Troubleshooting
Problem
Loading large amount of data can take some time on iBase. This document in intended to help solve commonly seen performance issues when loading data into iBase. It assumes that you are already familiar with iBase schemas and importing. It is only relevant for SQL Server databases and applies equally to standard or bulk insert configurations.
Symptom
When loading large amount of data, the number of records loaded per second slowly decrease.
Cause
The Indexes are not optimized on the SQL server tables.
For example, in a Communication link, you would have fields like :

You can see that there are 4 indexes, and 3 discriminator fields.
This means that when a new data will be loaded into iBase, iBase will check if there is already a record with the same :
- Call Date
- Call Hour
- Call type
- and of course, the same records as End 1 and End 2.
But to do this, SQL Server will have to go and look through 3 indexes (Call Date, Call Hour and Call Type).
This is not optimized, as you might have several thousand calls on a given day, several other thousand on a given time of the day (say 13:40:21), and at last, several hundred thousand calls with the same type (Voice; SMS; Data)
The optimized way would be to have, added to the current existing indexes, a new compound index that would have the 3 fields compound.
Like, this, iBase would go directly into this index to see if there is already a call that is, for example :
- Call Date = 03/07/2016
AND
- Call Hour = 20:55:12
AND
- Call Type = Voice
Environment
iBase database on an SQL Server.
Resolving The Problem
Use Compound Indexes
Lack of Compound Indexes in iBase
When setting up discriminators in iBase Designer, iBase will create an individual index for each field. When loading data into SQL Server or querying constraints on multiple fields, the optimizer will choose one of these and use that. Sometimes this may work fine if the index chose is highly selective in terms of what is returned. However, more likely you will see sub optimal performance as a hit in index will necessitate a seek on the table data which may have to process many rows to find matches for both discriminators.
How iBase Creates an Index for a Field
Although iBase cannot create a compound index that contains multiple fields, in fact all iBase indexes created against fields are compound as they include:-
- the column for the field in question
- the Unique_Id column (iBase identifier) which holds the iBase identifier for the item
- the Record_Status column which is a flag indicating whether an item has been deleted
For example, looking at the index on the Number field on the telephone entity in the User_Guide database in SQL Management Studio shows:

Apply the Same Pattern to Compound Index
When building a compound index, we want to apply the same patter to the new index. As an example for the User Guide database, we will create a compound index on the Account Number and Sort Code fields for the Account entity.
Note that the ordering of the columns in the index is very important. The fields you are indexing are always first, with the most selective (most number of unique values) first. This is then followed by the Unique_Id and finally the Record_Status field.
In the case of Account discriminators, the more selective field is Account Number, so, our index will be:
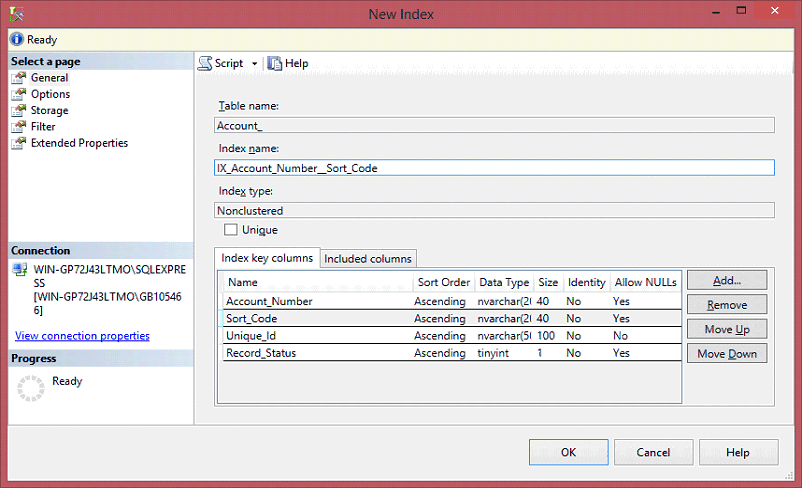
The index will be Nonclustered and should have the Unique checkbox unchecked as show.
WARNING : Do NOT remove the other existing indexes ! !
Other tips for Performance Improvement
- Set the SQL Server recovery model to Simple or Bulk Logged. It can be switched to Full when the data is loaded if necessary.
- Do not use Append Only Text Fields
- Ideally collocate Bulk Insert folder, the iBase scheduler and the database on the same server, using local drives.
- Consider using Microsoft's SSIS (or any other ETL software) to load into a staging database and then load from there into iBase. This is much more complex but can in result in a faster, more robust system.
- If loading from database, consider using SELECT DISTINCT to remove duplicates prior to loading
- Consider turning off check for matching entities. Only do this if:-
o It is the initial load
o You are sure your load contains no duplicates
Was this topic helpful?
Document Information
Modified date:
16 June 2018
UID
swg21983968