Question & Answer
Question
Answer
1. コンジョイント分析の概要
コンジョイント分析は、いくつかの構成要素の内でどの要素を重視するかをあぶり出す手法です。例えば「家賃」「最寄り駅の乗降客数」「駅から徒歩何分か」「築年数」「間取り」「部屋の広さ」「駐車場有無」「ペット可否」などの構成要素から「それぞれがどの値のアパートが人気なのか」を導き出すことが出来ます。
コンジョイント分析を行う前に被験者にいろいろな構成要素の組み合わせカードを見せて順位付けをしてもらいますが、その組み合わせカードは実験計画法の直交計画で生成します。
順位付けを元にコンジョイント分析を行いますが、コンジョイント分析はシンタックスによるコマンド操作のみで実行が可能で、GUIによるダイアログでは実行できません。
2. 対応アプリケーション
IBM SPSS Statistics Conjoint
3. 直交計画を実行してコンジョイントカードを作成
ここではIBM SPSS Statisticsに付属されているサンプルファイルを用いた例となります。お客様のデータをご使用されて分析されます場合には、分析目的に沿った設定をしていただけますようお願いいたします。
分析内容:カーペット専用洗剤のメーカーが、消費者がどのような内容の商品を望んでいるかを調査する。
操作手順:
1) SPSS Statisticsを起動し、メニューの[データ]→[直交計画]→[生成]をクリックします。
2) [直交計画]に[因子名]と[因子ラベル]を定義します。[因子名]に「外装」、[因子ラベル]に「パッケージのデザイン」をキーボードで入力して[追加]ボタンをクリックします。追加された変数を選択して[値の定義]ボタンをクリックします。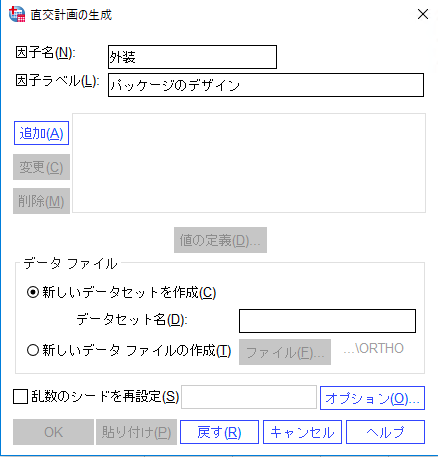
3) [値の定義]ダイアログにてこの変数の値「1」「2」「3」に対してそれぞれ「A*」「B*」「C*」と設定して[続行]ボタンをクリックします。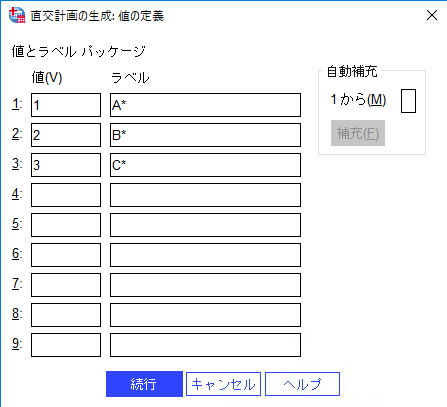
4) 変数「外装」と3種類の値が設定されました。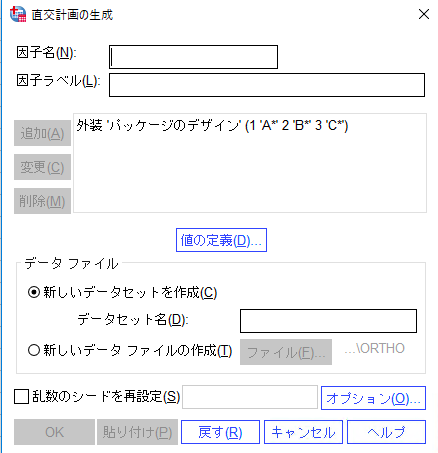
この方法を繰り返して残りの変数(因子)を以下のように設定してください。
| (因子) | (因子ラベル) | (値) | (ラベル) |
| ブランド | ブランド名 | 1、2、3 | K2R、Glory、Bissell |
| 価格 | 価格 | 1.19、1.39、1.59 | $1.19、$1.39、$1.59 |
| シール | サービスシール | 1、2 | なし、あり |
| 払戻し | 料金の払戻し | 1、2 | なし、あり |
データセット名に任意の名称を入力し、[乱数のシードを再設定]をチェックして「2000000」と入力して、[オプション]ボタンをクリックします。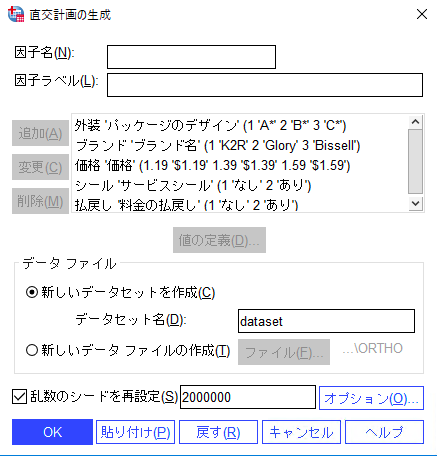
5) この例では[オプション]ダイアログにて、[生成するケースの最小数]を最低18個生成することとして「18」と入力し、[ホールドアウトケースの数]をチェックして値を「4」とします。[続行]ボタンで[直交計画の生成]ダイアログに戻って[OK]ボタンをクリックして実行します。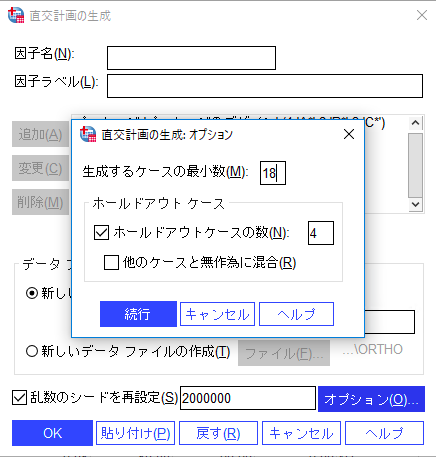
6) 実行しますと変数「CARD_」の番号順に22個のコンジョイントカードが作成されます。被験者にこのコンジョイントカードを好きな順番に全て並び変えていただき、それを集計したデータでコンジョイント分析を行います。分析に使用するカードは変数「STATUS_」が[計画]のカードだけで、[ホールドアウト]のカードは一緒に評価はしてもらいますがコンジョイント分析からは除外します。このデータセットは「carpet_plan.sav」という名前を付けて保存します。
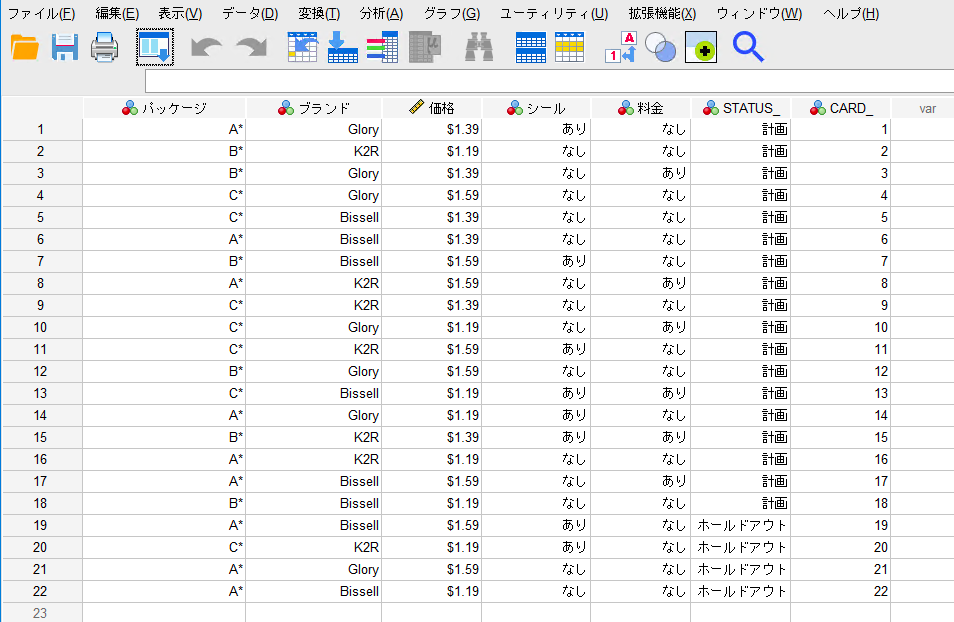
Windows「C:\Program Files\IBM\SPSS\Statistics\27\Samples\Japanese\carpet_plan.sav」
MacOS「/Applications/IBM/SPSS/Statistics/27/Samples/Japanese/carpet_plan.sav」
4. 回答結果からコンジョイント分析の実行
上記 3の直行計画で作成したコンジョイントカードでコンジョイント分析を実行するためには、IBM SPSS Statisticsに付属されている以下のファイルをご使用ください。
Windows「C:\Program Files\IBM\SPSS\Statistics\27\Samples\Japanese\carpet_prefs.sav」
MacOS「/Applications/IBM/SPSS/Statistics/27/Samples/Japanese/carpet_prefs.sav」
お客様のデータで分析される場合には、分析の目的に沿ったデータを事前にご用意していただけますようお願いいたします。
この例では10人の被験者にホールドアウトを含めた22個のコンジョイントカードを好みの順番で順位付けします。変数「PREF1」が最上位の組み合わせであるコンジョイントカードで、変数「PREF22」が最下位の組み合わせであるコンジョイントカードになります。
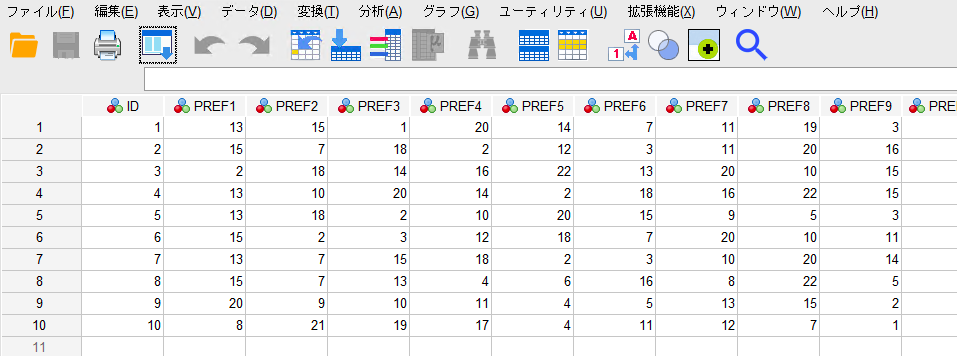
コンジョイント分析はシンタックスで実行する分析手法です。コンジョイント分析はGUIのダイアログから実行することが出来ません。そのためシンタックスを起動してコンジョイント分析のシンタックスを入力します。
1) メニューの[ファイル]→[新規作成]→[シンタックス]をクリックしてシンタックスエディタを起動します。
2) コンジョイント分析のシンタックスを入力します。
**********コンジョイント分析の構文 **********.
CONJOINT PLAN='(ここに直交計画のファイルを定義します)'
/DATA='(ここにデータファイルを定義します)'
/SEQUENCE=(データファイルにある最上位のカードの変数) TO (データファイルにある最下位のカードの変数)
/SUBJECT=(データファイルにあるID番号の変数)
/FACTORS=(ここに直交計画の因子を定義します)
/PRINT=SUMMARYONLY.
この例で使用するcarpet_plan.savとcarpet_prefs.sav'のシンタックスは以下の内容になります。
**********コンジョイント分析の構文**********.
CONJOINT PLAN='C:\Program Files\IBM\SPSS\Statistics\27\Samples\Japanese\carpet_plan.sav'
/DATA='C:\Program Files\IBM\SPSS\Statistics\27\Samples\Japanese\carpet_prefs.sav'
/SEQUENCE=PREF1 TO PREF22
/SUBJECT=ID
/FACTORS=外装 ブランド (DISCRETE)
価格 (LINEAR LESS)
シール (LINEAR MORE) 払戻し (LINEAR MORE)
/PRINT=SUMMARYONLY.
■ PLANサブコマンドには、この例の直交計画が入っているcarpet_plan.sav というファイルを指定します。
■ DATAサブコマンドには、この例の選好データが入っているcarpet_prefs.sav というファイルを指定します。選好データをアクティブなデータセットから選択する場合には、ファイル指定を「*」(引用符なし) に書き換えます。
■ SEQUENCEサブコマンドでは、選好データ中のデータ点を、一番好きなプロファイルから一番嫌いなプロファイルの順でふられた、プロファイル番号にすることを指定しています。
■ SUBJECTサブコマンドでは、ID 変数が被験者を識別していることを指定しています。
■ FACTORSサブコマンドでは、選好データと要因水準の予想される関係を記述するモデルを指定しています。ここで指定された要因は、PLANサブコマンドによって指定された計画ファイルの中で定義された変数を参照しています。
■ キーワードDISCRETEは、対応する要因水準がカテゴリで、水準とデータの関係について何の仮定も行わない場合に使われます。これは、パッケージ デザインおよびブランドを表す因子である、「パッケージ」と「ブランド」について当てはまります。4 つのラベル (DISCRETE、LINEAR、IDEAL、ANTIIDEAL) のいずれもついていない因子、もしくはFACTORSサブコマンドに含まれていない因子は、DISCRETEであると仮定されます。
■ 残りの要因に使われているキーワードLINEARは、データと要因の関係が線型であることを示しています。たとえば、選好と価格の関係は通常、線型であると予想されます。また、キーワードIDEALやANTIIDEAL(この例では使われていない) を使うと、2 次モデルも指定できます。
■ LINEARの後にくるキーワードMOREとLESSは、予想される関係の方向を示しています。ここでは、価格が低い商品ほど選好が高いと予想されるので、「価格」に対してキーワードLESSを使います。逆に、「シール」や返金保証に対する選好はより高いと予想されるので、「シール」や「払戻し」に対しては、キーワードMOREを使います (これらの要因の水準は、どちらも、「いいえ」が 1 で「はい」が2 に設定されている、ということを思い出してください)。MOREやLESSの指定が、係数の符号を変えたり、効用の推定に影響を与えたりすることはありません。これらのキーワードは、推定値が予想される方向と一致しない被験者を特定するために使われるだけです。同様に、ANTIIDEALの代わりにIDEALを選択しても、係数や効用に影響はありません。
■ PRINTサブコマンドでは、被験者のグループの情報をまとめたものだけを出力する (SUMMARYONLYキーワード) ように指定しています。各被験者固有の情報は、省略されます。
3) メニューの[ファイル]→[新規作成]→[シンタックス]をクリックしてシンタックスエディタを起動し、上記のシンタックスをコピーして貼り付け、シンタックスエディタのメニューの[実行]→[すべて]をクリックして実行します。
4) 実行をしますとコンジョイント分析の結果を出力します。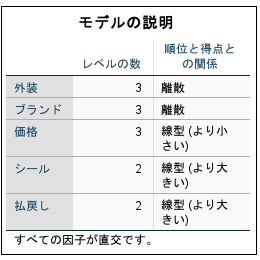
[モデルの説明]は 各因子のカテゴリ数(レベルの数)とカテゴリ値の属性を表示します。
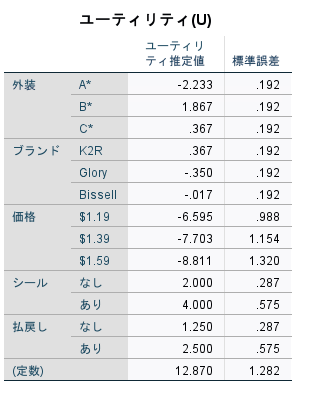
[ユーティリティ]は各要因水準の効用値 (部分効用) 得点と、標準誤差が表示されます。効用値が高いほど、その要因に対する選好が強いことを示します。 予想どおり、価格が高いほど効用は低くなっており (マイナスの値は効用が低いことを示す)、価格と効用の間には逆相関があることがわかります。 また、サービス シールや返金保証が高い効用に対応しているのも予想どおりです。
効用はすべて共通の単位で表現されるので、これを加算すると、任意の組み合わせに対する全効用が得られます。たとえば、パッケージ デザインが「B*」で、ブランドが「K2R」で、価格が「$1.19」で、サービス シールや返金保証のない洗剤の全効用は、utility(package B*) + utility(K2R) + utility($1.19)+ utility(no seal) + utility(no money-back) + constantまたは1.867 + 0.367 + (−6.595) + 2.000 + 1.250 + 12.870 = 11.759パッケージ デザインが「C*」で、ブランドが「Bissell」で、価格が「$1.59」で、サービス シールや返金保証のない洗剤の全効用は、0.367 + (−0.017) + (−8.811) + 4.000 + 2.500 + 12.870 = 10.909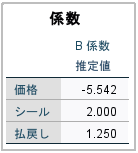
[係数]には、LINEARと指定された因子の線型回帰係数が表示されます (IDEALやANTIIDEALモデルの場合には、2 次の項も存在します)。特定の要因水準の効用は、この係数を水準に掛けることによって求められます。たとえば、この効用テーブルによると、価格 $1.19 の予想効用は −6.595 になります。これは、単に、価格水準の 1.19 に価格の係数 −5.542 を掛けただけの値です。

各因子の効用値の範囲 (最高から最低) は、その因子が全体の選好にとってどれだけ重要かを示す尺度となります。効用の範囲の大きい要因は、小さい要因に比べて、より重要な役割を演じます。
[重要度値]は、重要度得点 (値) と呼ばれる、各要因の相対重要度の尺度を提供します。この値は、各要因の効用の範囲を、全要因の効用範囲の和で割ることにより計算されます。したがって、この値はパーセントで表され、合計が 100 になるという性質があります。注意すべきなのは、この計算は、被験者ごとに別々に行われてから、全被験者の平均がとられるということです。直交計画の全効用や要約効用、回帰係数などが、SUBJECTサブコマンドの有無によって変わることはありませんが、重要度は通常大きく異なることに注意してください。SUBJECTサブコマンドのない要約結果の場合、重要度は、各被験者に対して計算する際と同じように、要約効用から直接計算することができます。SUBJECTサブコマンドが使われている場合には、各被験者の重要度の平均がとられ、一般にこの平均重要度は、要約効用を使って計算されたものと一致しません。この結果は、全体の選好に最も影響があるのは、パッケージ デザインであることを示しています。このことは、最も好まれるパッケージを含む製品プロファイルと、最も好まれないパッケージを含む製品プロファイルとの間の、選好の差が大きいということを意味しています。 さらに、この結果は、返金保証が全体の選好におよぼす役割は、最も重要性が低いということを示しています。価格は重要な役割を果たしますが、パッケージ デザインほどではありません。これは、価格の範囲がそれほど大きくないためと思われます。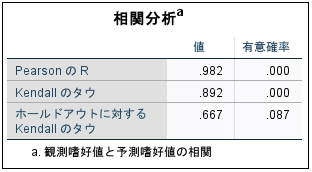
[相関分析]には、選好の観測値と予測値の間の相関を示す、Pearson のr と Kendall のタウという、2 つの統計量が表示されます。また、このテーブルには、ホールドアウト プロファイルのみを対象とする Kendall のタウも表示されます。ホールドアウト プロファイル(この例では 4 つ) は、被験者の評価は受けているけれども、効用を推定するためのコンジョイント分析手続きでは使われていない、ということを忘れないでください。コンジョイント分析手続きでは、効用の有効性のチェックとして、代わりに、ホールドアウト プロファイルのランク順の観測値と予測値の間の相関を計算します。コンジョイント分析の多くでは、パラメータの数と評価されるプロファイルの数が近いので、得点の観測値と予測値の相関が人為的に誇張されます。このような場合、ホールドアウト プロファイルの相関の方が、モデルの適合度をより適切に示していることがあります。ただし、ホールドアウトの相関係数は、常に、全体より低いことを忘れないでください。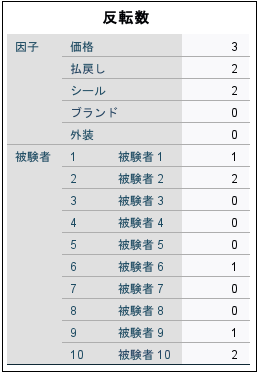
「価格」、「払戻し」、「シール」に対してLINEARモデルを指定した際に、変数の値とそれに対する選好との間の線型関係の、予想される方向(LESSもしくはMORE) を選択しました。コンジョイント分析手続きでは、価格が高いほど選好が高い、あるいは返金保証に対する選好が低い、というような、予想される関係とは逆の選好を持つ被験者の数を把握します。このようなケースは、リバーサル(反転)と呼ばれます。
[反転数]には、各要因および被験者ごとの、リバーサルの数が表示されます。 たとえば、「価格」についてリバーサルな被験者は 3 人います。つまり、彼らは、価格の高い製品プロファイルを好んでいることになります。
Was this topic helpful?
Document Information
Modified date:
06 August 2021
UID
ibm16478917