Question & Answer
Question
Following error occurred during working with large amount of data on spark session in Jupyter Notebook.
org.apache.spark.SparkException: Job aborted due to stage failure: Total size of serialized results of 1 tasks (1477.3 MiB) is bigger than spark.driver.maxResultSize (1024.0 MiB)
Could you tell me how to avoid this issue?
Cause
Serialization is the processing of converting data objects into a series of Bytes during transferring across the network. Serialized data is using for data transfer across executors or also between driver and executor.
The spark.driver.maxResultSize parameter in spark session configuration defines the maximum limit of the total size of the serialized result for Spark actions across all partitions. The spark actions include actions such as collect() to the driver node, toPandas(), or saving a large file to the driver local file system.
Answer
In general, you might have to refactor the code to prevent the driver node from collecting a large amount of data. Writing files and then read those files instead of collecting large amounts of data back to the driver or call toPandas() with Arrow enabled could help you to avoid the problem.
If necessary, you can set the property spark.driver.maxResultSize to a value that higher than the value reported in the exception message.
The Spark Jupyter Notebook in CP4D has default spark session already running. So, to change spark.driver.maxResultSize parameter with the new value, you need to stop the current spark context (sc) and create the new one with following steps:
1. Check current spark session and spark context session.
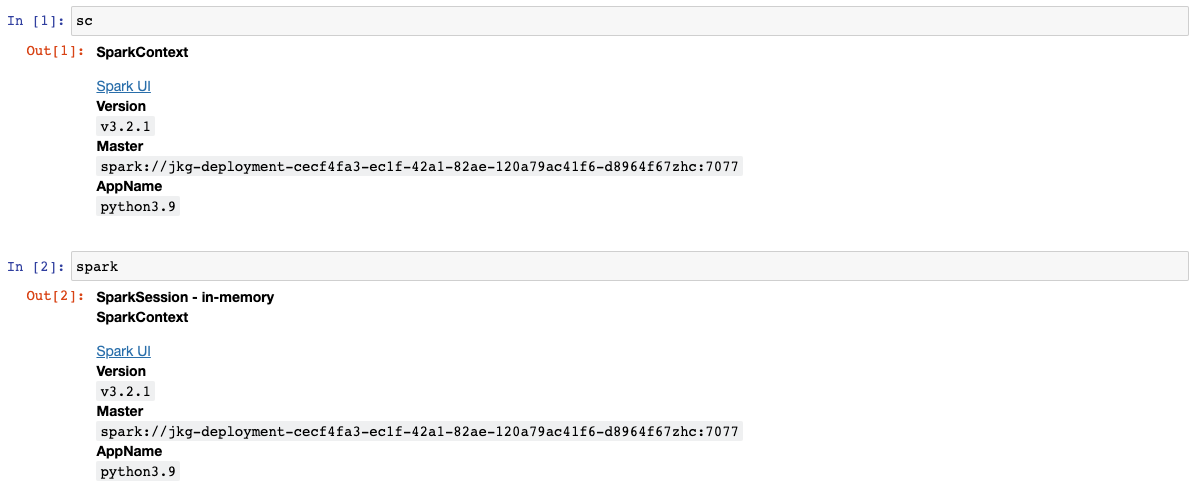
2. Stop spark context session and create new spark session.

3. Confirm spark context and spark session created with new spark.driver.maxResultSize value.
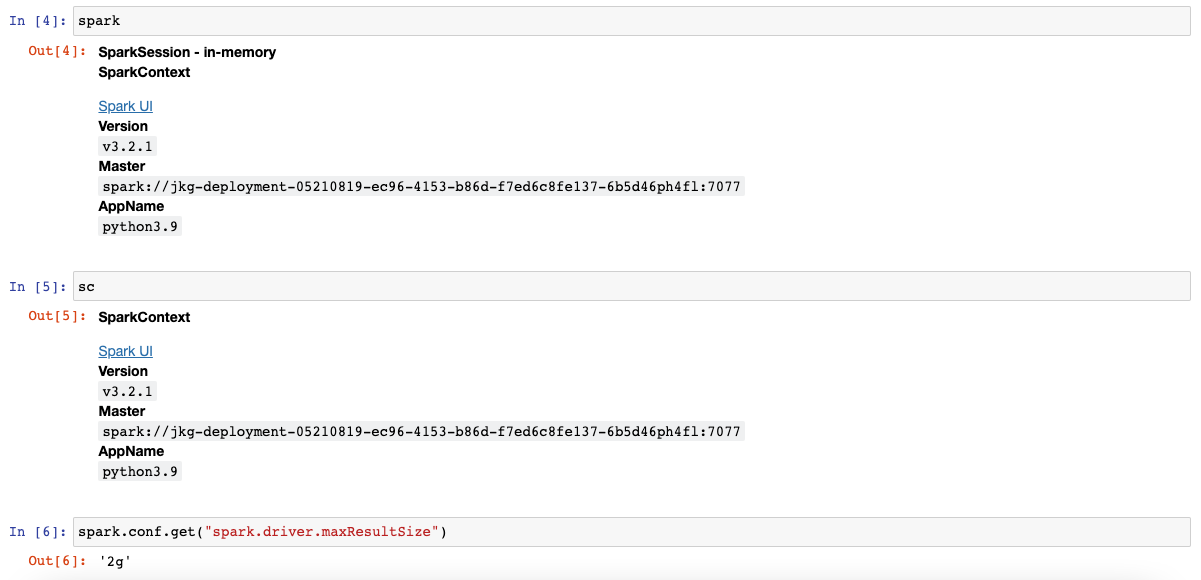
Notes:
- The default value of spark.driver.maxResultSize is 1Gb. The minimum value is 1Mb, and the maximum is 0 (unlimited).
- If the size of the serialized result sent to the driver is greater than its max result size, then the spark job fails with memory exceptions.
- It is always better to have a proper limit instead of unlimited setting to protect the driver from out-of-memory errors.
[{"Type":"MASTER","Line of Business":{"code":"LOB10","label":"Data and AI"},"Business Unit":{"code":"BU059","label":"IBM Software w\/o TPS"},"Product":{"code":"SSHUT6","label":"IBM Watson Studio Premium Cartridge for IBM Cloud Pak for Data"},"ARM Category":[{"code":"a8m3p000000hBziAAE","label":"Analytics Engine"}],"ARM Case Number":"TS011884551","Platform":[{"code":"PF025","label":"Platform Independent"}],"Version":"All Versions"}]
Was this topic helpful?
Document Information
Modified date:
31 January 2023
UID
ibm16856647