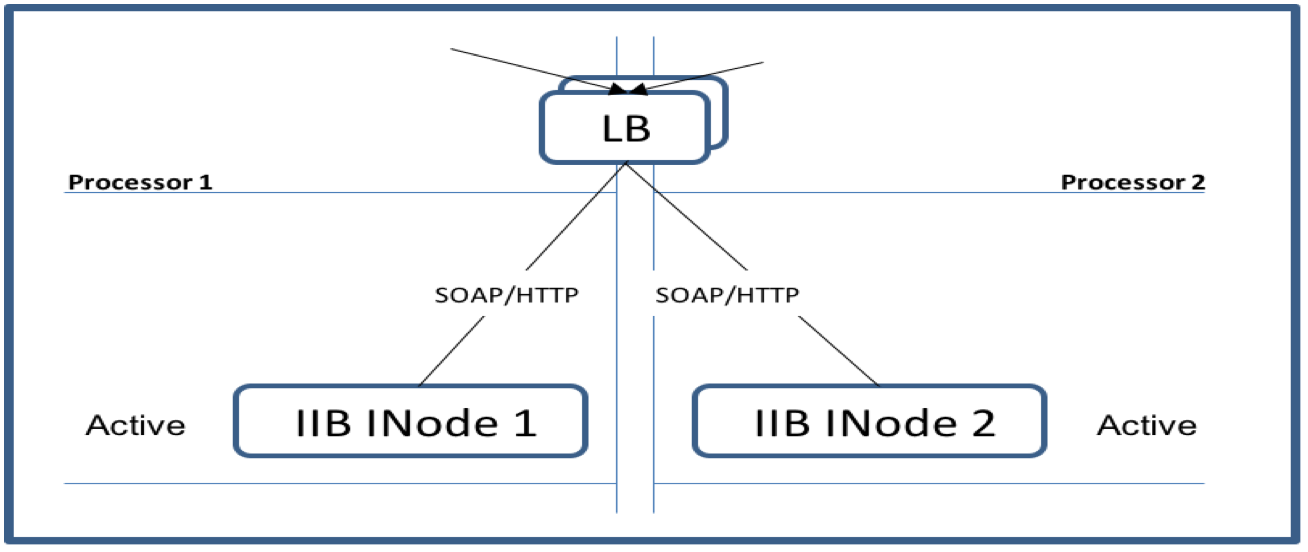
Figure 3 - IIB Active/Active HA Synchronous Configuration
Keep in mind that the failure of an integration node may cause non-persistent data to be lost so that the failed transaction might need to be re-executed.
Applications should be aware of failure and have the appropriated exception handling in place to resubmit the failed request. The application
can resubmit the failed request immediately as the network load balancer will send the resubmitted request to the health environment.
A synchronous request-reply pattern involves services that respond over the same network socket on which the request was received. The consumer
application maintains the network socket open while the request is being processed. When the request process is completed the response is sent over
through the same network socket. It's important to be aware that the consumer application may timeout especially when the provider accesses a database.
When Accessing a database ensure that there are no locking happening and the database is well designed with effective indexes.
The SOAPRequest node provides a "Request Timeout" property with a default of 120 seconds. If no response is received in this time a SOAP Fault
exception is raised and propagated to the Failure terminal.
The synchronous application integration pattern was designed for synchronous inbound requests using web services (SOAP/HTTP). Each instance of the
integration node must be able to operate independently without relying on the availability of any other instance in the environment. The order in which two
concurrent requests are processed cannot be guaranteed as there are multiple instances that might process each request.
In order to maintain a high degree of high availability it's important to make the data accessible by all servers and that a single server has enough capacity to handle the additional workload after a failure.
[{"Business Unit":{"code":"BU053","label":"Cloud & Data Platform"},"Product":{"code":"SSQTW3","label":"IBM On Demand Consulting for Hybrid Cloud"},"Component":"","Platform":[{"code":"PF025","label":"Platform Independent"}],"Version":"All Versions","Edition":"","Line of Business":{"code":"","label":""}}]
Was this topic helpful?
Document Information
Modified date:
05 March 2019
UID
ibm10771807