Question & Answer
Question
Answer
■数量化理論Ⅱ類 ダミー変数
数量化理論Ⅱ類は判別分析を使用します。SPSS Statisticsの線型回帰分析や判別分析は、例えば「1:おいしかった」「2:ふつう」「3:おいしくなかった」という値を持つ「数値に値ラベルを貼ったカテゴリー変数」を数値として分析することができますが、数量化理論としてはこの状態で分析しません。「1:おいしかった」「2:ふつう」「3:おいしくなかった」というひとつの変数は、「1:おいしかった/0:該当せず」「1:ふつう/0:該当せず」「1:おいしくなかった/0:該当せず」の3つのダミー変数に分けて、分析をします。
例えば、従属変数が「Y」、独立変数が「X1」「X2」の以下のデータで分析をする場合は、
|
ケース番号 |
X1 |
X2 |
Y |
|
1 |
1 |
800 |
5000 |
|
2 |
3 |
660 |
3980 |
|
3 |
2 |
750 |
4500 |
|
4 |
3 |
770 |
4800 |
|
5 |
1 |
810 |
5500 |
カテゴリー変数「X1」を以下の様なデータに直して分析をする必要がございます。
|
ケース番号 |
X1_1 |
X1_2 |
X1_3 |
X2 |
Y |
|
1 |
1 |
0 |
0 |
800 |
5000 |
|
2 |
0 |
0 |
1 |
660 |
3980 |
|
3 |
0 |
1 |
0 |
750 |
4500 |
|
4 |
0 |
0 |
1 |
770 |
4800 |
|
5 |
1 |
0 |
0 |
810 |
5500 |
■数量化理論Ⅱ類 分析方法
製品付属サンプルデータの「bankloan.sav」を使用して、数量化理論Ⅱ類の分析を行います(C:\Program Files\IBM\SPSS Statistics\Samples\Japanese\bankloan.sav)。
従属変数Y:「不履行」
独立変数X:「年齢」「教育(数値に値ラベルを貼ったカテゴリー変数)」「雇用」
年齢・学歴・雇用年数で債務不履行になるケースをグループ分けします。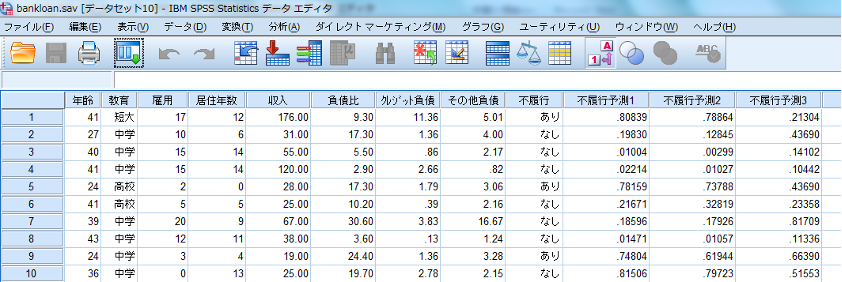
3.[ダミー変数を作成]ダイアログにて、[次のダミー変数を作成]にリストから「教育レベル[教育]」を投入し、[ルート名(選択した変数ごとに1つ)]に「学歴」と入力し、[OK]をクリックします。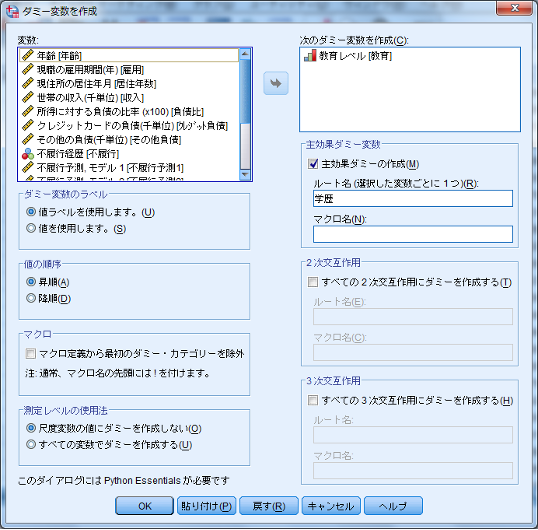
4.実行しますと、データの最後に変数「学歴_1」から「学歴_5」が追加されます。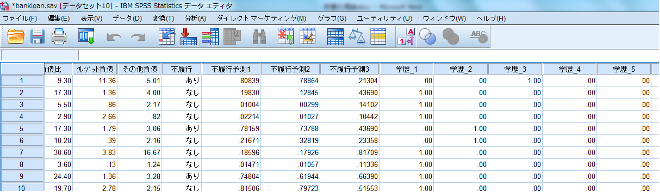
5.[変数ビュー]で作成された変数を確認いたしますと、変数「教育」の「1:中学」から「5:大学院」までに対して、該当する変数に「1」と返しているダミー変数が作成されていることが確認できます。この変数を使用して回帰分析を行います。
6.メニューの[分析]→[分類]→[判別分析]をクリックし、[判別分析]ダイアログにて、左にあるリストから、[グループ化変数]に「不履行経歴[不履行]」、[独立変数]に「年齢」「現職の雇用期間(年)」「教育=中学」「教育=高校」「教育=短大」「教育=大学」「教育=大学院」を投入します。必要に応じて他の項目も設定しますが、今回はこのまま[OK]をクリックします。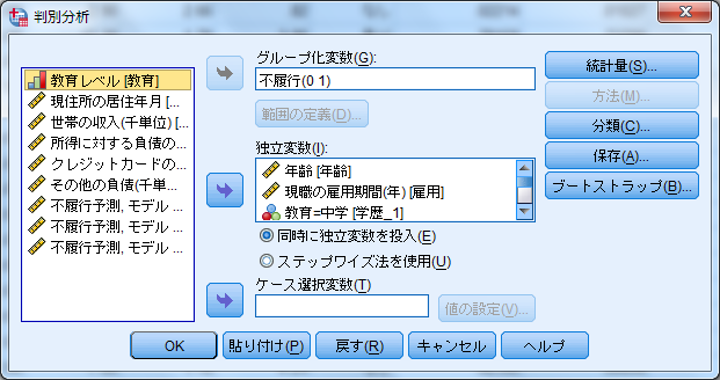
7.実行をしますと、ビューワーに判別分析の結果が出力されます。[標準化された正準判別関数係数]テーブルや[構造行列]テーブルなどが出力されます。[構造行列]テーブルでは従属変数と各独立変数の相関を表しております。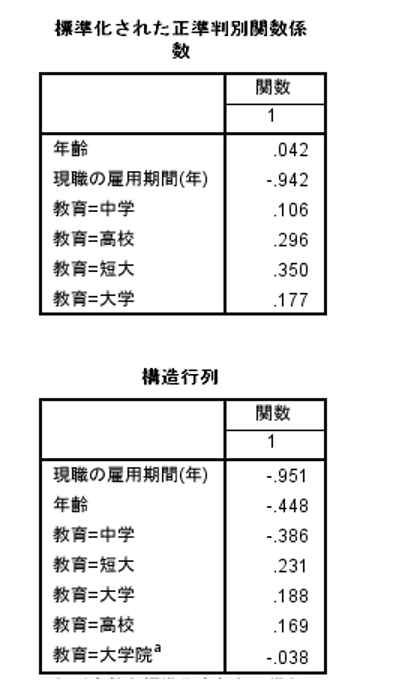
Was this topic helpful?
Document Information
More support for:
IBM SPSS Statistics
Component:
AAJapanese->Statistics
Software version:
All Versions
Document number:
6825045
Modified date:
29 September 2022
UID
ibm16825045