How To
Summary
Db2 LUW (DB2 for Linux, UNIX and Windows) を初めてご利用される方に、Db2運用の基本的な概念をご理解いただけるよう執筆された記事です。
ご利用のDb2バージョンに依存しない内容となっています。入門、初心者向けの読み物としてご活用いただければ幸いです。
こちらの記事では、RUNSTATS と REORG が定期的な運用作業として必要であることについて解説します。
Objective
RUNSTATS と REORG
この記事は、RUNSTATS と REORG の運用方法を解説します。その前提として、RUNSTATS と REORG はどのようなもので、どのような目的で実施するのか、おさえておきましょう。
統計情報の収集 (RUNSTATS)
RUNSTATS とは
RUNSTATS は、データベースに定義されている表や索引の統計情報を収集してシステム・カタログ表に格納するためのユーティリティーです。統計情報には、レコード件数、レコードの種類や頻度、表や索引の使用ページ数、オーバーフロー・レコード (後述) の件数、空きページ数、など多様な項目が含まれます。
統計情報と RUNSTATS の目的
統計情報は、なぜ必要なのでしょうか。
下記の図が示しているように、SQL が実行されると、オプティマイザーは、システム・カタログ表に格納された統計情報を使用して、データにアクセスする方法を決定します。このアクセスする方法をアクセス・プランといいます。
アクセス・プランとは、要求された SQL の結果を得るためにどのような順序で各オブジェクトにアクセスしたらよいのか、その処理手順を示すものです。例えば、表をスキャンするのか、索引をスキャンするのか、どの索引でスキャンするのか、ソートをいつ行うのか、どのように表を結合するのか、などです。
一つの SQL に対して、アクセス・プランは複数存在します。このうち、オプティマイザーは最もコストの低いアクセス・プランを選択します。コストとは、オプティマイザーが統計情報をもとに SQL を実行するのに必要なリソース (CPU, I/O) の使用量を推定したものです。各アクセス・プランのコストを正しく見積もるためには、正確な統計情報が必要です。
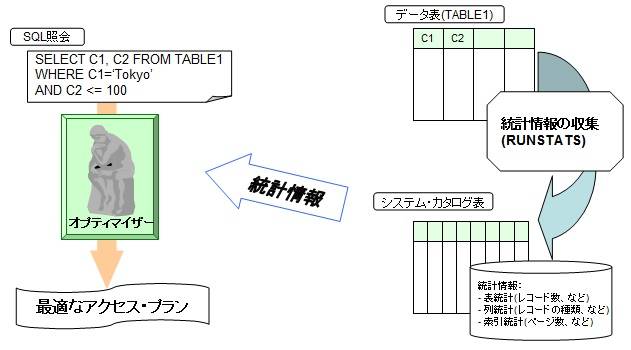
統計情報を取得した時点から、データ件数が増加したり、データの内容が変更されたりした場合、統計情報の内容が実態と乖離してしまいます。
例えば、レコード件数が 100 件の状態で RUNSTATS を実行し、その後、データ量が増えて 100 万件となった表があるとします。この場合、オプティマイザーは、統計情報を見て 100 件程度のデータ量であれば索引をスキャンするよりも表をスキャンする方がコストはかからない、と判断するかもしれません。しかし、実際は 100 万件あるので、全レコードをスキャンするコストは高く、索引を利用した方が応答時間は短いはずです。最新の統計情報をオプティマイザーに提供するために、 RUNSTATS を定期的に実行することが重要です。
再編成 (REORG)
REORG とは
REORG は、ページの中に空き領域がないようにレコードを詰め直すためのユーティリティーです。このとき、表の REORG では、索引を指定して、レコードを索引のキー順に並べなおすこともできます。
表に対して更新が行われ、レコードの追加、削除や ID などの値の変更が繰り返されると、表はどのような状態になるでしょうか。
当初のすべてのレコードが ID 順で整然と並んだ状態が崩れたり、レコードが削除されて空き領域が残ったりすることで、レコードがより多くのページに分散していきます。この状態から再編成をすると、どのような効果が生まれるのか見ていきましょう。
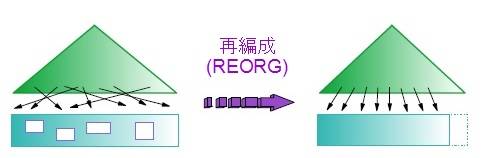
再編成の処理には、3 つの効果が期待されます。
- フラグメンテーションの解消 : ある表のレコードが削除されて空き領域になり、空き領域にレコードが挿入されないままの場合、表をスキャンするときに空き領域も含まれてしまいます。再編成をすることで、表のレコードを詰め直し、空き領域を開放することができます。
- オーバーフロー・レコードの解消 : 可変長のデータ・タイプ列が、元の長さよりも長い値で更新されると、その列を含むレコードは既存の領域には収まらなくなります。この時、更新レコードは別の場所に移動され、元のレコードの位置には移動先の情報をもったポインターが残されます。これを、レコードがオーバーフローしたといいます。オーバーフロー・レコードを取得するためには、ポインターが残されたページと実際のレコードが保管されているページの 2 ページの読み取りが必要となります。再編成をすることでオーバーフロー・レコードを解消することができます。
- 索引のキー順でデータを配置 : 上記図の三角は索引、長方形は表を意味します。図の左側は、索引の順番に対してディスク上のデータ・ページの中でレコードがばらばらに並んでいる状態です。この状態の表に対して、範囲検索条件によって多くのレコードを読み取る SQL を実行すると、読み取り先のページがばらついているため、読み込みのスループットも十分に出ません。再編成を行うことで、図の右側のように検索条件となる列の値の順に並んだ状態となります。この状態の表に対して、SQL を実行すると、先読み機能 (プリフェッチ) によってまとめて複数のページを読み取ることができます。
REORG の目的
REORG の目的は、無駄な領域を開放して表や索引のサイズを縮小させることと、I/O 効率を向上させることです。上記の 3 つの処理により、表や索引のサイズが減ることで、読み取るページ数が減少し、パフォーマンスが向上します。さらに、読み取る必要のあるレコードが連続したページに配置されることで、プリフェッチ可能となり、I/O 待ち時間が減って、パフォーマンスが向上します。
まとまったページ数を読み取る必要がある照会のパフォーマンスを維持するために、REORG を定期的に実行してください。
(ただし、索引を経由し、1 レコードを取得するようなタイプの検索の場合は、再編成によるパフォーマンスの向上はごくわずかとなります。)
RUNSTATS と REORG の運用手順
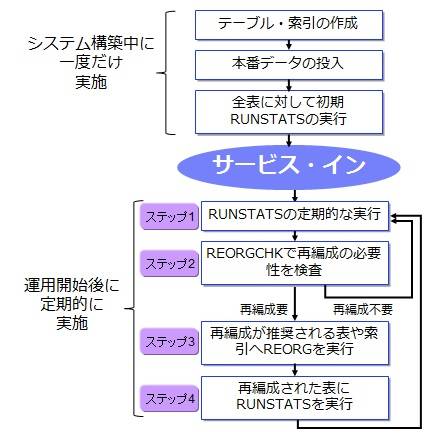
どのような手順で RUNSTATS と REORG コマンドを実施すればよいのでしょうか。運用手順の流れを下記の図で示します。
ステップ 1 からステップ 4 までが、1 回のメンテナンス・ウインドウで実施する作業の流れを示します。次回のメンテナンス・ウインドウで同じステップを繰り返します。
通常、プロジェクトにおける構築フェーズで、ステップ 1 からステップ 4 で実施する作業をシェルスクリプトで実装します。
この運用手順は、定期的にメンテナンス時間がとれる OLTP システムを前提としています。
(※) 以下の環境は、この運用手順の対象外とします。
- Db2 は Database Partitioning Feature (DPF) を使用し、複数のマシンにデータを配置している場合
- パーティション表<ポイント 12 参照>
- マルチディメンション・クラスタリング (MDC) 表 <ポイント 12 参照>
- ラージ・オブジェクト (LOB) データのある表 <STSC FAQ「[Db2 LUW] ラージ・オブジェクト (LOB) 再編成の考慮点」参照>
ステップ 1. RUNSTATS の定期的な実行
ここでは、ユーザーが定義した表のすべてを対象にして、統計情報を更新します。
RUNSTATS コマンドの実行例を示します。
RUNSTATS ON TABLE スキーマ名.テーブル名 WITH DISTRIBUTION AND DETAILED INDEXES ALL
- WITH DISTRIBUTION : 分散統計 (データの頻度と分布) が収集されます
- DETAILED INDEXES ALL : 詳細な索引統計が収集されます
指定した表とそれに関連した索引に対して、統計情報を更新します。データベースに定義されている表の数だけ、上記のコマンドを実行してください。
後述のように、データに偏りがなく均一に分布していたり、WHERE 条件で指定する値はすべてホスト変数やパラメーターマーカーを使っていたりするのであれば、分散統計を取得する必要はありません (ポイント 5 参照)。
ステップ 2. REORGCHK で再編成の必要性を検査
ここでは、REORGCHK コマンドを使用して表や索引に対して再編成が必要かどうかを検査します。このコマンドは、ステップ 1 で収集した統計情報をもとにして再編成を推奨するかどうかを判定します (ポイント 7 参照)。
REORGCHK コマンドの実行例を示します。
REORGCHK CURRENT STATISTICS ON TABLE ALL
このコマンドを実行すると、すべての表に対して再編成の必要性チェックが行われます。
ステップ 3. 再編成が推奨される表や索引へ REORG を実行
ステップ 2 の結果、再編成が推奨された表に対して、再編成を実行します。
REORG コマンドの実行例を示します。
REORG TABLE スキーマ名.テーブル名 USE 一時表スペース名
上記のコマンドで実行する REORG は、オフライン再編成と呼ばれます。
オフライン再編成中は、後述のように、並行して表にアクセスすることができないタイミングがあるため、アプリケーションの停止が必要となります (ポイント 9 参照)。また、オフライン再編成では、表本体の再編成とともに、表に定義されたすべての索引を再作成するため、索引のみの再編成を別途実施する必要はありません。
使用する一時表スペースのページ・サイズは、対象表が格納されている表スペースのページ・サイズと同じである必要があります。
REORG コマンドで索引名を指定し、特定の索引キー順にレコードを並べなおすこともできます。索引を指定する場合のコマンド例を以下に示します。
REORG TABLE スキーマ名.テーブル名 INDEX スキーマ名.索引名 USE 一時表スペース名
ステップ 4. REORG された表に RUNSTATS を実行
ここでは、再編成した結果を統計情報に反映するために、ステップ 3 で再編成した表に対して RUNSTATS コマンドを実行します。再編成を行っていない表は、ステップ 1 実行時点から表内容が変わっていないので、RUNSTATS を取得しなおす必要はありません。
ステップ 4 で実行するコマンドは、ステップ 1 で実施した RUNSTATS コマンドと同じです。
ステップ 1 からステップ 4 のメンテナンス作業を運用スケジュールに組み込み、定期的に実行してください。
運用設計のポイント
ここからは、各ステップで実行する RUNSTATS/REORGCHK/REORG コマンドの運用設計のポイントについて、説明していきます。
RUNSTATS 運用設計のポイント
ポイント 1: 全表に対して RUNSTATS を実行する
本番環境で使用されている表に対して、一度も統計情報が収集されていないという状況は避けるべきです。そのため、本番環境に作成されているすべての 表 (SYS で始まるスキーマ名をもつカタログ表を含む) に対して、本番稼動前に一度は RUNSTATS コマンドを実行してください。その際は、想定するデータ量が表に格納されていることが重要です。
ステップ 1 での RUNSTATS は、アプリケーションで使用する表はすべて含めるようにしてください。
ポイント 2: 0件の表への RUNSTATS 取得は避ける
レコード件数が 0 件、もしくは実態を反映しない少数のレコードしかないタイミングで RUNSTATS が実施されないように、RUNSTATS の実行タイミングを検討してください。
レコード件数が 0 件として登録されると、実際には多くのレコードが格納されている表であるのに小さい表であると認識してしまい、Db2 が不適切なアクセス・プランを選択してしまう可能性があります。バッチ処理でレコードがクリアされてしまう表については、データが入った状態で、 RUNSTATS を実施するようにしてください。
RUNSTATS を実施するタイミングが難しい場合の対応策については、後述します (参考: RUNSTATS を実施するタイミングが難しい場合の対応策)。
ポイント 3: RUNSTATS の並列実行は避ける
RUNSTATS コマンドを実行すると、統計情報を更新するために、システム・カタログ表が更新されます。このとき、システム・カタログ表にロックが取得されます。RUNSTATS コマンドを並列に実行すると、ロック競合の可能性があるため、順次実行してください。
ポイント 4: 並行する更新処理が少ないタイミングで RUNSTATS を実行する
RUNSTATS の実行中でも、他のユーザーが該当表に対して参照・更新することができます。ただし、表の統計を収集する時と索引の統計を収集する時の間に、該当表に更新がなされた場合、レコード内容が異なることで統計に不整合が発生する場合があります。
このとき、RUNSTATS コマンドに対して SQL2314W が返されますが、このメッセージは無視しても構いません。
RUNSTATS を実行するスクリプトを作成する際には、上記のメッセージが返されても異常終了としないように適切にハンドリングしてください。
SQL2314W
いくつかの統計が不整合な状態になっています。 新しく収集された object1 統計が、 既存の object2 統計と矛盾しています。
ただし、統計情報に不整合が存在している状況のため、照会を行う際に最適なアクセス・プランが選択されない可能性があります。
この SQL2314W が出力された場合に必ずしも SQL 性能が悪くなるとは限りませんが、並行する更新処理が少ないタイミングで RUNSTATS を実施できれば、より安全です。
ポイント 5: 検索パターンによって分散統計が不要な場合もある
以下のケースでは、分散統計 (WITH DISTRIBUTION オプション) を取得する必要はありません。
- データに偏りがなく均一に分布している
- WHERE 条件で指定する列の値はすべて、ホスト変数、または、パラメーターマーカーを使っている (ホスト変数は、コロンの後に変数名が続く形 ( : データ項目名) で示される) (パラメーターマーカーは、疑問符 (?) で示される)
分散統計を取得しない場合、オプティマイザーは、データが均一に分布していると想定してアクセス・プランを作成します。
[補足 : 分散統計を取得するメリット]
データが特定の値や範囲に偏っている場合は、分散統計を取得することで、より最適なアクセス・プランを選択するのに役立ちます。分散統計を取得した場合、指定するデータによってアクセス・プランがよりよいものに変わる可能性があるからです。
分散統計を取得する列を指定することもできます。コマンドは、以下の通りです。
RUNSTATS ON TABLE スキーマ名.テーブル名 WITH DISTRIBUTION ON COLUMNS (列名, 列名, …) AND DETAILED INDEXES ALL
デフォルトはすべての列について分散統計を取得しますが、検索条件となる列のみ分散統計を取得すれば、RUNSTATS の処理時間を短縮することができます。
ポイント 6: RUNSTATS の処理時間を短縮するにはサンプリングを活用する
RUNSTATS 全体の処理時間を短縮するには、サンプリングの使用 (SAMPLED オプション) を検討します。全レコードの代わりに、サンプリングしたレコードを対象に統計情報を収集することで、処理時間を短縮できます。
統計情報の品質を保ちつつ、RUNSTATS 実行時間を減らすための目安として、サンプリング後の対象データ量が少なくとも 1GB 程度になるようなサンプリングレートをお勧めします。データ量が 10GB の表であれば 10%が、データ量が 100GB の表であれば 1%が目安となります。
REORGCHK 運用設計のポイント
ポイント 7: F1~F3 の ’*’ で再編成の必要性を判断する
REORGCHK コマンドを実行すると、F1 から F8 までの公式に基づいて、表または索引の再編成が必要であるかを計算します。再編成が必要であると判断されると、出力の REORG 列に ’’ が表示されます。’’ が多いほど、REORG の実行が推奨されます。
オフライン再編成では、表の再編成とともに索引を再作成するため、索引に対する公式 F4~F8 は、再編成の判断基準とする必要はありません。表に対する公式 F1~F3 の ’*’ で、再編成の必要性を判断してください。
REORGCHKコマンドの出力例
表統計:
F1: 100 * OVERFLOW / CARD < 5
F2: 100 * (データ・ページ数の有効スペース使用率) > 70
F3: 100 * (必須ページ数/合計ページ数) > 80
SCHEMA.NAME CARD OV NP FP ACTBLK TSIZE F1 F2 F3 REORG
-----------------------------------------------------------------------------------------------------------------------------------------------------------
表: DB2ADM.TABLE1 828082 0 7410 7431 - 49684920 0 49 99 -*-
<中略>
索引統計:
F4: CLUSTERRATIO または正規化された CLUSTERFACTOR > 80
F5: 100 * (リーフ・ページで使用されたスペース / 空ではないリーフ・ページで使用できるスペース) > MIN(50, (100 - PCTFREE))
F6: (100 - PCTFREE) * (1 つ下のレベルの索引で使用できる合計スペース / すべてのキーで必要な合計スペース) < 100
F7: 100 * (疑似削除された RID の数 / RID の合計数) < 20
F8: 100 * (疑似的な空のリーフ・ページ数 / リーフ・ページの合計数) < 20
SCHEMA.NAME INDCARD LEAF ELEAF LVLS NDEL … F4 F5 F6 F7 F8 REORG
----------------------------------------------------------------------------------------------------------------------------------------------------------
表: DB2ADM.TABLE1
索引:DB2ADM.IDX1 828082 955 0 3 6374 100 92 37 0 0 -----
索引:DB2ADM.IDX2 828082 3572 0 3 57 0 91 8 0 0 *----
索引:DB2ADM.IDX3 828082 3572 0 3 57 0 91 8 0 0 *----
<中略>
表に対する公式 F1~F3
- F1: オーバーフロー・レコードの割合を検知する
- F2: 表のフラグメンテーションを検知する
- F3: レコードの入っていない空のページの割合を検知する
F1 に ’*’ が出力されるのは、オーバーフロー・レコードの割合が 5%を超えている状況を示します。
F2 に ’*’ が出力されるのは、表のサイズが、表が使用しているページ全体に対して 70%を超えていないためディスク・スペースが有効に利用されていない状況を示します。
F3 に ’*’ が出力されるのは、レコードが削除され、レコードの入っていない空のページの割合が 20%を超えている状況を示します。
F1 は可変長列が元の長さより長い値で更新されるケース、F3 はデータがまとめて削除されるケース、で発生し、特定の表に限定されます。このため、一般的には、F2 の ’*’ を中心に再編成する対象の表を選び、フラグメンテーションを解消しましょう。
ポイント 8: REORGCHK_TB_STATS プロシージャーを使うと SQL で結果を参照することができる
REORGCHK_TB_STATS プロシージャーは、現在の統計情報を使用して表の再編成が必要かどうかを評価し、結果を一時表の SESSION.TB_STATS に格納します。REORGCHK コマンドと評価は同じですが、SQL で結果を参照することができるので、加工しやすい形式になります。以下の例は、REORG 列 (F1, F2, F3 のいずれか) に ’*’ が出力された表名を取得する SQL となっています。
CALL SYSPROC.REORGCHK_TB_STATS('S', 'スキーマ名')
SELECT TABLE_NAME FROM SESSION.TB_STATS WHERE
REORG LIKE '%*%'
TABLE_NAME
------------------------------------------------------------------------
TABLE1
1 record(s) selected.
注: REORG_CHK_TB_STATS プロシージャーを実行したアプリケーションが終了したり、接続が切断されたりすると、SESSION.TB_STATS 一時表は自動的に削除されてしまうのでご注意ください。
REORG 運用設計のポイント
ポイント 9: オフライン再編成では、アプリケーションの停止が必要
オフライン再編成には、4つのフェーズがあります。
- ソート・フェーズ : 索引を指定した場合にソートを行う
- ビルド・フェーズ : シャドウ・コピーを作成
- 置換フェーズ : シャドウ・コピーを実表と置換
- 索引再作成フェーズ : 索引の再作成を行う
置換フェーズと索引再作成フェーズで超排他 (Z) ロックを取得するため、この間に他のユーザーがその表にアクセスできません。オフライン再編成を実施する際は、アプリケーションを停止してください。
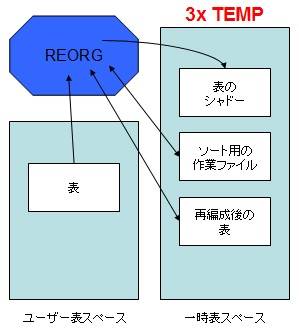
ポイント 10: 表サイズの 3 倍の一時表スペース領域を用意すべき
オフライン再編成では、一時表スペースを使用して、表の再編成と索引の再作成を実施することができます。一時表スペースには、表のシャドウ・コピー が作成され、ソート操作のための作業ファイルが保管されるため、最大で表サイズの 3 倍程度の一時表スペースの領域を使用します。
ポイント 11: アプリケーションを停止できない環境ではオンライン再編成を検討する
オフライン再編成よりは処理時間がかかりますが、オンライン再編成 (インプレース) も実施できます。オンライン再編成は、一時表を使わず、既存のエクステント (表スペースにおけるコンテナ内の領域の割り振り単位で、デフォルトは 32 ページ) の空き領域を利用します。オンライン再編成では、実行中に他のユーザーが該当表に対して参照・更新することができます。オフライン再編成のときに必要だった一時表スペースなどの作業領域は、オンライン再編成では不要です。また、オンライン再編成は、再編成の途中で、一時停止、再開、停止をすることができます。
オフライン再編成の処理時間がメンテナンス・ウインドウに入らない場合、または、再編成中でも表への更新アクセスが必要である場合に採用を検討してください。
オンライン再編成の動作は、後方の空いているエクステント領域にデータを移動し、前方のエクステントを空にした後で、再度データを並び替えていきます。また、データの移動情報についてトランザクションログに記録していきます。移動する行数に依存しますが、経験則として、オンライン再編成中には、表のデータ量に対して最大 4 倍のトランザクションログが生成されます。新たにオンライン再編成を行う場合は、再編成分のログの増加を見込んでアーカイブログ領域を見積もってください。
オンライン再編成の場合、索引は再作成されないため、別途、索引の再編成を実施する必要があります。
全ての表に対して、オンライン再編成を実行することはお薦めできません。オンライン再編成は、ログを大量に出力するため、大量のレコード件数がある表には向きません。また、データを移動している範囲内に、未コミットのトランザクションのレコードがある場合には、そのトランザクションが COMMIT されるまで、再編成は WAIT します。オンライン再編成中に実行時間の短いトランザクションが並行して実行される場合は問題ありませんが、実行時間の長いトランザクションが、オンライン再編成中の表にアクセスする場合は、オンライン再編成のパフォーマンスを下げることになります。
オンライン再編成の REORG コマンドの実行例を示します。
REORG TABLE スキーマ名.テーブル名 INPLACE
INPLACE オプションは、他のユーザーのアクセスを許可しながら、表を再編成します。
ポイント 12: 巨大な表に対しては、再編成の頻度を減らす設計を検討する
多くのデータを保持する表に対しては、設計の時点で再編成の頻度を減らすための工夫を盛り込むことをおすすめします。
- クラスタリング索引の作成 : クラスター索引を作成すると、レコードの挿入時に、索引順と、表のレコードの並び順を同じにするようにデータを格納しようとするため、クラスター率を下がりにくくすることができます。 データを索引のキー順に処理する場合、その索引に対するクラスター率が高ければ、I/O の回数が軽減され、処理効率が向上します。索引の列の値が更新される場合は、再編成が必要となってしまい、作成してもメリットはありません。 クラスタリング索引を定義するときは、必ず次の表の PCTFREE を指定します。
- 表ページの空き領域 (PCTFREE) の指定 : データのロード、および REORG TABLE 時に、PCTFREE で指定された割合のフリー・スペースを表のページ内に残します。これにより、新たなレコードが挿入されるとき、クラスター索引のキー順に合ったページにレコードを追加するための場所を用意しておくことができ、クラスター率の維持に貢献します。 また、可変長列の更新がある表で離れたページに更新レコードが追加されるオーバーフロー・レコードの発生を防ぐこともできます。ただし、あらかじめ用意したフリー・スペースが埋まってしまった場合、再びページ内にフリー・スペースを確保するには再編成が必要になります。よって、クラスター索引および PCTFREE を利用したとしても、再編成が不要となるわけではありません。 表の PCTFREE は以下のように設定します。n(%) のフリー・スペースが残されます。
ALTER TABLE スキーマ名.テーブル名 PCTFREE n - MDC 表の採用 : MDC 表は、複数列の値でデータを分類 (例. 年月、支店、商品) して、それらの列の組み合わせが同じ値をとるもの (例. 2014 年 6 月、東京支店、おにぎり) は、物理的に連続したページに配置され、クラスタリングは自動的に保守されます。このため、表の再編成は不要です。
- パーティション表の採用 : パーティション表とは、ひとつの表や索引を「パーティション (区分)」という単位で分割して構成できる表です。分割する単位は、「投入年月日を基準に月単位で編成する」など、区分キーとして指定する列の値の範囲によって定義します。 パーティション表では、デタッチという操作により、パーティション単位で一括して高速にデータを切り離すことが可能です。そのため、売り上げ明細を格納する表のように、データの保持期限が一律で決まっており、保持期限が経過したレコードを一括で削除できるような表に対して有効です。 明細データを格納する表は巨大になりがちですが、いったん投入した後で更新されるケースは少なく、またデタッチによる削除を行うと領域の開放も行われるため、表の再編成は不要です。巨大なデータを保持する表に対しては、パーティション表を活用した再編成をしない運用も選択肢として検討してください。
[参考] RUNSTATS を実施するタイミングが難しい場合の対応策
ここからは、RUNSTATS を実施するタイミングが難しい場合の対応策を紹介します。
統計情報の収集タイミングが難しい表への対応
前述したように、データの入っていない表に対しては RUNSTATS の実行を避け、データが格納されているタイミングで統計情報を収集すべきです。しかし、普段の件数が 0 件で処理の直前にしかデータが格納されない表や、オンラインの処理中にだけ仕掛かり中のデータが格納される表などでは、データが入っているタイミングでの RUNSTATS 実行がスケジュールしづらい場合があります。
このような場合にとれる対策は、2 つあります。
- 表に VOLATILE 属性を追加する
- リアルタイム統計収集を利用する
表への VOLATILE 属性追加
1 つめの VOLATILE 属性とは表に対して追加する属性で、「その表に含まれるデータ量の変動が激しく、たとえ統計情報では 0 件であっても実際の件数は異なるかもしれない」ことを Db2 に伝えるために使用します。データ量の変動が激しいことを「データが揮発性 (VOLATILE) である」と表現するため、VOLATILE というキーワードが使われます。
VOLATILE 属性が付いている表に対しては、Db2 は「統計情報とは件数が異なる可能性がある」ことを考慮に入れてアクセス・プランを生成します。そのため、RUNSTATS 実行時には 0 件のテーブルであっても、実際の件数がもっと多いことを考慮して、テーブルスキャンではなく索引経由でのアクセスとなる可能性が高くなります。
VOLATILE 属性は表ごとに追加できるため、一部の表のみで件数の変動が激しいような場合に、他の表への影響なしに採用できる選択肢として有効です。適切なタイミング での RUNSTATS が難しい表に対して VOLATILE 属性を追加する場合、下記のように表を指定して ALTER TABLE コマンドを実行してください。なお、VOLATILE 属性を追加した表に対しても RUNSTATS の実行は必要なので注意してください。
ALTER TABLE テーブル名 VOLATILE
ただし、VOLATILE 属性は、あくまでテーブル件数の見積もり時に「0 件ではないかもしれない」ことを示唆しているにすぎないので、0 件テーブルの統計情報の品質を上げるような機能ではありません。たとえば、複数の表による結合の一部に揮発性のテーブルへの参照を含むような、複雑な SQL に対して最適な結合条件を決めるためには「0 件ではない」という情報だけでは不十分で、適切なアクセス・プランが作成できない事も考えられます。
リアルタイム統計収集
そのような場合に有効なのが、2 点目に挙げた「リアルタイム統計収集」です。
リアルタイム統計収集は自動 RUNSTATS の拡張機能で、Db2 の自動運用機能の一部として提供されています。
この機能は、一言で言うと「ある表の統計情報が古いと判断した場合に、Db2 が SQL の実行直前に統計情報を収集する機能」です。Db2 は、それぞれの表に対して行われた更新アクティビティーから、統計情報が「古く」て有効とはいえない状態となっているかどうかを判断します。「SQL の実行直前」に統計情報を収集するため、収集にかけられる時間は 5 秒 (デフォルト) までに制限されており、この時間を越えると統計情報の収集はキャンセルされます。キャンセルされた表の統計情報収集は、自動 RUNSTATS の対象としてキューイングされ、非同期での統計情報収集が行われます。
リアルタイム統計収集では、必要に応じて最新の統計情報が収集されるため、VOLATILE 属性による件数の推定と比べると統計情報の品質が高く、適切なアクセス・プランが選択される可能性が高くなります。その一方で、リアルタイム統計収集は データベース単位で有効にする機能で、特定の表に対してだけ利用する事はできません。VOLATILE 属性の追加と比べると設定の影響範囲が大きくなります。
リアルタイム統計収集を有効にするためには、データベース構成パラメーターにある 4 つのパラメーター (AUTO_MAINT、AUTO_TBL_MAINT、AUTO_RUNSTATS、AUTO_STMT_STATS) がすべて ON になっていることを確認してください。これらのパラメーターは階層化されているため、4つすべてが ON になっている必要があります。
Automatic maintenance (AUTO_MAINT) = ON
Automatic database backup (AUTO_DB_BACKUP) = OFF
Automatic table maintenance (AUTO_TBL_MAINT) = ON
Automatic runstats (AUTO_RUNSTATS) = ON
Real-time statistics (AUTO_STMT_STATS) = ON
注: リアルタイム統計収集を有効にしている場合は、自動 RUNSTATS 機能も有効になっています。
まとめ
この記事では、RUNSTATS と REORG が定期的な運用作業として必要であることを解説し、実行するときの手順やコマンドの使い方などを含めて、ご紹介しました。この記事の内容から、メンテナンス作業の流れのイメージをつかんでいただき、実際に、RUNSTATS と REORG を運用スケジュールに組み込んでいただければ幸いです。
本記事は、「これだけはおさえたい Db2 の運用」シリーズの「パフォーマンス維持のための運用 (REORG と RUNSTATS) 編」です。本シリーズのその他の記事も合わせてご参照いただくことで、Db2 をうまく稼働させるために必要な運用作業について把握することができます。
- IBM Documentation
- STSC FAQ [Db2 LUW] パスポート・アドバンテージによく寄せられる質問
著者 市川 智子
シリーズ一覧
・これだけはおさえたい Db2 の運⽤: Db2 運⽤管理の概要編
・これだけはおさえたい Db2 の運用: パフォーマンス維持のための運用 (REORG と RUNSTATS) 編
・これだけはおさえたい Db2 の運⽤: Db2 を「⾒える化」するためのモニタリング運⽤
・これだけはおさえたい Db2 の運⽤: 障害回復のためのバックアップ・リカバリー
お断り:
こちらの文書は、2014年にDb2 10.5 をベースとして執筆された過去の技術記事の再掲となります。
本資料掲載事項は、ある特定の環境・使用状況においての正確性は確認されていますが、すべての環境において同様の結果が得られる保証はありません。
これらの技術を自身の環境に適用する際には、自己の責任において十分な検証と確認を実施いただくことをお奨めいたします。
マニュアルリンクなど極力最新化しておりますが、一部には古い情報が残っている可能性があります。
最新の情報については、ご利用予定のバージョンのDb2製品マニュアルにて都度ご確認いただけますようお願い申し上げます。
Document Location
Worldwide
Was this topic helpful?
Document Information
Modified date:
17 April 2024
UID
ibm17129890