IBM Research
日本発のテキストマイニング技術で企業の眠れるデータを燃料に
2018年7月30日
カテゴリー IBM Research
記事をシェアする:
 2017年度「業績賞」受賞者(左後ろから)那須川 哲哉、吉田 一星、金山 博、米谷 雅樹、宅間 大介
2017年度「業績賞」受賞者(左後ろから)那須川 哲哉、吉田 一星、金山 博、米谷 雅樹、宅間 大介
企業のデジタル・トランスフォーメーション(DX)の必要性が叫ばれる昨今、データがDXをすすめるための「燃料」となる。2017年のIDC Japanの予測によれば、2025年には、全世界で発生するデータが2016年比で約10倍の163ゼッタバイト(163兆ギガバイト)になる中、大量のデータの有効活用はどの企業においても悩みのタネであると同時に成長のタネとも言えるだろう。当然、企業が使えるデータが多ければ多いほど企業価値向上につながる一方、膨大なデータ量を処理しきれず、有効活用されずに放置されてしまうことが実は多いのではないだろうか。そのような企業のデータ活用における課題の解決に大きく寄与するのが、IBM Researchが研究開発を行うテキストマイニングの技術だ。
今回、そのIBMのテキストマイニング技術の情報処理学会における2017年度「業績賞」受賞にあたり、技術研究をリードするIBM Researchの研究グループを代表して、東京基礎研究所/シニア・テクニカル・スタッフ・メンバー 那須川に、当技術研究の意義と今後の展望について聞いた。
取材・文:安原 美理、写真:芋岡 祥子
——改めてテキストマイニング技術とはどんな技術か教えてください。
那須川:テキストマイニング技術とは、人が読みきれない大量のデータから知見を得るための技術です。例えばお客様に実施したアンケートを一つひとつ読めば個別の意見の内容は理解できますが、特定の意見が、多数派なのかそれとも少数派なのか、または年々多くなっているのか少なくなっているのかといった、傾向や特筆すべきポイントなどの特定については、データ全体を把握する必要があり、データの量が多くなればなるほど人間には処理しきれなくなります。そのような人間が到底処理できない量のデータから企業の成長につながる重要な知見を導き出す点にこの技術の意義があります。
——IBMのテキストマイニング技術の特長はどんなところですか?
那須川:IBMのテキストマイニングの大きな特長は、多言語対応も含めた高度な自然言語処理と、大量データのインタラクティブな分析を高速に実現するインデックス機能の二点です。
まず、もともと自然言語開発の分野に強みを持つIBMは、テキストマイニング技術の開発に1997年から着手し、数十件に及ぶ発明を行っています。
1998年に、日本において数十万件規模の社内のコールセンターのデータを分析対象としたテキストマイニングのシステムを開発しTAKMI(タクミ)と名付けました。英語のテキストも分析できるようにして米国のコールセンターなどIBMグローバル全体で使い、さらにお客様にもご活用いただきながら機能を高めていきました。
テキストから抽出したキーワードを統計解析ツールで分析すればテキストマイニングになると思われるかも知れませんが、同じ言葉でも多様な解釈が可能なため、原文とキーワードを切り離してしまうと、文書やテキストデータの意図を誤って推論・分析をする危険性が高くなります。そのため、統計解析対象の表現を常に原文と結びつけておくインデックス構造が重要であり、さらに、数百万件規模のテキストデータをストレスのない速度でインタラクティブに分析できるようにしているのが、我々の技術の特長です。言語処理的には、好不評を示す表現を精度良く特定したり、不具合を示す表現の候補を抽出したりする機能などを具えています。
現在は、Watson Explorer Deep Analytics Edition(以下WEX)という名称で製品化されており、17言語に対応しています。特に日本発の技術であるからこそ日本語にもっとも強いため、日本におけるユースケースが多いのも大きな特長のひとつです。
ビジネスユースケースとしては、金融、製造、流通、医療など多岐にわたる業界ですでにお使いいただいていて、同じ業界のなかでも、カスタマー・ケア、製品サービスの品質管理、マーケティングなど、さまざまな適用事例が広がっています。
最近では、特許の分析をする企業が増えてきていて、例えば、業界の技術動向を把握したり、提携先を探したりするような活用も進んでいます。
——受賞チームについて教えてください。
那須川:今回受賞対象となった業績は「テキストマイニング技術の実用化及びその多言語化と国際的な普及」であり、技術開発や製品化に加え、活用して成果を出し、普及させるまでの幅広い活動が対象となっています。その観点から、今回受賞させていただいた5名は代表者であって、この賞は、IBMでテキストマイニング関連の活動に関与している全ての人に贈られたものだと考えています。
東京基礎研究所でテキストマイニング関係のコア技術を研究開発しているメンバーは、自然言語処理や数理科学のエキスパートで、十名前後なのですが、開発部門では、数十名規模のメンバーが、我々のテキストマイニング技術をWEXを代表とする製品に作りこんでくれています。代表者としての受賞メンバーのうち、2名は開発部門の所属(受賞時)です。また、テキストマイニング技術の実用化と普及という観点からは、営業部門やサービス部門など、非常に多くのIBM社員が関与してくださっています。
実は、我々が生み出したテキストマイニングの技術を理解し活用してもらうため、2011年から日本IBM内にテキストマイニングのコミュニティーを立ち上げたのですが、ここには、のべ数百名規模のIBM社員が様々な部門から参加してくれています。さらに、WEXを海外で展開してくれているグローバルのIBM社員のメンバーの規模はそれを2-3桁上回る数になります。
今回の「業績賞」受賞は、IBMという組織をフルに活かした取り組みの結果とも言えると思います。
——今回の受賞の意義や今後の展望について聞かせてください。
那須川:IBM Researchでは、アカデミアでの認知に非常に力を入れています。アカデミアでの高い評価が結果的にお客様への最高峰の技術の提供につながると考えるからです。但し、これがゴールではありませんので、この受賞を励みに、さらなる機能強化や普及に努めていきます。
テキストマイニングの技術については特に、お客様によろこんでいただけるため非常にやりがいを感じています。新しい技術やツールを導入すると、初めのうちは、かえって面倒になったり、プロセスが増えてしまったりして、拒否反応を示すユーザーも少なからずいます。また、近年はAIに仕事が奪われることを不安に思う人も多いようです。一方、テキストマイニングの技術に関しては、人間がやっていることを自動化するというというよりは、人が読みきれない大量のテキストの情報を活用可能にするという点で、そもそも人間ができないことを実現するものです。言わば、Augmented Intelligence(拡張知能)の技術です。そのため、お客様のなかには、製品不具合の早期発見や業務改善など、大きな成果を上げて社内表彰を受けたり、それが昇進につながったりということで、我々に感謝してくださった方も数多くいらっしゃいます。
今後、ユースケースを拡大し、お客様のパフォーマンスを飛躍的に向上するお手伝いをしていきたいです。また技術面においても、テキストデータだけでなく、画像や動画を含むマルチメディアでの分析を可能にして、より多面的で新しい分析ができたら、現在では想像もできないおもしろいことができそうです。

女性技術者がしなやかに活躍できる社会を目指して 〜IBMフェロー浅川智恵子さんインタビュー
ジェンダー・インクルージョン施策と日本の現状 2022年(令和4年)4⽉から改正⼥性活躍推進法が全⾯施⾏され、一般事業主⾏動計画の策定や情報公表の義務が、常時雇用する労働者数が301人以上の事業主から101人以上の事業主 […]
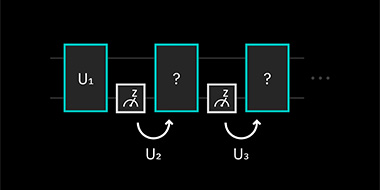
Qiskit Runtimeで動的回路を最大限に活用する
私たちは、有用な量子コンピューティングのための重要なマイルストーンを達成しました: IBM Quantum System One上で動的回路を実行できるようになったのです。 動的回路は、近い将来、量子優位性を実現するため […]
Qiskit Runtimeの新機能を解説 — お客様は実際にどのように使用しているか
量子コンピューターが価値を提供するとはどういうことでしょうか? 私たちは、価値を3つの要素から成る方程式であると考えます。つまりシステムは、「パフォーマンス」、「機能」を備えていること、「摩擦が無く」ビジネス・ワークフロ […]