The sync job
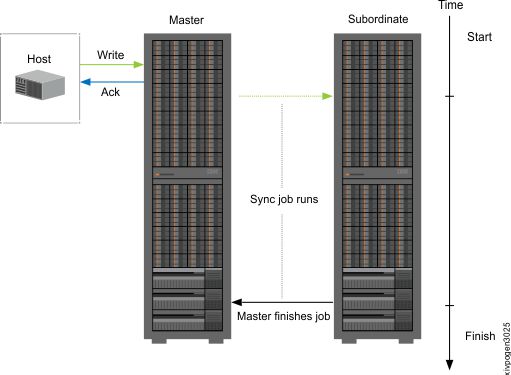
Data synchronization between the master and slave is achieved through a process run by the master called a Sync Job.
The Sync Job updates the slave with any data that was recorded on the master since the latest Sync Job was created. The process can either be started automatically based on a user-configurable schedule, or manually based on a user-issued command.
Calculating the data to be replicated as part of the Sync Job
When the Sync Job is started, a snapshot of the master's state at that time is taken (the most_recent_snapshot).
After any outstanding Sync Job are completed, the system calculates the data differences between this snapshot and the most recent master snapshot that corresponds with a consistent replica on the slave (the last_replicated_snapshot). This difference constitutes the data to be replicated next by the Sync Job.
The replication is very efficient because it only copies data differences between mirroring peers. For example, if only a single block was changed on the master, only a single block will be replicated to the slave.