How To
Summary
Db2 LUW (DB2 for Linux, UNIX and Windows) を初めてご利用される方に、Db2運用の基本的な概念をご理解いただけるよう執筆された記事です。
ご利用のDb2バージョンに依存しない内容となっています。入門、初心者向けの読み物としてご活用いただければ幸いです。
こちらの記事では、基本のモニタリングと応用編に分けて Db2 のモニタリング手法について解説します。
Objective
なぜモニタリングが必要なのか
IT システムにおけるモニタリングとは、システムの状態を管理者が把握できるようにするための、「見える化」を目的としたタスクです。いったんシステムの状態を見える化した後には、判明した情報を元にしてキャパシティ計画を立てたり、稼働レポートをまとめたりといったアクションに移ります。そのため一口にモニ タリングと言っても、稼働監視や性能情報の収集、問題判別のためのリアルタイムのモニターなど、目的とするアクションによって具体的な内容は多岐にわたり ます。
この記事は Db2 を使ったデータベースの運用設計をする読者を対象としているため、「Db2 運用管理の概要編」の記事で紹介したように、運用の一要素として設計する稼働監視及び性能情報を中心としたデータベース稼働情報の収集について解説します。
下記の図に、代表的な Db2 のモニタリング項目を稼働監視と稼働情報の収集という 2 つのグループに分けてまとめています。前述したように、モニタリングとはシステムの状態を把握するためのデータの収集なので、収集する対象はどこまでも細かくすることができます。数多くあるモニタリング項目を列挙して紹介するだけでは、読者の方が「自分はどこまでやるべきか」を把握することが難しいため、この記事では「必ずやるべき基本のモニタリング」と、「重要なシステムに対してやるべき、一歩進んだモニタリング」の 2 段階に分けて紹介します。
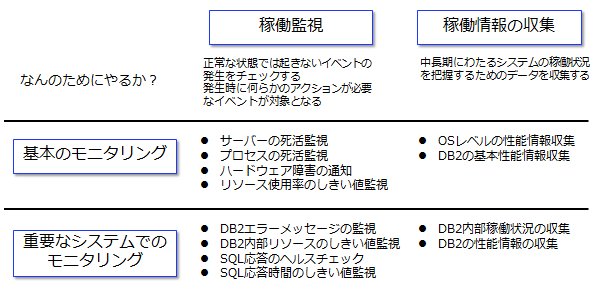
基本のモニタリング どんなデータベースでもここまではやろう
基本のモニタリングには、「Db2 を使っている時には、どんなシステムであっても必ず行うべき項目」を挙げています。これらの項目を必須のモニタリング対象としているのは、商用のデータベースである Db2 を採用いただいているシステムでは、データベースの停止や停止に直結するリソースの不足を迅速に検知し、基本的な性能情報を把握できるようにすることが必要と考えるためです。
そのため、基本のモニタリングが目的とするのは以下の 3 点です。
- データベースサーバーや Db2 プロセスの停止が即座に検知できること
- Db2 の稼働に致命的な影響を与えるリソース不足の兆候を事前に警告できること
- ハードウェア・リソースの使用状況や Db2 の処理状況についての基本的なレポートが作成できる情報を収集すること
それでは、ここから基本のモニタリングの具体的な項目について説明していきます。なお、OS やハードウェアの監視方法については、インターネット上で豊富な情報が提供されているため、この記事では監視項目として言及する程度に留めています。
基本の稼働監視
サーバーの死活監視
サーバーの死活監視は、ネットワーク上の稼働監視と言い換えることもできます。ICMP プロトコルを利用して一定間隔での応答チェックを行い、未応答が続いた場合にはサーバーの障害として通知する方式が一般的です。
通常は、サーバーの死活監視の方法はシステム全体で共通に定めます。そのため、データベースサーバーも全体の方針に従うことになります。そのような全体の方針がない場合の、シンプルなサーバー死活監視の方法は、PING コマンドによるチェックです。データベースサーバーに対して一定間隔で PING コマンドを実行し、未応答が続いた場合に通知するような仕組みを、シェルスクリプトや WSH (Windows Script Host) を利用して作成します。
プロセスの死活監視
Db2 の起動中は、サーバー上の常駐プロセスとして db2sysc という名前のプロセスが立ち上がります。プロセスの死活監視では、このプロセスをスクリプトや監視ソフトを利用して監視します。
Db2 には db2sysc 以外のプロセスもありますが、プロセス監視の対象として登録するのは Db2 のエンジンである db2sysc プロセス (Windows の場合は db2sysc.exe) のみで問題ありません。プロセス名の末尾には数字がついており、一般的なシングルノード構成の Db2 インスタンスでは下の実行例のように 0 固定です。
$ ps -ef | grep db2sysc
db2inst1 14483550 6488162 0 Sep 26 - 9:27 db2sysc 0
Data Partitioning Feature (DPF) 構成や pureScale 構成など、複数の db2sysc プロセスが連携して動作する分散クラスター環境では、db2sysc プロセスの数に応じて数字が増加していきます。そのため、db2sysc プロセスが複数になり、末尾の数字が変わることを考慮に入れてプロセス監視を構成してください。
ハードウェア障害の通知
データベースサーバーを構成するハードウェアの障害を検知するための監視項目です。ハードウェアが対応する通知機能に応じて、Linux/Unix の Syslog や Windows のイベントログ等の OS が提供するログ機能もしくは、SNMP Trap を利用して構成します。OS が出力するエラーの通知も同様に行います。
リソース使用率のしきい値監視
この監視項目では、ハードウェア・リソースの使用率を監視し、一定の値を超えた場合に通知します。一般的に、CPU、メモリー (ページング) 、ディスク (ファイルシステム、ドライブ) の 3 つを対象とします。なお、CPU に関しては、使用率が高いこと自体はデータベースの稼働に影響を与えないため、しきい値監視から外すことも可能です。逆に、メモリー枯渇によるページング の頻発や、ディスク領域の不足は、データベースの稼働に重大な影響を及ぼすため、しきい値監視が必須です。
通知するしきい値の設定はリソースの量によって異なります。ディスク領域の使用率上昇については、状況の調査や拡張などの対応にある程度の時間を必要とするため、対応が間に合うように余裕を持ったしきい値を設定することをおすすめします。また、使用率が80%を越えた時点で「警告(Warning)」を、90%を越えた時点で「致命 (Critical) 」を通知するような、2 段階の警告レベルを設定すると、急激な増加を検知することが可能です。
表 1. リソース使用率の監視に利用できるコマンド/機能
| リソース | Linux/Unix の場合 | AIX の場合 | Windows の場合 |
|---|---|---|---|
| CPU | vmstat コマンド | vmstat コマンド | パフォーマンスモニター (警告機能) |
| メモリー (ページング使用率) | free コマンド | lsps -s コマンド | パフォーマンスモニター (警告機能) |
| ディスク | df コマンド | df コマンド | パフォーマンスモニター (警告機能) |
Db2 では、データやログ、診断データなどを複数のファイルシステムやドライブに分散して配置する設計が一般的です。そのため、Db2 の使用するディスク領域を監視するためには、どこにリソースが配置されているかを把握する必要があります。以下で、Db2 を使用している場合に監視すべき対象と、配置場所を確認する方法を説明します。
-
インスタンス・ホームディレクトリ : インスタンス管理ユーザーのホームディレクトリです。
-
診断データの出力パス : このパスには Db2 の出力する診断ログ (db2diag.log) や管理通知ログ、またダンプファイルなどが出力されます。デフォルトではインスタンス・ホームディレクトリの配下 (sqllib/db2dump) にセットされており、変更している場合は DIAGPATH データベース・マネージャー構成パラメーターで確認可能です。
% db2 get dbm cfg |grep DIAGPATHDIGA Diagnostic data directory path (DIAGPATH) = /db2/db2dump診断データの出力パスがいっぱいになっても、Db2 の稼動には影響を与えません。しかし、診断データが書けないと、Db2 の出力するメッセージやメモリーチューニングの結果など、Db2 の挙動を記録するログが出力されません。Db2 の過去の稼働状況を調査することが難しくなるため、出力先の使用率を監視することをおすすめします。
-
データベース内のオブジェクト : 表スペースやアクティブログ、アーカイブログなどデータベースごとに管理しているディスク資源の配置場所は、SYSIBMADM.DBPATHS 管理ビューから取得できます。SQL を実行すると下の例のような出力が戻されるので、ファイルシステムやドライブなど、容量を管理する単位にあわせて監視対象に追加してください。

% db2 "select dbpartitionnum, substr(type,1,20) as type, substr(path,1,80) path from sysibmadm.dbpaths" DBPARTITIONNUM TYPE PATH -------------- -------------------- ---------------------------------------------------- 0 LOGPATH /dbdata/actlog1/NODE0000/ 0 MIRRORLOGPATH /dbdata/actlog2/NODE0000/ 0 DB_STORAGE_PATH /dbdata/db2inst1/ 0 LOCAL_DB_DIRECTORY /dbdata/db2inst1/db2inst1/NODE0000/sqldbdir/ 0 DBPATH /dbdata/db2inst1/db2inst1/NODE0000/SQL00003/ 5 record(s) selected.
基本の稼働情報収集
OS レベルの性能情報を収集する
OS レベルの性能情報を収集することは、モニタリングの第一歩です。キャパシティ計画や性能問題が発生したときの調査資料など、システムの活動の履歴を調べるために必須の情報なので、必ず収集し蓄積するようにしてください。
Linux/Unix プラットフォームであれば、nmon を利用したパフォーマンスデータの収集をおすすめします。nmon は OS のパフォーマンスデータを一括して収集できる非常に便利なモニターツールで、出力ファイルをグラフ化するためのツール (nmon analyzer) と共にフリーで配布されています。最近の AIX であれば OS に同梱されていますし、Linux の場合はフリーで配布されているモジュールを導入して使用できます。ツールの配布場所や、作成できるレポートの詳細については nmon と nmon analyzer の紹介ページを参照してください。
nmon を利用して性能情報を収集するためには、定期的に実行されるように cron に登録するのが一般的です。たとえば、下の例のように 300 秒間隔で 288 回分のパフォーマンスデータを収集するオプションで実行すると、実行開始時刻を含むファイル名に対して、1 日分の性能情報を出力してくれます。
# nmon -F nmon.$(date "+%Y%m%d_%H%M%S").out -s 300 -c 288
# ls -l nmon*out
-rw-r--r-- 1 root system 173604 Oct 1 19:26 nmon.20141001_192620.out
Windows プラットフォームの場合は、Windows が「パフォーマンス モニター」という強力なモニターツールを提供しています。コントロールパネルの「管理ツール」からパフォーマンス モニターを起動し、データコレクターセットを作成することでパフォーマンスデータを収集することが可能です。スケジュール機能もパフォーマンス モニターが提供しますので、スクリプトを作成する必要もありません。
Db2 の基本性能情報を収集する
データベースとしての基本的な性能情報を把握しておくことも、OS レベルの性能情報収集と同じぐらい重要です。Db2 の性能情報を収集することで、たとえば「過去 1 ヶ月間で SQL の投入レートがどれぐらい変動したか」とか、「前日の正午頃にスローダウンが発生したが、Db2 の応答時間はボトルネックになっていなかったか」といった質問に答えられるようになります。
ここでは、基本のモニタリングとして、あまり手間をかけずに必要な情報を収集することを重視するため、分析済みのレポートを Db2 から取得できる monreport モジュールを使う方法を紹介します。monreport モジュールは Db2 9.7 から提供されている機能で、モニター表関数やスナップショットなど、Db2 が提供する複数のモニター機能を駆使してユーザーが読みやすいテキスト形式のレポートを出力してくれます。
表 2 に、Db2 の基本性能情報として取得をおすすめするコマンドをまとめました。これらのコマンドを定期的に実行して、出力結果をファイルに蓄積するようにしてください。取得する間隔は、「調査の時にどれぐらいの粒度 (間隔) でデータベースの活動を把握したいか」によって変わってきます。通常は 1 時間間隔で取得することが多く、もっと小さな粒度でデータベースの状態を捉えたい場合は 5 分から 10 分間隔でもよいでしょう。
表 2. Db2 の基本性能情報を収集するために使うコマンド
| コマンド | レポートする対象 | 備考 |
|---|---|---|
| MONREPORT.DBSUMMARY | データベース全体の活動サマリー | コマンドで指定した時間 (秒) のアクティビティを収集してレポートする。そのため、例えば 60 秒分の活動サマリー収集を指定すると、コマンドは 60 秒間実行中になる。 |
| MONREPORT.PKGCACHE | 過去の一定時間に実行された、負荷の高い SQL の性能情報 | パッケージ・キャッシュに残っているパッケージが収集対象となる。 |
| MON_PKG_CACHE_SUMMARY | パッケージ・キャッシュに残っている SQL 実行情報のサマリー | MONREPORT.PKGCACHE の詳細版 |
どうやって monreport の性能情報を取得するか:
ここでは、monreport を利用する場合の実行方法を紹介します。紹介するサンプルでは、Db2 に同梱のシェルスクリプトで利用される ksh (korn shell) の文法を使用しているので、使用するスクリプト言語の文法に合わせて調整してください。Db2 が導入された Linux/Unix 環境には必ず ksh も導入されているので、ksh 文法のまま実行することができます。
以下に、2 つの monreport モジュールを 1 時間間隔で 24 回実行し、1 日分のモニタリングを行うスクリプトの例を示しています。monreport はレポートを標準出力に表示するため、出力内容をファイルにリダイレクトしています。ループ処理の中に sleep コマンドを入れていませんが、monreport.dbsummary コマンドが 3600 秒間 (1 時間) 実行され続けるので、実質的に sleep が入っているのと同様に、1 時間間隔でレポートが取得されます。
このサンプルでの設定のまま実行すると、monreport のレポートごとに 1 時間間隔のモニター結果が 24 ファイルずつ作成されます。1 時間間隔ではインターバルが長すぎる場合は、10 分間隔で 144 回のループに変更するなど、モニタリングの要件に合わせて調整してください。
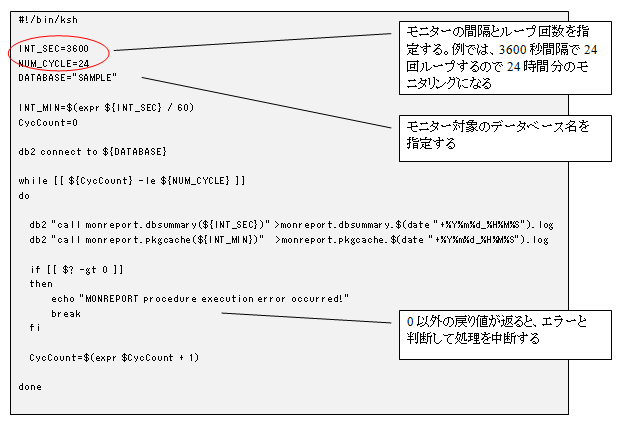
#!/bin/ksh
INT_SEC=3600
NUM_CYCLE=24
DATABASE="SAMPLE"
INT_MIN=$(expr ${INT_SEC} / 60)
CycCount=0
db2 connect to ${DATABASE}
while [[ ${CycCount} -le ${NUM_CYCLE} ]]
do
db2 "call monreport.dbsummary(${INT_SEC})" >monreport.dbsummary.$(date "+%Y%m%d_%H%M%S").log
db2 "call monreport.pkgcache(${INT_MIN})" >monreport.pkgcache.$(date "+%Y%m%d_%H%M%S").log
if [[ $? -gt 0 ]]
then
echo "MONREPORT procedure execution error occurred!"
break
fi
CycCount=$(expr $CycCount + 1)
done
monreport.dbsummary ではデータベース活動の全体サマリーが取得できる:
monreport.dbsummary はコマンドが投入されると指定された秒数の間、実行中のまま待機します。待機状態の間にデータベースの活動情報を収集し、その間にデータベースが行ったすべての活動のサマリー情報を出力します。下の例では引数として 3600 を指定しているため、3600 秒間 (1 時間) 待機した後、1 時間分の活動サマリーを出力します。
以下の例のように、レポートの冒頭にはデータベースが行った処理の量がサマリーされます。処理の量を表す単位には TOTAL_APP_COMMITS (コミット数=トランザクション数) 、ACT_COMPLETED_TOTAL (完了した SQL 数) 、APP_RQSTS_COMPLETED_TOTAL (完了したリクエスト数) の 3 つがあります。最後のリクエスト数とは、SQL の結果セットを取得するためのカーソルのオープンや、カーソルからのレコード取得 (フェッチ) など、SQL によるデータアクセスを行うために必要な様々な活動がカウントされた数字です。リクエスト回数は、軽量な SQL では少なく、重い SQL では多くなる傾向があるため、処理の重みを加味した処理量を把握するために利用します。
また、データベース全体のボトルネックの判別に非常に有用なのが、「Detailed breakdown of TOTAL_WAIT_TIME」セクションです。このセクションには、情報を収集した期間にデータベース内部のどこで処理が待ち状態になったかをサマ リーしてくれます。下に抜粋した「Detailed breakdown of TOTAL_WAIT_TIME」を見ていくと、「I/O wait time」に属する時間の割合が高くなっている一方で、ロックやネットワークでの待ちはゼロに近い割合です。ここから、Db2 の内部ではディスク I/O に多くの時間を費やしていることを知ることができます。

% db2 "call monreport.dbsummary(3600)"
...
Work volume and throughput
-------------------------------------------------------------------------
Per second Total
--------------------- ----------------
TOTAL_APP_COMMITS 11 119
ACT_COMPLETED_TOTAL 46 468
APP_RQSTS_COMPLETED_TOTAL 151 1516
TOTAL_CPU_TIME = 1488669
TOTAL_CPU_TIME per request = 981
...
-- Detailed breakdown of TOTAL_WAIT_TIME --
% Total
--- -------------
TOTAL_WAIT_TIME 100 1505277
I/O wait time
POOL_READ_TIME 24 368527
POOL_WRITE_TIME 0 13565
DIRECT_READ_TIME 8 130118
DIRECT_WRITE_TIME 10 163923
LOG_DISK_WAIT_TIME 10 154734
LOCK_WAIT_TIME 0 62
AGENT_WAIT_TIME 0 0
...
monreport.pkgcache では負荷の高い SQL トップ 10 の情報が取得できる:
monreport.pkgcache は、負荷の高い SQL のトップ 10 をレポートするコマンドです。
Db2 の SQL キャッシュであるパッケージ・キャッシュから、直近の指定された期間 (分) に実行された SQL の中で、いくつかの観点から負荷の高い SQL のトップ 10 を出力します。デフォルト値は 60 (分) なので、引数なしで実行すると「過去 1 時間に実行された SQL の中から負荷の高いトップ 10 の SQL」をリストします。
「負荷が高い」と判断する基準には「使用した CPU 時間」、「Db2 内部での待ち時間」、「処理した行数」などがあります。SQL を調査するときに確認する主な視点が網羅されている上に、非常にわかりやすくまとめられているため、「遅い SQL があるのではないか」と疑ったときに最初に確認する資料として優れています。後述するように、このレポートだけでは足りない情報もありますが、「SQL 単位でのより詳細な調査をするべきかどうか」を数分で判断することができるため、その目的のためだけでも取得する価値があります。
下の例では、引数として 60 (分) を指定しているので、「過去 60 分間に実行された SQL のトップ 10」が出力されています。レポートの一部を抜粋して、TOTAL_CPU_TIME と TOTAL_ACT_WAIT_TIME の部分を取り出しています。これは、SQL 処理のために使用された CPU 時間のトータルと、SQL 処理のために Db2 内部で待った時間のトータルを意味しています。
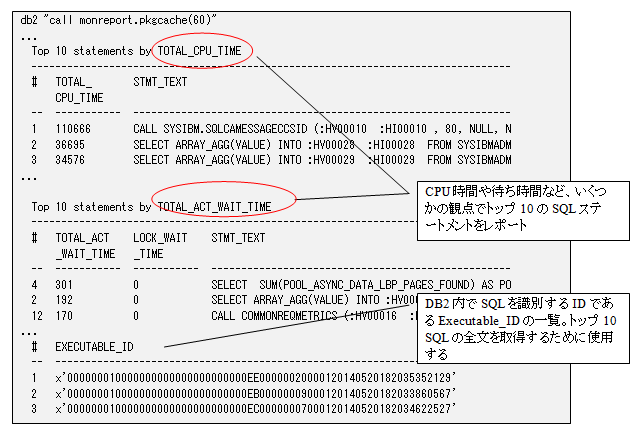
db2 "call monreport.pkgcache(60)"
...
Top 10 statements by TOTAL_CPU_TIME
--------------------------------------------------------------------------------
# TOTAL_ STMT_TEXT
CPU_TIME
-- ----------- ---------------------------------------------------------------
1 110666 CALL SYSIBM.SQLCAMESSAGECCSID (:HV00010 :HI00010 , 80, NULL, N
2 36695 SELECT ARRAY_AGG(VALUE) INTO :HV00028 :HI00028 FROM SYSIBMADM
3 34576 SELECT ARRAY_AGG(VALUE) INTO :HV00029 :HI00029 FROM SYSIBMADM
...
Top 10 statements by TOTAL_ACT_WAIT_TIME
--------------------------------------------------------------------------------
# TOTAL_ACT LOCK_WAIT STMT_TEXT
_WAIT_TIME _TIME
-- ----------- ----------- --------------------------------------------------
4 301 0 SELECT SUM(POOL_ASYNC_DATA_LBP_PAGES_FOUND) AS PO
2 192 0 SELECT ARRAY_AGG(VALUE) INTO :HV00028 :HI00028 F
12 170 0 CALL COMMONREQMETRICS (:HV00016 :HI00016 , :HV000
...
# EXECUTABLE_ID
-- ----------------------------------------------------------------------------
1 x'000000010000000000000000000000EE00000020000120140520182035352129'
2 x'000000010000000000000000000000EB00000009000120140520182033860567'
3 x'000000010000000000000000000000EC00000007000120140520182034622527'
...
ちなみに、この出力例を見るとわかるように、このレポートでは一覧性を優先しているために SQL ステートメントの全体ではなく先頭部分だけが抜粋された形で出力されます。そのため、このレポートだけで遅い SQL ステートメントの全文を知ることはできません。レポートの末尾にある EXECUTABLE_ID が、SQL ステートメントを判別するための ID 情報なので、この ID を元に MON_PKG_CACHE_SUMMARY の取得結果を参照してください。
MON_PKG_CACHE_SUMMARY には、SQL ごとの実行時間や CPU 使用時間など、より詳細な項目が SQL ステートメントの全文とともに出力されます。収集するためのスクリプトのサンプルを以下に添付します。

#!/bin/ksh
INT_SEC=3600
NUM_CYCLE=24
DATABASE="SAMPLE"
INTERVAL=tpcc
CycCount=0
MON_PKG_CACHE_SUMMARY="select CURRENT TIMESTAMP AS TIMESTAMP, SECTION_TYPE, HEX(EXECUTABLE_ID), NUM_COORD_EXEC, NUM_COORD_EXEC_WITH_METRICS, TOTAL_STMT_EXEC_TIME, AVG_STMT_EXEC_TIME, TOTAL_CPU_TIME, AVG_CPU_TIME, TOTAL_LOCK_WAIT_TIME, AVG_LOCK_WAIT_TIME, TOTAL_IO_WAIT_TIME, AVG_IO_WAIT_TIME, PREP_TIME, ROWS_READ_PER_ROWS_RETURNED, AVG_ACT_WAIT_TIME, AVG_LOCK_ESCALS, AVG_RECLAIM_WAIT_TIME, AVG_SPACEMAPPAGE_RECLAIM_WAIT_TIME, STMT_TEXT from sysibmadm.mon_pkg_cache_summary order by TOTAL_STMT_EXEC_TIME desc fetch first 1000 rows only"
EXPORT_TMP="/tmp/mon_get_tmp.$$"
db2 connect to ${DATABASE}
while [[ ${CycCount} -le ${NUM_CYCLE} ]]
do
OUTFILE="sysibmadm.mon_pkg_cache_summary.$(date "+%Y%m%d_%H%M%S").csv"
db2 "describe ${MONITOR_SQL}" |awk '/^ -+.*-$/{while(getline){COLs=COLs","$4}};END{print substr(COLs, 2, length(COLs)-2)}' >${OUTFILE}
db2 -v "export to ${EXPORT_TMP} of del
modified by timestampformat=\"YYYY-MM-DD HH:MM:SS.UUUUUU\" ${MON_PKG_CACHE_SUMMARY}"
if [[ $? -gt 2 ]]
then
echo "Monitor SQL execution error occurred!"
break
fi
cat ${EXPORT_TMP} >>${OUTFILE}
rm -f ${EXPORT_TMP}
CycCount=$(expr $CycCount + 1)
sleep ${INT_SEC}
done
一歩進んだモニタリング 重要なデータベースではこれもやろう
ここでは、基本のモニタリングに加えて、もう一歩進んだ詳細なモニタリングのテクニックについて紹介します。企業の基幹業務に使用されるシステムや、顧客から直接利用されるシステムでは、データベースに不測の事態が発生した際の影響もより大きくなります。そのため、ここで紹介するモニタリング項目を取り込み、データベースの活動状況をよりきめ細かに捉えることをおすすめします。
重要なデータベースで実施するモニター項目の候補は、「なぜモニタリングが必要なのか」にある図に示したように多岐にわたります。例えば、性能を維持することが極めて重要なデータベースでは、リアルタイムで応答時間を監視するようなモニタリングを実装することもあります。この記事では、重要なデータベースに対して実施することの多い、Db2 内部のエラーメッセージ監視と、より詳細な性能情報の収集について詳しく紹介していきます。
Db2 エラーメッセージの監視
メッセージの監視方法は環境によって様々なので、ここでは「どのようなメッセージを監視すべきか」に絞って解説します。利用している監視ソリューションに応じて、メッセージを運用担当者に通知するための方法を検討してください。
Db2 のエラーメッセージ監視は、Db2 の内部で発生した様々なイベントの中から、サービスの継続に大きな影響を及ぼすイベントをいち早く通知するために行います。基本の稼動監視で対象にしていた Db2 の外側から判断できる障害に加えて、Db2 内部のステータス異常などのように、障害が顕在化する前の兆候を捉えることができるようになります。
Db2 が出力するメッセージファイルには、Db2 診断ログ (db2diag.log) と管理通知ログ (<インスタンス名>.nfy) の 2 種類があります。Db2 診断ログは Db2 の内部動作についての情報を含む詳細なログが出力されるファイルで、監視対象とするにはやや細かい情報が多く出力されます。そのため、メッセージ監視には 管理通知ログを利用してください。ファイルの出力先は Db2 のバージョンや稼働プラットフォームによって異なるため、「[Db2 LUW] Db2 診断ログ (db2diag.log) や管理通知ログの出力先 (IM-10-0AC)」を参照してください。
管理通知メッセージは ADM で始まるメッセージ体系となっています。下記図のように、末尾の文字でメッセージの重要度が表され、通常はクリティカル (C) とエラー (E) の 2 種類を監視対象とします。メッセージ ID をあらわす数字の部分は 4 桁と 5 桁の 2 種類があるので、固定長の文字列として監視対象に登録する場合に留意してください。ADM メッセージの一覧は Db2 マニュアルにまとめられています。

Db2 性能情報の収集 (モニター表関数)
基本のモニタリングでは、MONREPORT を活用した基本性能情報の収集方法を紹介しました。ここではそれに加えて、時系列での分析やボトルネックの深掘りに役立つ Db2 性能情報の収集方法を紹介します。
MONREPORT はユーザーから見てわかりやすい整形済みのレポートを出力するため、加工の手間がいらないモニター機能として手軽に利用できます。その一方で、わかりやすさを優先したサマリー形式になっているため、SQL 処理レートの時系列での推移を CSV 形式にまとめて表計算ソフトに取り込んだり、Db2 のコンポーネントごとの詳細な待ち時間を調査したりするような、加工や詳細な分析のインプットにするには不向きです。
そのような用途には、モニター表関数を利用するのが最適です。モニター表関数は、下記図のように SQL に組み込んで実行することで、SQL の結果セットとして Db2 の性能情報を返却します。EXPORT コマンドと組み合わせることで CSV 形式での出力も簡単にできるため、一定間隔で出力した結果を CSV 形式で蓄積することで、表計算ソフトなどで簡単に取り込みや加工ができるようになります。
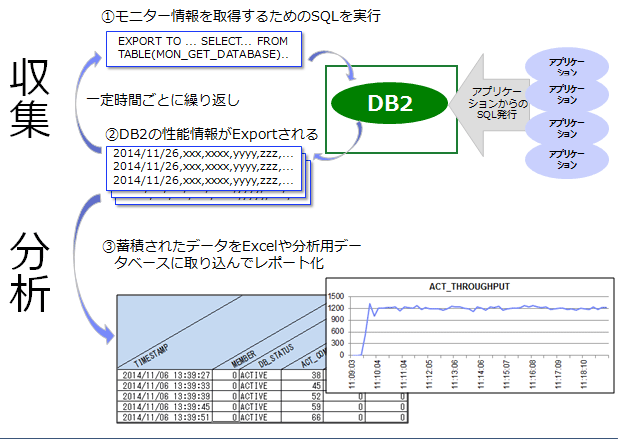
Db2 が提供するモニター表関数はどんどん拡張されており、最新版の Db2 10.5 では 30 以上の関数が存在します。その中から、Db2 のエキスパートがよくつかうモニター表関数を表 3 にまとめました。モニター表関数での性能情報収集を始める場合は、まずこれらの表関数を試してみてください。この中でも、 MON_GET_DATABASE はデータベース単位の詳細な稼働情報が収集できるため、ボトルネックの分析や稼働レポートの作成にとても有用です。
表 3 のコマンド例を見るとわかるように、任意の SQL を作成して実行するため、SQL の条件指定で収集するデータの絞り込みが簡単にできます。コマンド例ではすべての列を取得しているため、Db2 のコマンドプロンプトなどから SQL を実行すると、非常に横に長い出力が出てきてしまいます。そのため、後述するサンプルのように EXPORT コマンドによって CSV に出力し、表計算ソフトなどで閲覧するのがおすすめです。なお、SQL の性能情報である MON_GET_PKG_CACHE_STMT は、多くの種類の SQL が実行されているデータベースでは出力レコード数が非常に多くなることがあります。そのため、コマンド例ではトータルの SQL 実行時間 (TOTAL_ACT_TIME) が多い順に 1000 レコードまでの出力になるように制限しています。
表 3. 主なモニター表関数とコマンド例
| モニター表関数(取得間隔の例) | なにが取れるか | コマンド例 |
|---|---|---|
| MON_GET_DATABASE(5分間隔) | データベース全体の性能情報。ボトルネック調査のときは、まずこれを調べる。 | db2 "SELECT CURRENT TIMESTAMP as TIMESTAMP, t.* FROM TABLE(MON_GET_DATABASE(-2)) as t" |
| MON_GET_PKG_CACHE_STMT(1時間から1日に1回程度) | SQL 単位の性能情報。SQL 単位の性能を調査するときには必須の情報。 | db2 "SELECT CURRENT TIMESTAMP as TIMESTAMP, t.* FROM TABLE(MON_GET_PKG_CACHE_STMT(NULL, NULL, NULL, -2)) as t ORDER BY TOTAL_ACT_TIME DESC FETCH FIRST 1000 ROWS ONLY" |
| MON_GET_TABLE(1時間から1日に1回程度) | テーブルの使用状況情報 | db2 "SELECT CURRENT TIMESTAMP as TIMESTAMP, t.* FROM TABLE(MON_GET_TABLE(NULL, NULL, -2)) as t" |
| MON_GET_INDEX(1時間から1日に1回程度) | 索引の使用状況情報 | db2 "SELECT CURRENT TIMESTAMP as TIMESTAMP, t.* FROM TABLE(MON_GET_INDEX(NULL, NULL, -2)) as t" |
| MON_GET_CONNECTION(1時間から1日に1回程度) | DB 接続単位の性能情報。オンラインとバッチ処理など異なる性質のアプリケーションが混在する場合に有用。 | db2 "SELECT CURRENT TIMESTAMP as TIMESTAMP, t.* FROM TABLE(MON_GET_CONNECTION(NULL, -2)) as t |
それでは、モニター表関数の実行方法を具体的にイメージしてもらえるように、簡単なスクリプトによって一定間隔でモニター表関数 (MON_GET_DATABASE) を実行し、出力ファイルに追記していく処理のサンプルを紹介します。
このスクリプトでは、モニター対象のデータベースに接続した (スクリプト例の 14 行目) 後に、モニターSQL の列名を取得してログファイルのヘッダーとして利用しています (16 行目)。その後、3,4 行目で定義されたループ回数と取得インターバル (秒) の繰り返し処理に入り (18 行目) 、繰り返し処理の中でモニターSQL を使った EXPORT が実行されます (21 行目)。EXPORT が終わった後は、一時ファイルに出力した取得結果を本体のログファイルにマージしています (30 行目)。このマージ処理は、EXPORT コマンドには既存のファイルへの追記モードがないため、繰り返し処理で取得した結果を一つのファイルにまとめる必要があるためです。
MON_GET_DATABASE 以外のモニター表関数を収集したい場合は、8 行目のモニターSQL 定義を別の SQL に変更してください。表 3 のコマンド例で紹介した SQL がそのまま利用できます。
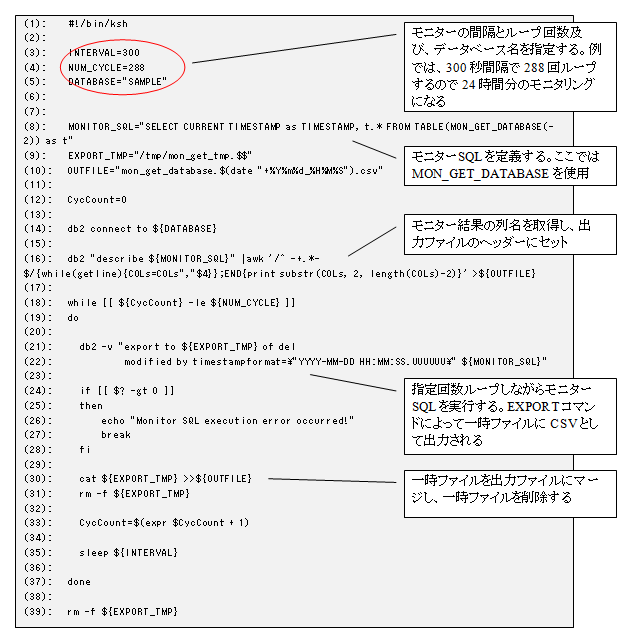
(1): #!/bin/ksh
(2):
(3): INTERVAL=300
(4): NUM_CYCLE=288
(5): DATABASE="SAMPLE"
(6):
(7):
(8): MONITOR_SQL="SELECT CURRENT TIMESTAMP as TIMESTAMP, t.* FROM TABLE(MON_GET_DATABASE(-2)) as t"
(9): EXPORT_TMP="/tmp/mon_get_tmp.$$"
(10): OUTFILE="mon_get_database.$(date "+%Y%m%d_%H%M%S").csv"
(11):
(12): CycCount=0
(13):
(14): db2 connect to ${DATABASE}
(15):
(16): db2 "describe ${MONITOR_SQL}" |awk '/^ -+.*-$/{while(getline){COLs=COLs","$4}};END{print substr(COLs, 2, length(COLs)-2)}' >${OUTFILE}
(17):
(18): while [[ ${CycCount} -le ${NUM_CYCLE} ]]
(19): do
(20):
(21): db2 -v "export to ${EXPORT_TMP} of del
(22): modified by timestampformat=\"YYYY-MM-DD HH:MM:SS.UUUUUU\" ${MONITOR_SQL}"
(23):
(24): if [[ $? -gt 0 ]]
(25): then
(26): echo "Monitor SQL execution error occurred!"
(27): break
(28): fi
(29):
(30): cat ${EXPORT_TMP} >>${OUTFILE}
(31): rm -f ${EXPORT_TMP}
(32):
(33): CycCount=$(expr $CycCount + 1)
(34):
(35): sleep ${INTERVAL}
(36):
(37): done
(38):
(39): rm -f ${EXPORT_TMP}
このスクリプトを実行すると、カレントディレクトリに以下のような CSV が出力されます。MON_GET_DATABASE はデータベース全体の性能情報を出力するため、1 回あたり 1 レコードが出力されます。左端の列が取得タイムスタンプなので、10 分間隔で 6 回にわたって 1 時間分のモニター結果が取れていることがわかります。フォーマットが CSV 形式なので、このまま表計算ソフトなどに取り込むことが可能です。
TIMESTAMP,MEMBER,DB_STATUS,DB_ACTIVATION_STATE,DB_CONN_TIME,CATALOG_PARTITION,LA...
"2014-11-06 13:30:00.129096",0,"ACTIVE","IMPLICIT","2014-11-05 15:03:10.000000",...
"2014-11-06 13:40:00.201587",0,"ACTIVE","IMPLICIT","2014-11-05 15:03:10.000000",...
"2014-11-06 13:50:00.292828",0,"ACTIVE","IMPLICIT","2014-11-05 15:03:10.000000",...
"2014-11-06 14:00:00.369289",0,"ACTIVE","IMPLICIT","2014-11-05 15:03:10.000000",...
"2014-11-06 14:10:00.442493",0,"ACTIVE","IMPLICIT","2014-11-05 15:03:10.000000",...
"2014-11-06 14:20:00.442493",0,"ACTIVE","IMPLICIT","2014-11-05 15:03:10.000000",...
モニター表関数は時系列での分析に利用するため、基本のモニタリング で紹介した MONREPORT よりは短い時間間隔で集めるのが効果的です。MON_GET_DATABASE の場合は 5 分間隔程度を、その他のモニター表関数は 1 時間から 1 日に 1 回程度をスタート地点として検討してください。
取得した Db2 性能情報を分析する
前節では、モニター表関数を利用した Db2 の性能情報を取得する方法を紹介しました。ここでは、取得した性能情報を分析するときに役立つ着眼点を紹介します。
SQL の処理レートと平均応答時間を把握する:
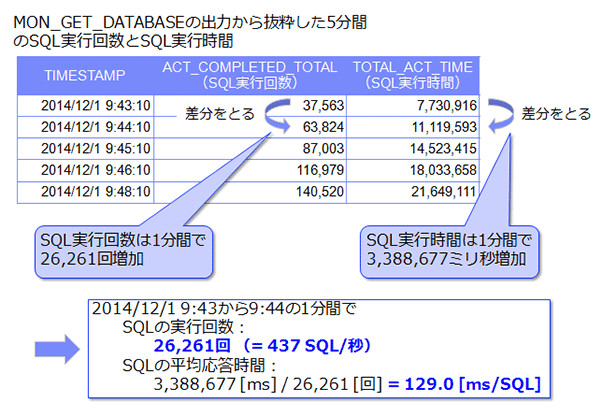
SQL の処理レートと平均応答時間は、データベース管理者が最初にチェックすべき項目です。「データベースが遅いのではないか」という疑問を持ったときには、 SQL の平均応答時間がどのように推移したかを把握することで、客観的な指標をもとに判断することができます。Db2 の場合は、完了した SQL の総数を表す ACT_COMPLETED_TOTAL と、SQL の処理時間を表す TOTAL_ACT_TIME を利用して計算します。どちらの項目も、MON_GET_DATABASE の出力に含まれます。
モニター表関数から取得したモニター結果は「データベースを活動化した時点からの累積値」なので、ある時間帯の処理状況を把握するためにはモニター 結果の差分をとる必要があります。下記の図は、1 分間隔で取得した MON_GET_DATABASE の取得結果から SQL 実行回数及びトータルの SQL 実行時間を取り出し、SQL の平均応答時間を計算する例です。実際に分析する際は、表計算ソフトなどを利用して複数のモニター期間にわたる推移を算出します。
また、個々の SQL ごとの応答時間を把握したい場合は、基本のモニタリングで紹介した SQL ごとに主な性能指標が取得できる MON_PKG_CACHE_SUMMARY が利用できます。SQL の実行回数としては NUM_COORD_EXEC を、その SQL の平均応答時間としては AVG_STMT_EXEC_TIME を使用してください。
Db2 内部での主要な待ち時間を分析する:
SQL の平均応答時間が予想よりも大きく、その原因を調査する必要がある場合は、待ち時間に関連するモニター項目を中心に分析します。待ち時間に関連するモニ ター項目は非常に多く、例えば MON_GET_DATABASE には TIME が付くモニター項目が 83 個もあります(補足:Db2 11.5では 89個に増えています)。これをすべてチェックするのは無駄が多いので、表 4 に主要な項目とそのよくある原因をまとめています。これらの項目に対して上の図で紹介したように分析したいモニター期間での差分を取り、「全体として多くなっているのはどの項目か」とか「SQL の実行回数あたりで割っても無視できないほど待ち時間が多いか」といった観点で調査します。
表 4. まずチェックすべき主要な待ち時間の項目
| 項目 | 項目の意味 | 多いときのよくある原因 |
|---|---|---|
| TOTAL_WAIT_TIME | トータルの待ち時間 | |
| TOTAL_CPU_TIME | そのデータベースで使用した CPU 時間 (マイクロ秒) | |
| POOL_READ_TIME | ディスクからデータや索引の読み込みに要した時間 | 過小なバッファープールや無駄な読み込み |
| POOL_WRITE_TIME | ディスクへのデータや索引の書き込みに要した時間 | ページクリーナーの数が足りない、ディスクの書き込み性能が足りないなど |
| TOTAL_COMPILE_TIME | SQL のコンパイルに要した時間 | パラメータマーカーを使用していない SQL が多い |
| LOG_DISK_WAIT_TIME | ログの書き込みに要した時間 | システムのキャパシティよりも更新量が多い、ディスクの書き込み性能が足りない |
| LOCK_WAIT_TIME | ロック待ちをした時間 | 同じレコードへの更新が頻発している |
なお、モニター表関数の取得結果を分析するためのさらに詳しい活用方法については「CLUB Db2 第 137 回 Db2 モニタリング入門」を、併せてご覧ください。
モニタリング製品を活用した Db2 のモニタリング
ここまで、Db2 のモニタリングの基本を理解していただくために、Db2 のモニタリングを一から構築する方法を紹介してきました。しかし、実際のシステム構築の現場で、すべてのモニタリング機能を個別に開発することはまれです。ほとんどのお客様で何らかの監視ソリューション製品 (IBM 製品だと IBM Tivoli Monitoring など) を導入されていますし、Db2の運用操作をGUIで行うツールとして IBM Db2 Data Management Console(DMC)を使用することもできます。
DMCの利用方法についてはこちらをご参照ください。
【SIL】【IM】IBM Db2 Data Management Console 利用ガイド
まとめ
この記事では、基本のモニタリングと応用編に分けて Db2 のモニタリング手法を紹介しました。Db2 のモニタリングを検討される読者の方は、まずは基本のモニタリングで紹介した項目を押さえ、その上で重要なデータベースに対しては応用編で紹介したエラーメッセージの監視や、更に詳細な性能情報の取得を検討してください。
著者 木村 佳陽子
参考情報
MON_GET_DATABASE 表関数
MONREPORT モジュールを使用して生成されるレポート
ADM メッセージ一覧
[Db2 LUW] Db2 診断ログ (db2diag.log) や管理通知ログの出力先 (IM-10-0AC)
CLUB Db2 第 137 回 Db2 モニタリング入門
シリーズ一覧
・これだけはおさえたい Db2 の運⽤: Db2 運⽤管理の概要編
・これだけはおさえたい Db2 の運用: パフォーマンス維持のための運用 (REORG と RUNSTATS) 編
・これだけはおさえたい Db2 の運⽤: Db2 を「⾒える化」するためのモニタリング運⽤
・これだけはおさえたい Db2 の運⽤: 障害回復のためのバックアップ・リカバリー
お断り:
こちらの文書は、2014年にDb2 10.5 をベースとして執筆された過去の技術記事の再掲となります。
本資料掲載事項は、ある特定の環境・使用状況においての正確性は確認されていますが、すべての環境において同様の結果が得られる保証はありません。
これらの技術を自身の環境に適用する際には、自己の責任において十分な検証と確認を実施いただくことをお奨めいたします。
マニュアルリンクなど極力最新化しておりますが、一部には古い情報が残っている可能性があります。
最新の情報については、ご利用予定のバージョンのDb2製品マニュアルにて都度ご確認いただけますようお願い申し上げます。
Document Location
Worldwide
Was this topic helpful?
Document Information
Modified date:
17 April 2024
UID
ibm17130794