Troubleshooting
Problem
In a IBM Maximo Application Suite (MAS) where Mongodb is deployed on Red Hat OpenShift, It is expected to have 3 replicas.
The Mongodb cluster is in state ready when all 3 pods are in a ready state.
When the Mongodb cluster is started, it starts one pod at a time and the next one starts only when the previous one is in ready state.
it can happen that the first pod, mas-mongo-ce-0 never comes in a ready state. In this case the mongo cluster remains in a pending state and MAS is not accessible.
Symptom
the mongoce1 pod logs show the following error:
2023-07-21T14:10:23.896+0000 I REPL_HB [replexec-2347] Heartbeat to mas-mongo-ce-1.mas-mongo-ce-svc.mongoce.svc.cluster.local:27017 failed after 2 retries, response status: HostUnreachable: Error connecting to mas-mongo-ce-1.mas-mongo-ce-svc.mongoce.svc.cluster.local:27017 :: caused by :: Could not find address for mas-mongo-ce-1.mas-mongo-ce-svc.mongoce.svc.cluster.local:27017: SocketException: Host not found (authoritative)
2023-07-21T14:10:23.897+0000 I REPL_HB [replexec-2347] Heartbeat to mas-mongo-ce-2.mas-mongo-ce-svc.mongoce.svc.cluster.local:27017 failed after 2 retries, response status: HostUnreachable: Error connecting to mas-mongo-ce-2.mas-mongo-ce-svc.mongoce.svc.cluster.local:27017 :: caused by :: Could not find address for mas-mongo-ce-2.mas-mongo-ce-svc.mongoce.svc.cluster.local:27017: SocketException: Host not found (authoritative)
2023-07-21T14:10:23.897+0000 I REPL_HB [replexec-2347] Heartbeat to mas-mongo-ce-2.mas-mongo-ce-svc.mongoce.svc.cluster.local:27017 failed after 2 retries, response status: HostUnreachable: Error connecting to mas-mongo-ce-2.mas-mongo-ce-svc.mongoce.svc.cluster.local:27017 :: caused by :: Could not find address for mas-mongo-ce-2.mas-mongo-ce-svc.mongoce.svc.cluster.local:27017: SocketException: Host not found (authoritative)
Cause
One of the secondary nodes can sometimes be promoted to primary node. This happens when the primary node is not responding for any reason.
Find more information in the link below:
https://docs.mongodb.com/manual/core/replica-set-elections/#replica-set-elections
Once the primary node that was not responding recovers back, it should be promoted again as the primary since it has more priority.
Once the primary node that was not responding recovers back, it should be promoted again as the primary since it has more priority.
https://docs.mongodb.com/manual/core/replica-set-elections/#member-priority
if the pods were restarted when the first pod is not the primary, you can end up in this situation
Environment
In a IBM Maximo Application Suite (MAS) where Mongodb is deployed on Red Hat OpenShift, only one mongo pod is deployed and it is not ready.
This problem happens after a restart of the mongo pods.
In a typical deployment you have 3 replicas.
Diagnosing The Problem
Check the status of the mongo pods
$ oc get pods -n mongoce
NAME READY STATUS RESTARTS AGE
mas-mongo-ce-0 1/2 Running 0 31m
In a working environment, there are 3 pods in a ready state
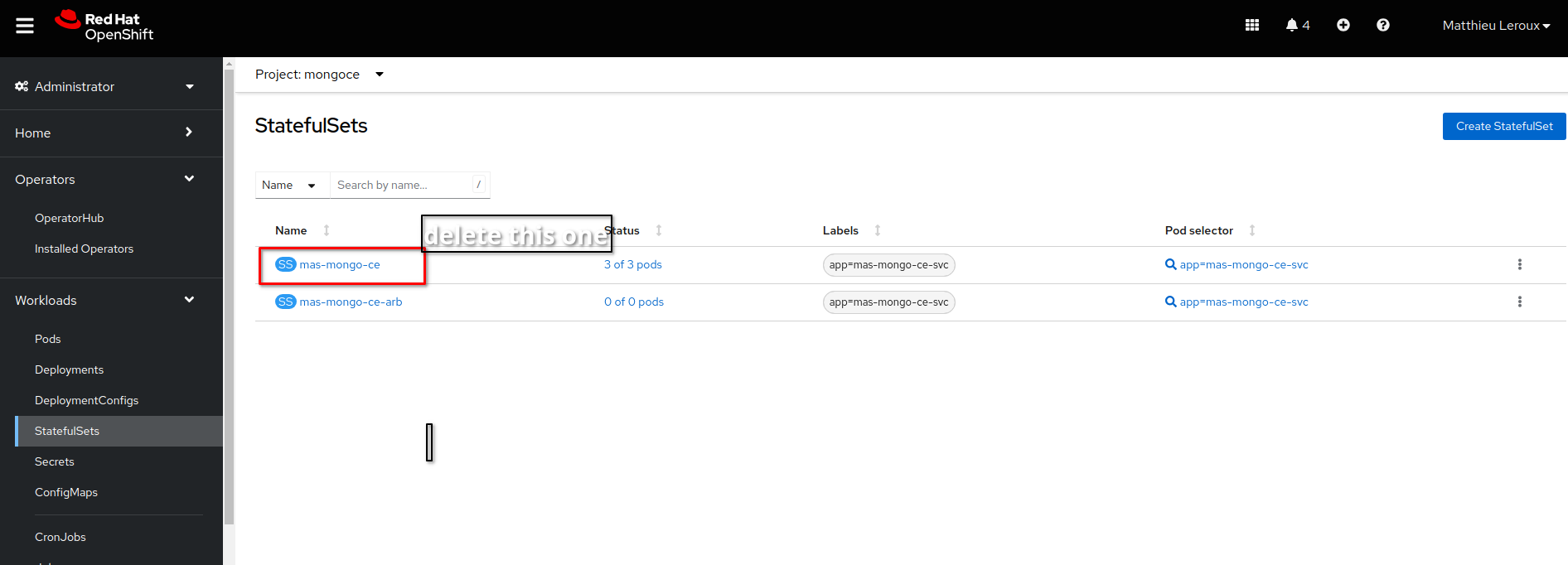
if only 1 pod is started and both containers are not in a ready state after some time, you can delete the statefulset:
$ oc delete statefulset -n mongoce
Or from Red Hat OpenShift console:
Resolving The Problem
If after the statefulset is deleted, the other pods are still not created, you can remove the readiness probe from the statefulset:
$oc edit statefulset mas-mongo-ce -n mongoce
Or from the Red Hat OpenShift console: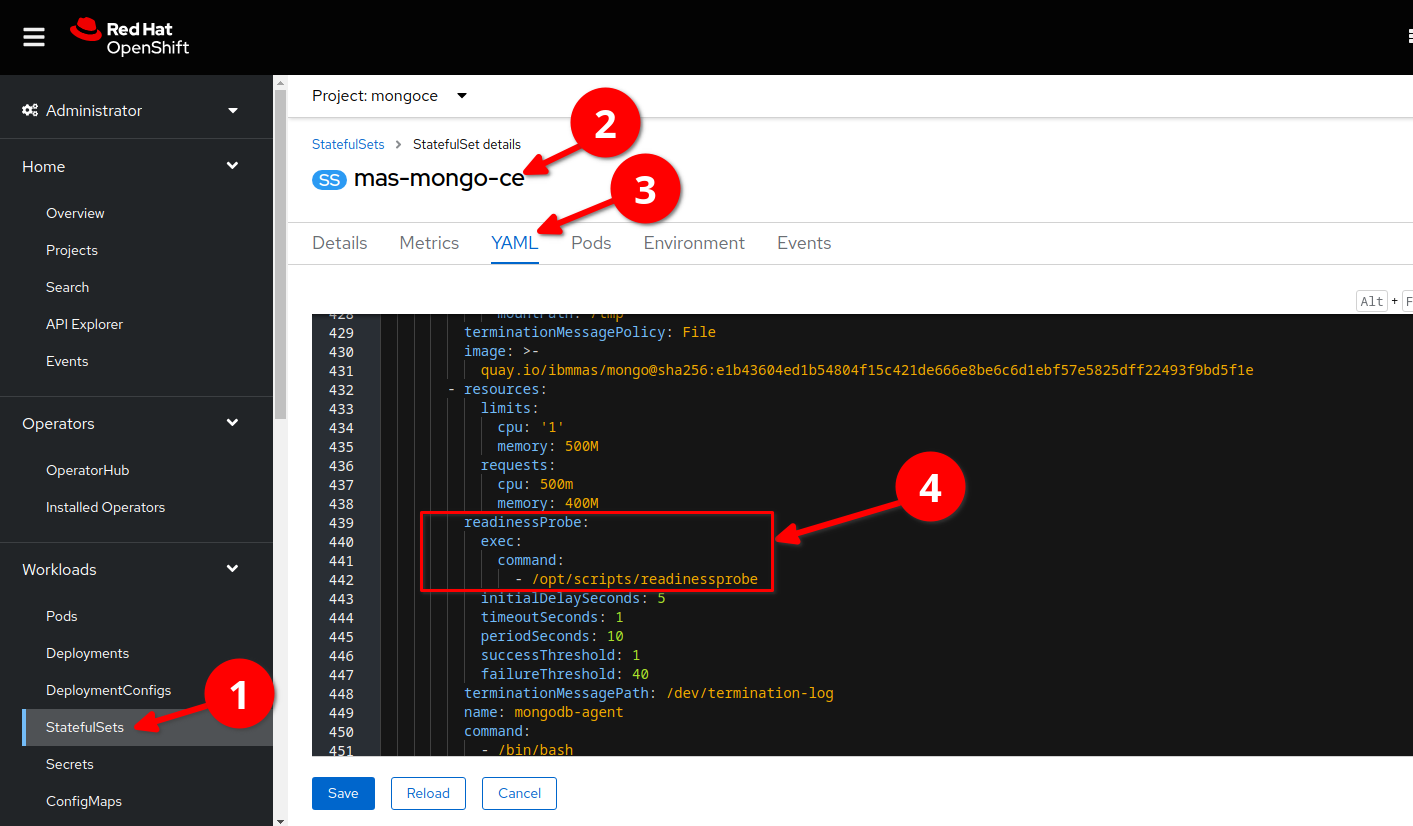
After the statefulset is saved, the other mongo pods do not have to wait for the previous pod to be in a ready state.
After some time, the stateful set should be reconciled and the readiness probe should be added to the statefulset definition.
When the readiness probe is added to the statefulset, check the status of the 3 pods, if you have one pod that is not ready, it may be that you have a data issue on one of the replicas.
you can login to the mongo shell in the terminal of the pods and check the state of the replica.
In a working mongo cluster, after all 3 replicas are started, you should have one replica as PRIMARY and two replicas as SECONDARY.
You can check which replica is the PRIMARY by logging to the mongo shell on each replica. Once logged in the replica, the mongo prompt gives the state of the replica, for instance, PRIMARY or SECONDARY.
In some cases, the data could be corrupted and you would have a prompt that states RECOVERING.
After identifying the PRIMARY replica, you can delete the /data folder on the recovery replica to force the replication.
to login to the mongo shell, see https://www.ibm.com/support/pages/how-open-mongo-shell-mas-mongodb.
Here is an example.
login to mongo-ce-0 replica:
mongo "mongodb://mas-mongo-ce-0.mas-mongo-ce-svc.mongoce.svc.cluster.local:27017" --username admin --password wdw7NeqN8Vq48wE6 --authenticationDatabase admin --tls --tlsAllowInvalidCertificates
if you see the prompt:
mas-mongo-ce:PRIMARY>
The pod mongo-ce-0 is the primary replica
if you see:
mas-mongo-ce:SECONDARY>
this replica has experienced an issue in the past, after some time this replica should becore primary again.
if you see:
mas-mongo-ce:RECOVERING>
the data is being synced with the primary node. However, in some cases the replica is too much out of sync and will never recover, in that case, you can delete the /data folder in that pod, restart the pod and it should then sync with the PRIMARY replica.
Document Location
Worldwide
[{"Type":"MASTER","Line of Business":{"code":"LOB59","label":"Sustainability Software"},"Business Unit":{"code":"BU059","label":"IBM Software w\/o TPS"},"Product":{"code":"SSRHPA","label":"IBM Maximo Application Suite"},"ARM Category":[{"code":"a8m3p000000hAgfAAE","label":"Maximo Application Suite-\u003EThird Party Products or solutions"}],"ARM Case Number":"","Platform":[{"code":"PF025","label":"Platform Independent"}],"Version":"All Versions"}]
Was this topic helpful?
Document Information
Modified date:
29 November 2023
UID
ibm17014197