General Page
Common table expressions (CTEs) are a useful way to make SQL queries easier to write, understand, and maintain. They allow you to break apart complex queries into more isolated pieces that can be separately developed and tested. Much like SQL views, they give you the ability to re-use common definitions and logic. CTEs belong in the toolbox of every SQL developer.
Although CTEs are similar to views in how they assist the SQL developer, they are different from views in an important way. A view defines a logical result set, whereas a CTE defines a materialized result set. As a logical result set, the view can be implemented in any way that the optimizer sees fit as long as it is faithful to the view definition. On the other hand, a CTE must be interpreted and used as though it were an actual temporary table. In most cases, this is a difference without a distinction: the optimizer will handle views and CTEs in the same manner. However, in cases where the query references a view or a CTE multiple times and the underlying data is changing, the difference becomes clearer. In such situations, the CTE is required to return a single consistent result set that is identical across all the references in the query. A view is not bound by the same requirement, and each reference within the query is permitted to return the data that is consistent with the view definition at the time that the view reference is applied.
Consider the following example. We want to get an average price per category for all categories in our product list, and we also want to see the maximum of the average prices. We can do this by creating a CTE or a view defining the average price per category and then querying it.
|
With a CTE |
With an SQL view |
|
WITH cte1 AS ( |
CREATE VIEW view1 as (
|
For static data, both forms return the same answer, with the “MAX:” line always containing a value from the result set of the first of the UNIONed subqueries. However, if the products table is being updated while the query is running, it is possible (and valid) for the view-based example to produce a MAX(avgPrice) that is not included in the earlier list, since the update to the table could happen between the running of the two UNIONed subqueries. With the CTE definition, the two subqueries of the union will always be consistent.
Improving standards compliance in Db2 for IBM i
What does this have to do with Db2 for IBM i? Db2 for i has long followed a relaxed interpretation of the SQL Standard with regard to CTEs. Effectively, CTEs have been implemented in the same manner as views, with the same possibility of returning different results for each reference in a query. Since CTEs that are referenced multiple times in a query — I will call these shared CTEs from now on — are often found in complex analytic type queries over static data, this is generally not a problem. However, if the underlying data is changing, queries using shared CTEs can produce inconsistent results.
The Db2 for i SQE optimizer is addressing this gap by strictly adhering to the SQL Standard behavior. A partial implementation has been PTFed for 7.3, and the SQL Standard behavior is fully implemented in IBM i 7.4 (by PTF) and IBM i 7.5. The remainder of this article explains the implications of this change and describes how you can adapt to it.
Before this change, when working with the existing implementation of shared CTEs, the optimizer had two options for handling multiple references:
- "Capture" the results set of the CTE. The full CTE is run once by itself, and the resulting data is stored in a temporary data structure to be shared wherever the CTE is referenced in that query.
- "Merge" each CTE as defined into the query definition tree and handle each CTE reference separately. This will treat each CTE reference as its own entity, duplicating the underlying query definition tree. This allows the optimizer to decide how each reference to that tree is run based on the context of that reference and the predicates applied to that reference.
A Visual Explain of our example CTE query above shows the two different implementation options:
|
Capture |
Merge |
|
|
|
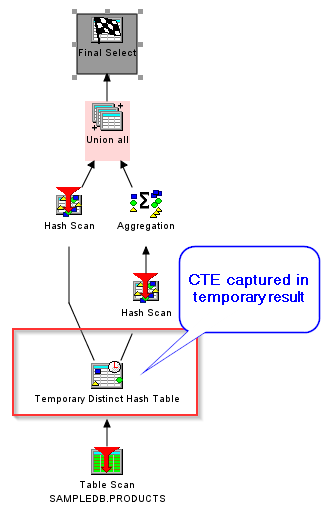
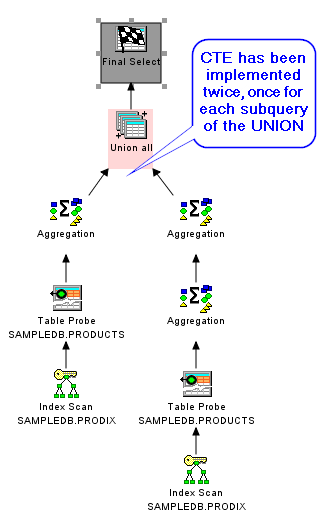
There are advantages and disadvantages to each of these options and the optimizer attempts to select the one that enables the fastest query performance.
In some cases, capturing the result set will be a slower operation than merging the CTE definition into the rest of the query. This is particularly true when the CTE defines a large temporary result set or when there are predicates applied to the individual references that can be “pushed down” into the merged CTE.
|
Sample query with predicates. When using the merge option, the predicates can be applied to individual implementations of the CTE. |
|
WITH cte1 AS ( |
Nevertheless, in order to adhere to the SQL Standard, the merge option is no longer available by default for shared CTEs. Only the capture option correctly implements the SQL Standard for CTEs that are referenced more than once. (Note: CTEs that are referenced only once can still be safely merged into the query tree.) As the optimizer changes to follow SQL Standard behavior, some queries which were implemented with the merge option for shared CTEs will run more slowly than they did in the past. At the same time, some queries with shared CTEs might see improved performance.
Capturing the CTE also is incompatible with “live data” environmental settings—when a sensitive cursor or ALWCPYDTA *NO is used—since these prohibit the use of temporary results. This means that queries with shared CTEs that have been running successfully in these environments before this change will now fail with SQLCODE -243 or SQLCODE -527. Such queries need to be modified, or the environmental settings need to be changed.
DETERMINISTIC CTEs
To assist those users who have existing queries that are negatively affected by this change, IBM has provided an addition to the SQL language to allow the optimizer to continue to consider the two implementation options. The addition is a new keyword, DETERMINISTIC, that can be specified after the CTE name. As its name suggests, the use of DETERMINISTIC tells the optimizer that the data underlying the CTE will not change during the query's execution. In other words, users of the DETERMINISTIC keyword are asserting that the CTE returns a stable and consistent result across all references within the query. Because DETERMINISTIC allows the optimizer to relax its adherence to the SQL standard, it should be used only after careful evaluation of the CTE to ensure that the result defined by the CTE is truly deterministic. If the underlying data does change during query execution, the CTE can return inconsistent or unexpected results.
Evaluating your current situation
The first thing to do is to understand whether your systems and workloads have any exposure to this change. Do you regularly run queries that include shared CTEs? Are these queries running with live data settings, or do the CTEs select large amounts of data? If so, you need to assess the effect of this change on those queries.
To assist with this analysis, IBM has added information to the database monitor and to plan cache snapshots. This information is captured for all queries in IBM i 7.5. In earlier releases, the information is captured with PTFs MF69446 for IBM i 7.3 and MF69231 for IBM i 7.4. The 3014 monitor record has been updated with a value in QQSMINT1 that indicates whether the query uses shared CTEs. If the value is 0 or null, the query does not use shared CTEs. If the value is 1, the query has at least one shared CTE. And if the value is 2, the optimizer estimates that a shared CTE will capture at least 1 million records in its temporary result set. Working with a data set that large can degrade the query’s performance, which is why the optimizer takes care to note these shared CTEs separately. A value of 255 for QQSMINT1 indicates that the query has at least one shared CTE that has been labeled as DETERMINISTIC.
You begin by gathering data to analyze. For many workloads, an SQL plan cache snapshot is the simplest method to obtain data. Depending on your workload and the size of the plan cache, it might make sense to create a plan cache snapshot at multiple different times, perhaps in the morning and in the evening. A snapshot can be created with the IBM i Access Client Solutions (ACS) SQL Performance Center (File -> New -> Plan Cache Snapshot) or with the SQL service CALL QSYS2. DUMP_PLAN_CACHE(). A more targeted alternative to the plan cache snapshot is to use the database monitor to gather data from a workload of interest. The database monitor can be started from the SQL Performance Center (File -> New -> Performance Monitor) or from the command line with STRDBMON. Keep in mind that the database monitor can add overhead to a system and so should be used carefully.
Once you collect a database monitor file or a plan cache snapshot, you can run the following analysis queries over the data to determine whether any of your collected SQL statements use shared CTEs.
|
Finds all queries that have a shared CTE. Ordered by the shared CTE usage and the number of times run. |
WITH rcds1000 AS ( |
|
Find queries that have a shared CTE and run with ALWCPYDTA *NO or a sensitive cursor. Ordered by most recent run. |
WITH rcds1000 AS ( |
If you find queries that use shared CTEs, you need to dig a little deeper. Is this query run frequently? Do the shared CTEs select large amounts of data? Will it cause major impacts if the query performance degrades? If running with live data settings, how much disruption will be caused if the query begins to fail? Or will nothing change, since the query plan already captures the CTE result set in a temporary data structure?
Handling queries with shared CTEs
Once you have the set of highest-priority queries in hand, you can make a plan for addressing them. The first question to ask about each query is: Is it necessary to have the shared CTE return identical results with each reference and is it possible that the underlying data could be changing while the query is running? If the answer to both parts of this question is “Yes”, then you need to accept the performance changes and environmental restrictions that accompany this change.
Forcing the CTE to be captured
But what if you are concerned about incorrect results in the query ? There is a simple action you can do to force the optimizer to capture the CTE result set without even considering the merge option. The trick is to add a dummy predicate to the CTE that references a non-deterministic function. The predicate must be coded in such a way that it does not alter the set of rows returned by the CTE. This could be as simple as adding AND RAND() IS NOT NULL. Or you could create and reference your own simple “do-nothing” user-defined function (UDF) defined as NOT DETERMINISTIC. The optimizer understands that to honor the intent of a CTE that references a non-deterministic UDF it must ensure that the CTE runs only once. It does so by capturing the CTE results, thereby guaranteeing consistent and predictable data across all the references to that CTE.
|
Original query |
Using RAND() to force capturing |
Using user UDF to force capturing |
|
WITH cte1 AS ( |
WITH cte1 AS ( |
CREATE FUNCTION dummy () |
Rewriting the query to remove the shared CTE
If the underlying data is not likely to change—perhaps you are querying a data warehouse that is updated on a predictable schedule—or if consistent results from each reference are not critical to the query logic, then the next question to consider is: Should I rewrite the query to remove the shared CTE references? The answer to this is harder to define in absolute terms, but the following heuristic is a good guide.
Will the query performance degrade with the upcoming changes? You can get a feel for the answer to this question by adding a non-deterministic UDF predicate as described in the section above. If the modified query does not run significantly slower, then you can likely ignore this query. You could also run a COUNT(*) query over the CTE by itself to determine how many rows it is selecting. CTEs that generate larger temporary result sets require more time and memory to process.
If you believe that the query performance will become unacceptable or you know that the query is running with live-data restrictions, you will likely need to rewrite the query to remove the shared CTE references. This can be done by: (1) transforming the CTE into a view and replacing the CTE references with view references; (2) using the DETERMINISTIC keyword; (3) splitting the CTE into multiple duplicate CTEs; or (4) merging the CTE logic in as a nested table expression. Each of these approaches has advantages and disadvantages, and you need to consider the best alternative for your queries. An example of each of these methods is shown in the following table.
|
Original shared CTE query |
WITH cte1 AS ( |
|
Using a view |
CREATE VIEW view1 as (
|
| Using DETERMINISTIC |
WITH cte1 DETERMINISTIC AS (
SELECT category, AVG(price) avgPrice FROM products GROUP BY category) SELECT category, avgPrice FROM cte1 UNION ALL SELECT 'MAX:', MAX(avgPrice) FROM cte1; |
|
Splitting the CTE |
WITH cte1 AS ( cte2 AS (SELECT AVG(price) avgPrice |
|
Merging in as a nested table expression |
SELECT category, avgPrice FROM (SELECT category, AVG(price) avgPrice |
Note that creating a temporary table was not included as a solution. The use of QTEMP is discouraged for a number of reasons.
Wrapping it up
Common table expressions can make an SQL developer’s life much simpler, and they are often the best way to break up a complex query into manageable chunks. At the same time, the SQL Standard provides the rules of expected behavior for how an SQL optimizer must implement CTEs. As Db2 for IBM i tightens up its implementation to ensure standards compliance and correct results, some queries that were enjoying the benefits of a less rigorous implementation might feel a bit of pain. Other queries could benefit. By planning ahead and using the tools that IBM provides for query analysis, you can minimize the pain and maximize the possibility of a smooth transition. And if you are looking for help identifying, analyzing, and possibly rewriting your CTE queries, Systems Expert Labs is available to assist with this and many other consulting needs.
Was this topic helpful?
Document Information
Modified date:
14 August 2023
UID
ibm16575467