News
Abstract
SQE - Index Merge Ordering
Content
Index Merge Ordering (IMO) is an SQE enhancement to consider using an index for both selection and ordering for queries where rows are selected using something other than an equals predicate on one set of columns and the results are ordered by some other set of columns.
Example:
Before this change, the optimizer might use an index for selecting the rows (Carrier) or for ordering (MemberID), but never for both (Carrier and MemberID).
SELECT * from insurance_policies
WHERE Carrier IN (‘SFRochester’,’SFAustin’,’AAAMankato’,’SFMinneapolis’)
ORDER by MemberID
OPTIMIZE FOR 50 ROWS ONLY
Mostly likely to see performance improvements when:
1. The query is being optimized for First I/O which is generally used when an end user is waiting for the first set of results.
2. The result set is large.
3. An IMO eligible index exists. For the example above, the following multi-key index would need to exist for IMO to be considered.
CREATE INDEX Insurance_IMO ON insurance_policies(Carrier, MemberID)
Interested in more details?
Please keep in mind that the following criteria is subject to change based upon observations and insights learned from customer activity.
Prior to this enhancement, the query engine had two ways to implement ordering. It could use an index or a temporary sorted list. For certain queries, both of these techniques may not have resulted in satisfactory performance. For example:
SELECT INVOICE_ID
FROM SALES
WHERE COUNTRY <>’USA’ AND SUPPLIER_ID <> ‘ABC’
ORDER BY SALES_AMT
Note that this query has non-equal WHERE clause selection and is ordering by a column that is not referenced in the WHERE.
Also assume the following indexes are available:
- INDEX1 with keys of COUNTRY, SUPPLIER_ID, SALES_AMT
- INDEX2 with keys of SALES_AMT, SUPPLIER_ID, COUNTRY
The optimizer can use INDEX1 to perform selection on COUNTRY and SUPPLIER_ID, however since the selection is non-equal on the leading keys of the index, the rows are not returned in the correct order. The index will be used to build the sorted temporary list and then use a sorted temporary list scan data access method to retrieve the rows. If the answer set is fairly small after the selection is performed, this is a good implementation. However, if the answer set is large but the user requests only the first screen of rows to be returned (*FIRSTIO), this implementation will sort the entire answer set first before returning any rows to the user. In a real world example, the answer set was 12 million rows, but the application was only usually displaying the first 20 rows on the display. So, a lot of CPU and IO resource was used sorting the 12 million rows only to return the first 20 rows.
The optimizer can use INDEX2 to perform an index scan access method to retrieve the rows in SALES_AMT order since that is the first key of the index and then does key selection on the WHERE clause predicates. If the WHERE clause is rejecting many rows, but still selecting many rows, the key selection processing can be very expensive. Again, back to our real world example, the table had 1.8 billion rows, the answer set was 12 million but we only wanted 20 rows. So again, a lot of CPU and IO resource was to touch a lot of rows, only to reject them.
The new Index Merge Ordering implementation combines some of the characteristics of both the temporary sorted list and the index scan or index probe access together to overcome some of the problems discussed above.
To qualify for consideration of Index Merge Ordering, the query must meet the following criteria:
- Single table query. The table may be either partitioned or non-partitioned.
- The table size must be at least 500 million rows.
- The cardinality (number of distinct values) of the index keys of the index used for index merge ordering must be less than 1 million.
- The ratio of the cardinality in the previous bullet to the table size must be less than 1%.
- The query OPTIMIZATION_GOAL must be *FIRSTIO
- The query Allow Copy Data (ALWCPYDTA) option cannot be *NO and the query cursor cannot be declared as sensitive.
- The query cannot be scrollable.
The index merge ordering implementation is a plan that will be costed by the optimizer and its costs will be compared to the other available plan choices. If the cost of the index merge ordering plan is less any other plan it will be the plan used for query implementation.
The index merge ordering implementation can be identified in Visual Explain by the Index Merge Ordering Icon. Figure 1 shows an example of a Visual Explain of an index merge ordering plan.
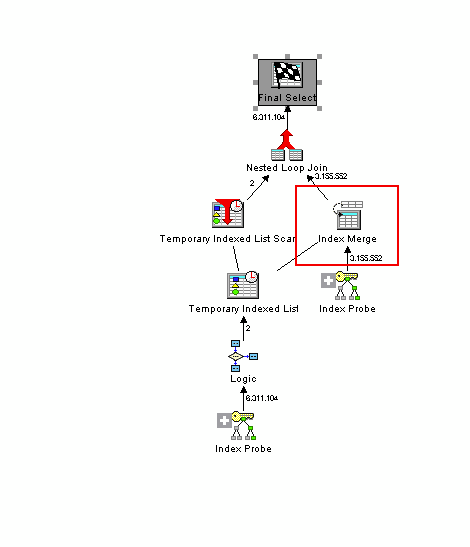
Figure 1. Example of an Index Merge Ordering node within Visual Explain
Index Merge Ordering usage is also indicated by reason code I6 in the QQRCOD of the 3001 record of the database monitor file or the plan cache snapshot.
Indexes are not advised for usage by Index Merge Ordering. There are some things to keep in mind when considering an indexing strategy that also takes into account Index Merge Ordering. The implementation creates a distinct list of keys after applying any query selection that can be done against the index and then re-probes the index to achieve ordering. In general, for an index to be eligible for Index Merge Ordering, the index should be created as follows:
- Any columns with equal predicates that are not in the ORDER BY list should be first keys in the index.
- Followed by any columns for non-equal predicates that are not in the ORDER BY list. The columns should be arranged so the most selective predicate column is the first column following the equal predicate columns.
- Followed by the ORDER BY columns in the same order as the ORDER BY clause of the query and with the same ASC or DESC attribute
- Optionally, at the end you may include other selection columns or other selected columns for Index Only Access.
For example:
SELECT INVOICE_ID, SALES_AMT
FROM SALES
WHERE COUNTRY <>’USA’ AND SUPPLIER_ID <> ‘ABC’
ORDER BY SALES_AMT
The Index to create would be with keys:
- COUNTRY, SUPPLIER_ID, SALES_AMT
In order to allow a more general indexing scheme, it is possible to use an index for index merge ordering even if there are leading keys not used in the query. The above index could also be used for the following query:
SELECT INVOICE_ID, SALES_AMT
FROM SALES
WHERE SUPPLIER_ID <> ‘ABC’
ORDER BY SALES_AMT
If INVOICE_ID was added as a trailing key, then Index Only Access would be used for both queries.
CREATE INDEX SALES_IMOX ON SALES (COUNTRY, SUPPLIER_ID, SALES_AMT, INVOICE_ID)
In a sample run of a query, where the table and index was resident in memory.
Select shipmode from item_fact
where SHIPMODE = 'TURTLE' or Shipmode='SNAIL'
Order by Orderdate optimize for 30 rows;
The IndexScan plan ran in 53.49 seconds. When Index Merge Ordering was enabled, the same query ran in .02 seconds. This very simple example shows that for the right query Index Merge Ordering can significantly improve performance.
The SQE query engine now has another tool in its toolbox to help queries perform better.
For the right query and with some index tuning, significant performance gains can be seen by using Index Merge Ordering.
Was this topic helpful?
Document Information
Modified date:
21 January 2020
UID
ibm11168228