Installing IBM Big SQL Sandbox
The IBM Big SQL Sandbox is a light-weight, non-production version of Big SQL that you can install on your own laptop and use to explore Big SQL and try out your own queries. This offering is not intended for a multi-node environment.
The Big SQL Sandbox has the following system requirements:
- Operating system
-
Mac OS X Yosemite 10.10.3 or later, Windows 10 Enterprise, Education, or Pro, and Windows 7 (all versions that allow Hyper-V)
- Hardware
-
4 processor cores
At least 12 GB of RAM and 16 GB of free disk space
Before you start
If you use Windows 7, enable Virtualization Technology (VT-X) in the BIOS of your computer.
If you use an older toolbox-based version of Docker, uninstall it before you install the Sandbox application.
If you have other containers that run on your computer, stop them before you install the Sandbox application because your computer might have resource constraints.
How to get started
- Download the exe or dmg file (installation setup) on your laptop from the IBM Big SQL Marketplace web page.
-
Start the wizard, and then let the installer download the image from Docker for you. You might be prompted to create a Docker Cloud account and to change the Docker settings. This download step can take 15 to 40 minutes, depending on your connection speed.
When the installation completes, you will see the following screen.
Figure 1. IBM Big SQL Sandbox installer final screen 
- Get started. You can log into the Apache Ambari dashboard to view the services in your cluster,
or you can log in to Apache Zeppelin to explore the sample notebooks. You can click either of the
two icons now, but it takes a few minutes for all of the services to start. Then, you can start
exploring IBM Big
SQL.
In both cases, your login credentials are: username admin and password admin.
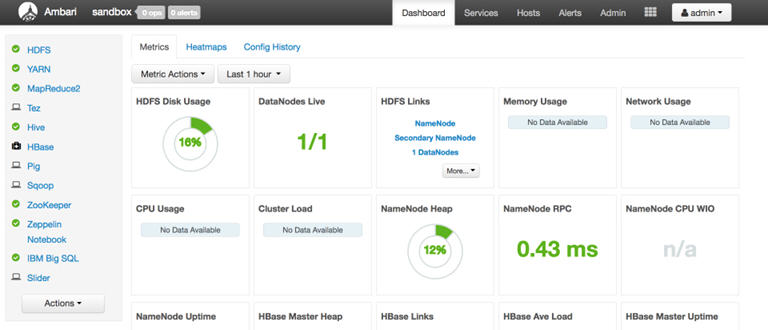
Ambari dashboard
If you open the Apache Ambari dashboard, you can provision, manage, and monitor Hadoop clusters, including the following tasks:
- Installing Hadoop services.
- Stopping, starting, and reconfiguring Hadoop services.
- Monitor the health and status of a cluster.
- Collect metrics on a cluster.
- System alerting that notifies you when your attention is needed.
Zeppelin notebooks
From the Apache Zeppelin page, first, be sure to log in as admin/admin.

After you log in, you can see the sample notebooks that we provide to help you get started.
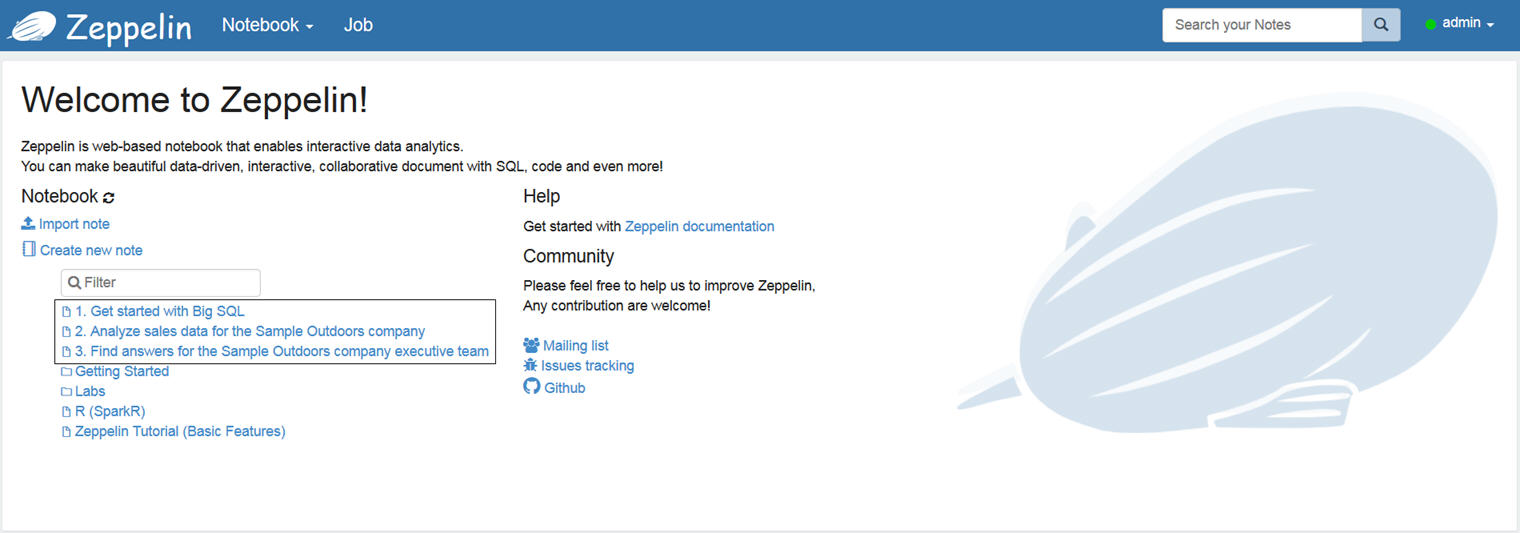
The Markdown and JDBC interpreters are already set for these three notebooks, so you can use these notebooks immediately. The tables you need to work with the notebooks are provided in the sandbox.
- Sample 1. Get started with Big SQL
-
Time required: About 3 minutes
This notebook introduces the other two notebooks and provides links to videos about Big SQL.
- Sample 2. Analyze sales data for the Sample Outdoors company
-
Time required: About 40 minutes
Use this notebook to get up to speed with Big SQL by learning how to use SQL queries to answer business questions. In this notebook, John, a business analyst at the Sample Outdoors company, is asked to provide a report that answers two important questions:
- Which are the top-selling products so that John’s team can advertise and maintain proper inventory of these products?
- Which sales channel is generating the most revenue so that John’s team can make intelligent investments in the proper channels?
- Sample 3. Find answers for the Sample Outdoors company executive team
-
Time required: About 60 minutes
Create your own Big SQL queries. After you complete Analyze sales data for the Sample Outdoors company, it’s now your turn to be a business analyst and provide answers to the Sample Outdoors company executive team.
Don't worry, we provide hints inside the notebook and a link to a cheat sheet if you get stuck!
Uninstalling the IBM Big SQL Sandbox
To uninstall the IBM Big SQL Sandbox, click from the installer. The installer uninstalls the Docker image. Then, to uninstall the installer, go to your applications folder and uninstall it.
Learn more
If you have any problems, ask your questions and join the conversation on our monitored Big SQL Sandbox forum.