Summary of the Important New Features
Available with VIOS 2.2.5 – Generally Available from November 2016
- SSP VIOS nodes from 16 VIOS to 24 VIOS. Most servers operate in the dual VIOS per server mode so the result is 12 servers running as a cooperating cluster.
- Fully support the SSP Disaster Recovery software that was first released on IBM DeveloperWorks - now as part of the VIOS code.
- RAS (Reliable, Available & Serviceable)
- • Cluster Wide Snap Automation – Useful for problem determination.
- • Asymmetric Network Handling – SSP stability during network issues.
- • Lease by Clock Tick – So you can change VIOS date & time without side effects.
- HMC further GUI support for SSP -arrives with HMC release 860.
- HMC Performance & Capacity Metrics including SSP Performance stats.
- List LUs not mapped to a VM - new "lu" command option.
Details of the Important New Features
1 Increased the maximum SSP VIOS nodes from 16 VIOS to 24 VIOS
In practice:
- With the normal dual Virtual I/O Servers configuration, the maximum is 12 Power Servers in an SSP cluster
- Live Partition Mobility within the 12 Servers
Need more than 24 VIOS in a single SSP cluster? Here are a few ideas:
- Use more than 1 SSP by grouping similar Power Servers together
- If you have VIOS pairs for Production and other pairs for say Test or Development on each Power Server, then you could go for a Production SSP and a Test or Development SSP. Each VIOS pair in each Power Server can be in a different SSP. Put another way a single Power Server can be in two different SSP clusters by using different VIOS pairs.
- This limit of 24 VIOS limits the "failure domain" - I would not want all my 1000's of virtual machine to rely on just a single distributed file system. In the unlikely event of an SSP outage, too much would stop in one hit.
- But systems administration people always want more! What number would you like? Some wise crack in London suggested "unlimited."
- The limit is there as a Testing and Supported limit.
- The VIOS team heavily test at extreme disk I/O and network I/O levels up to this limit so it represents a large investment for this high I/O test case. I would not expect many SSPs to be operating at such high I/O levels but to offer official Support it has to be tested for any unexpected bottlenecks or serialisation points in the code.
Nigel Notes:
- This 24 node limit is not a built-in, hardcoded, or an enforced limit. I was running 19 VIOS for 18 months when the limit was 16 VIOS - I just knew I could not raise a PMR and could not get IBM Support.
- On low I/O rates SSP (like my crash and burn lab servers) you can go to higher than 24! Warning: more than 24 is not supported, so do not raise a PMR on such a configuration.
- On high I/O rate driven through an SSP - I would watch those VIOS resources like:
- VIOS CPU: Nigel's recommendation is minimum entitlement=2, virtual processors=3
- VIOS memory: Nigel's recommendation is minimum 6GB but 8GB is better)
- VIOS disk adapters: Nigel's minimum 2 dual port adapters = 4 ports with multi-pathing.
- VIOS network upgrade: Consider a dedicated to inter-VIOS traffic network and 1 Gbps moving to 10 Gbps now or planning for 2017)
- Run the VIOS "part" command on all VIOS during your busy hour every week and check the results monthly.
Result: Larger SSP clusters, Tested to higher I/O rates, and increased flexibility.
2 Official Support for the DeveloperWorks SSP Disaster Recovery method
The code was available for a few years from the old IBM DeveloperWorkswebsite and supported on a "best effort" basis from the developers and works fine in my experience and reports from other testers.
Here it is assumed your SAN team and infrastructure can create a point in time copy of the SSP LUNs at a remote location on different disks. On a site loss, you get your virtual machine disks back by starting the SSP on a different set of VIOS on alternative Power servers. The problem is the VIOS looks at the disks and refuse to work with them as they see it as "not their SSP". The trick is to have an SSP configuration backup file. A script changes the names of the VIOS that are part of the SSP inside the backup file. Now, when that backup is recovered, your new VIOS does think it is a member of the SSP and happily joins or starts the SSP. With some preparation, the script can automatically map the virtual disk LUs to a newly created set of virtual machines. Finally, you are ready to be started up the virtual machines and continue the service.
See my YouTube Video on this topic: SSP Remote Pool Copy Activation for Disaster Recovery
The "viosbr" (VIOS backup and restore command) has extra option to support these new functions:
$ viosbr Usage: viosbr -backup -file FileName [-frequency daily|weekly|monthly [-numfiles fileCount]] viosbr -backup -clustername clusterName -file FileName [-frequency daily|weekly|monthly [-numfiles fileCount]] viosbr -nobackup viosbr -view -file FileName [ [-type devType] [-detail] | [-mapping] ] viosbr -view -file FileName -clustername clusterName [ [-type devType] [-detail] | [-mapping] ] viosbr -view -list [UserDir] viosbr -restore -file FileName [-validate | -inter] [-type devType] [-skipdevattr] viosbr -restore -file FileName [-type devType] [-force] viosbr -restore -file FileName -skipcluster viosbr -restore -clustername clusterName -file FileName -skipdevattr viosbr -restore -clustername clusterName -file FileName [-subfile NodeFile] [-validate | -inter | -force][-type devType][-skipcluster][-skipdevattr] viosbr -restore -clustername clusterName -file FileName -repopvs list_of_disks [-validate | -inter | -force][-type devType][-db] viosbr -restore -clustername clusterName -file FileName [-subfile NodeFile] -xmlvtds viosbr -dr -clustername clusterName -file FileName -type devType -typeInputs name:value [,...] -repopvs list_of_disks [-db] viosbr -recoverdb -clustername clusterName [ -file FileName ] viosbr -migrate -file FileName viosbr -autobackup {start | stop | status} [ -type {cluster | node} ] viosbr -autobackup save $
UPDATE: From what I can see, the VIOS SSP backup fix-up script is now handled by the viosbr -dr command option (which is excellent). The tiny software fix that you needed to install is already installed with the VIOS. Both updated are good ideas so that functions integrated in the normal VIOS software.
Result: more confidence in setting up and using the remote DR for the whole pool feature.
3 RAS improvements
These features show that the Shared Storage Pool is reaching maturity. The Support Team reviews common issues that they hit with real-life customers and look for ways to eliminate them or reduce the damage by keeping the SSP running. Here we have the top three that are visible to SSP administrators. I know of about half a dozen other improvements internally (these changes are not shared publicly), mostly because they require an understanding of the code itself.
There are large numbers of Shared Storage Pools in use today and lots of them are fully production use. I get rather annoyed when asked "Yes but how many are in production? Suggesting it is a tiny number. I would guess there are thousands in FULL PRODUCTION USE. It is difficult to get a hard number as it is a zero cost feature within your VIOS and a PowerVM component. As IBM does not charge for it separately, so we can't track it.
I would guesstimate: We are in the many tens of thousands of VIOS running SSP with many 1,000's in production.
Here is a hard number: 20 thousand views of my SSP YouTube Videos (up to March 2020)
The two main videos take 1.5 hours to watch each. Many people are serious about their Shared Storage Pool. Not all SSP users watch my videos as there many alternatives like internal to IBM courses, external training, Lab Services, and Technical University sessions to start learning about SSP.
3a Cluster-wide snap automation
It seems that the first Support response to a PMR is: “Can we have a snap? Problem diagnostics data.”
With SSP, we are operating a cluster, so the issue might be on any VIOS or the interaction between them.
Capturing 16 (or now 24) snaps are
- Difficult at the same point in time
- Time consuming bringing many 1 - 3 GB files to one place.
This command collects snap data from every node in the SSP cluster at the same time and creates a single compresses file on the node that the command was run. Only one can run at a time (that is, they are coordinated)
In brief the Syntax:
clffdc -c TYPE [-p priority] [-v verbosity] “cluster first failure data capture” -p 1|2|3 1=high priority -v 0|1 1=more information -c TYPEs are FULL | CAA | RSCT | VIOS | POOL | PHA (PowerHA)
Output goes to:
/home/ios/logs/ssp_ffdc
Filename:
csnap_date_time_by_component_priority_ccorrelator.tar.gz
Example: all data and priority=medium, as padmin:
clffdc -c FULL -p 2
Two VIOS Nodes that are recently installed, small & simple config took 5 minutes.
# oem_setup_env ; cd /home/ios/logs/ssp_ffdc # du -ks * ? while running 4140 snap_20161022_064111_by_vios_Med_c1.tar.gz 3412 snap_20161022_064408_by_vios_Med_c1.tar.gz 4420 snap_20161022_064908_by_vios_Med_c1.tar.gz 150228 snap_20161022_070336_by_full_Med_c2
Last one is a large directory of files during collection
Once done:
# ls -s csnap*full* 77624 csnap_20161022_071142_by_full_Med_c2.tar.gz
In total just 77 MB. This example is from a brand new VIOS code installation with small log files. Normally, I would expect a 1.5 GB per VIOS or higher.
Result: Less VIOS / SSP administration time and better problem determination at the first attempt.
3b Asymmetric network handling - a new internal algorithm
All VIOS in the SSP cluster is equal except one or two have special temporary roles. These role are extra tasks to perform on behalf of the whole cluster. For example, if VIOS with a role is shutdown by the administrator, the role gets passed to another VIOS. One such role is the cluster managing node.
Normally, a managing node decides
- Which VIOS is in the cluster,
- Which gets expelled &
- Which VIOS can join
Rare condition: cluster manager has a partial network issue and can communicate with some nodes but not all nodes. This problem is called an asymmetric network. In the past, failed communication from the managing node to another node or nodes would result is all those VIOS being expelled. Now the manager node double checks if the other (good communicating nodes) can talk to each other (non-communicating nodes). If a good number of virtual I/O servers can talk, then the managing VIOS node works out that itself might be the problem (or its part of the network). In this failure case, the managing node can hand over the managing role to an alternative node.
OK there is nothing the SSP Admin needs to do here but it is good to know SSP has your back when you have network problems.
Result: during flaky network issues, we get fewer unnecessary expelled nodes = SSP stability While you fix the network.
3c Lease by clock tick
I did not understand this one so a kind SSP developer explained it:
These leases are related to heartbeats and data integrity. One of the key things to guard against in a cluster is a node that looks dead but isn't dead. In other words, if a node stops responding to heartbeats for a time, the other nodes (eventually) assumes it is dead. They expel it, which removes it from the list of nodes they need to coordinate with. If that node isn't dead but dormant for an extended time, then when it comes back it:
- Has no idea what it missed while it was gone and
- Isn't being included in the messages that other nodes are exchanging.
It has outdated information and is therefore not in any fit state to touch the shared disks in the pool.
In previous SSP releases changing the date or time, results in time jumps making the node think it was dormant (possibly stuck in kdb (kernel debugger), possibly a victim of extreme CPU starvation, etc). It immediately expels itself (at a high interrupt level) before it has any chance to accidentally touch the shared disks in the pool as it could be using out-of-date information.
Once at VIOS 2.2.5 + 1st service pack, you can change the date or time at any . . . time!
Previously, you had to offline the VIOS & client LUs as follows:
clstartstop -stop -m $(hostname)
Next, change the date or time and then add the node back into the SSP with:
clstartstop -start -m $(hostname)
Result: I suspect many people don't know or forget to use clstartstop. From VIOS 2.2.5 release on-wards, this problem is not an issue.
4 HMC 860 graphical user interface Enhanced+ adds more SSP management features
Here are a few samples of the new HMC view of SSP resources
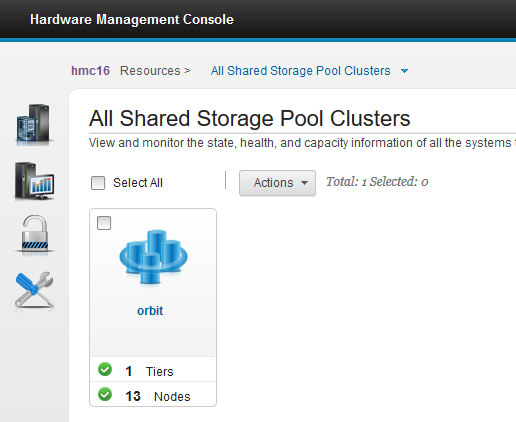
The following picture shows a pool and the virtual I/O Servers in the cluster:
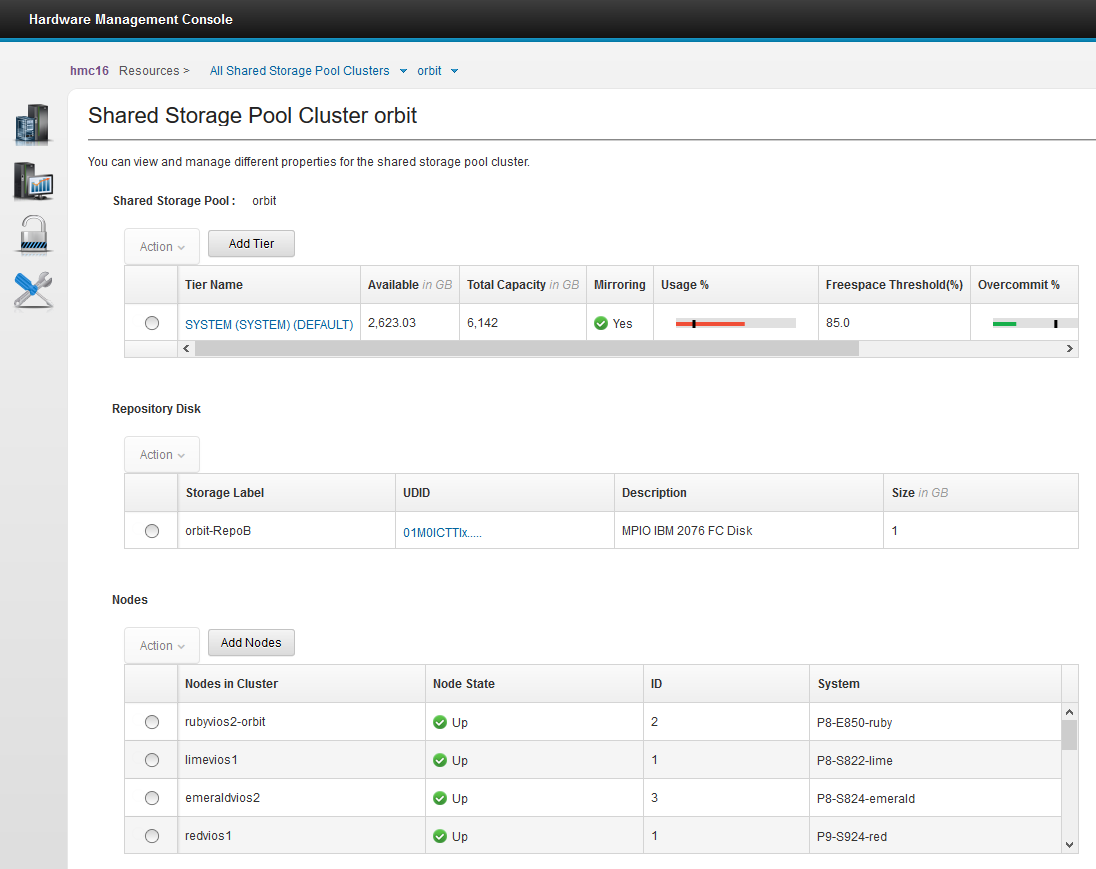
The following picture shows the LUN disks mounted on every virtual I/O server that is backing up the SSP virtual LU disks.
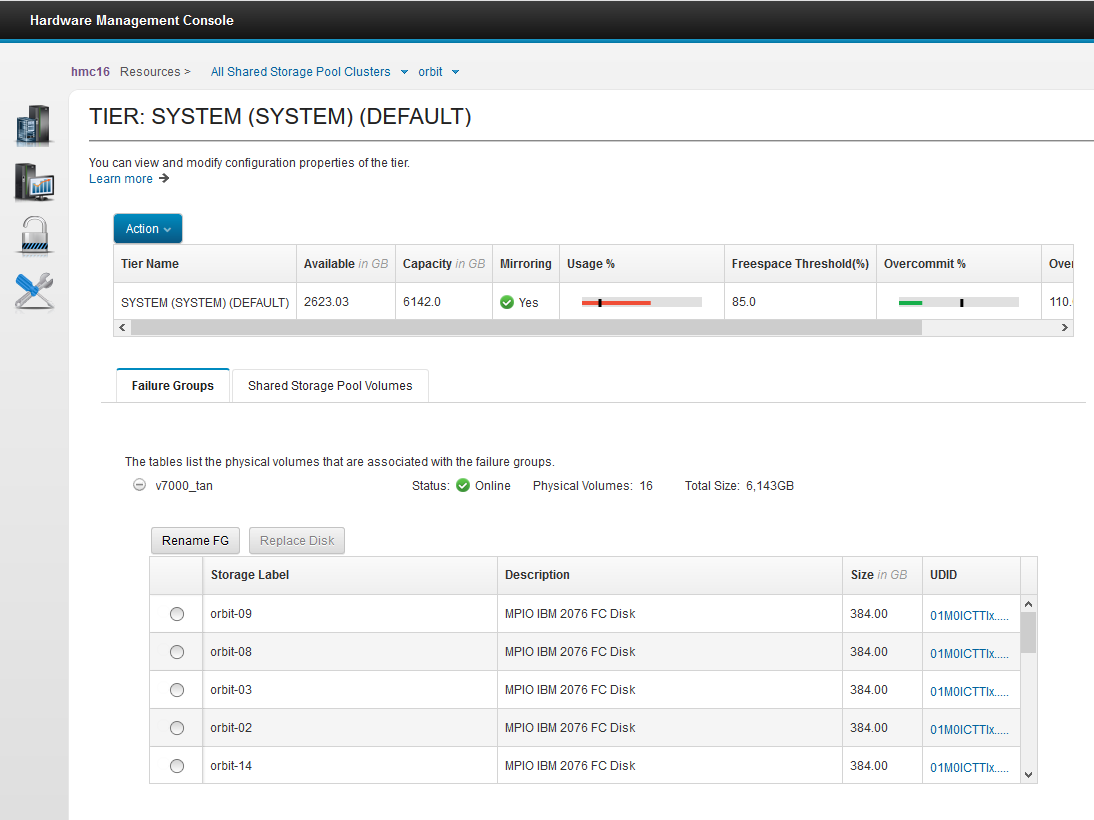
The following picture shows the virtual LU disks and assigned virtual servers:
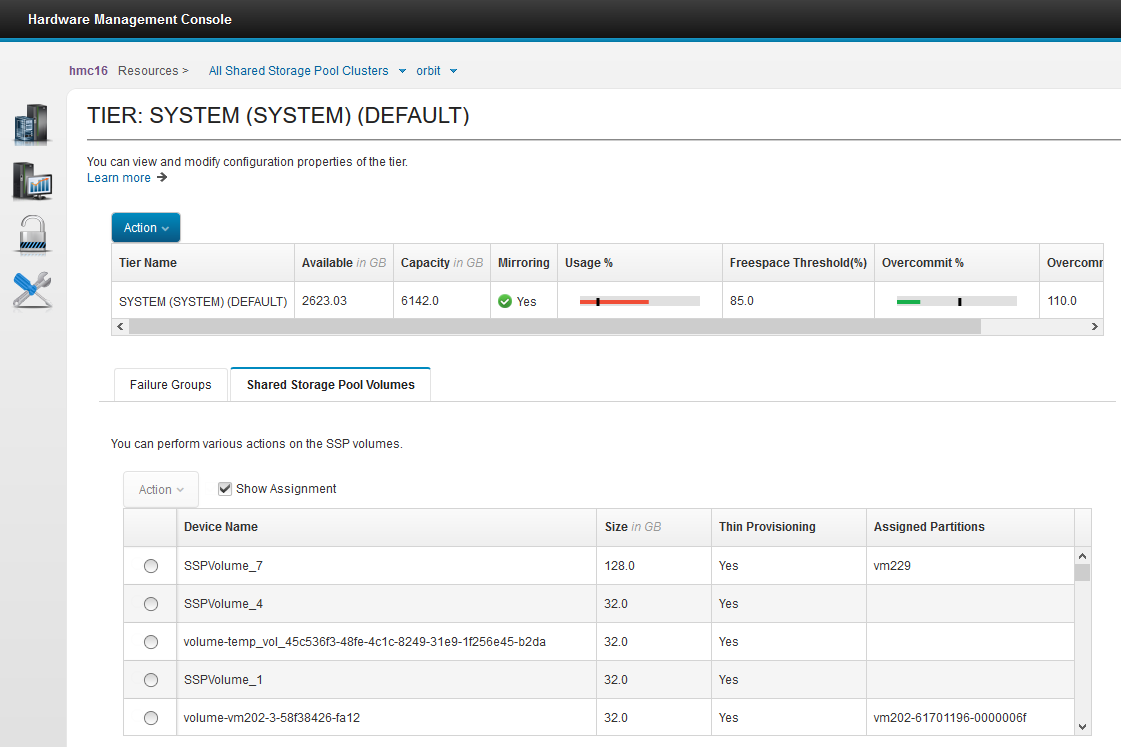
But the HMC Enhanced+ view includes many SSP features.
Result: Saves Admin time and it means you don't need to log on to a VIOS to see your SSP configuration or make changes.
5 HMC Performance and Capacity Metrics (PCM) for SSP and REST API
This topic is covered in other AIXpert Blogs. This feature includes dozens of SSP stats so that you can see, for example, the total I/O going to and from your SSP pool as a whole. The format is in JSON format. JSON format is best use, restructure, and graphed in the Python language. From samples of the data, there are the following performance stats:
SSP and tier level stats
- Name of SSP or Tier
- Size
- Free
- Number of Reads
- Number of Read Transfers
- Number of Read Request Timeouts
- Number of Read Request Failures
- Number of Writes
- Number of Write Transfers
- Number of Write Request Timeouts
- Number of Write Request Failures
- Read Bytes
- Write Bytes
- Read Service Time
- Min read Service Time
- Max read Service Time
- Write Service Time
- Min write Service Time
- Max write Service Time
Then, for each LUN in the SSP. There might be far too stats for normal users but too many is better than too few.
Result: Loads of stats to collect, graph, and think about - these stats give SSP administrators insight in to what the SSP is up too and warning about the future (SSP filling up or becoming over worked).
6 Listing mapped and unmapped to virtual machines LUs
In the following sample code, if you say "mapped", when you read the word "provisioned" then you can work out what it does!
$ lu -list -attr provisioned=false = Not mapped to any VM POOL_NAME: spiral TIER_NAME: SYSTEM LU_NAME SIZE(MB) UNUSED(MB) UDID test2 32768 0 9719c043c90a91d434178a test4 32768 0 79772efe7e54f79af7af67 test6 32768 0 6b8048273cebd7357bd658 $ lu -list -attr provisioned=true = Is mapped to a VM POOL_NAME: spiral TIER_NAME: SYSTEM LU_NAME SIZE(MB) UNUSED(MB) UDID test3 32768 0 25de85f8af711f93a7a288 test5 32768 0 8868ec547808deeba80398 $
Unfortunately it does not say on which VIOS the LUs are mapped (mounted) that is "test3" and "test5"
See my nmap script for that mapping can be found. See the AIXpert Blog: Shared Storage Pools Hands-On Fun with Virtual Disks (LU) by Example
Result: Administrators performing regular maintenance can quickly determine unmapped LUs. This unmapping could be a mistake that needs investigating. Alternatively, the unmapping might be due to disks from deleted virtual machines and the disk space could be released back to the SSP.
7 Secret SSP performance booster
This feature was released in 2017. This VIOS SSP performance booster is based on the AIX Flash Cache technology to accelerate the VIOS client disk access. This feature requires SSD hardware within each VIOS.
Results: a large performance jump for disk I/O intensive workloads with minimum SSP administrator setup.
- - - The End - - -
