Datan virtualisoinnin tekninen toteutus

Perinteinen tapa toteuttaa datan virtualisointi perustuu datan federointiin, jossa verkoston keskuskoordinaattori kerää ja osin käsittelee kaikkien solmujen lähettämän datan kuten alla on kuvattu. Tällöin koordinaattorista tulee laskennan pullonkaula.
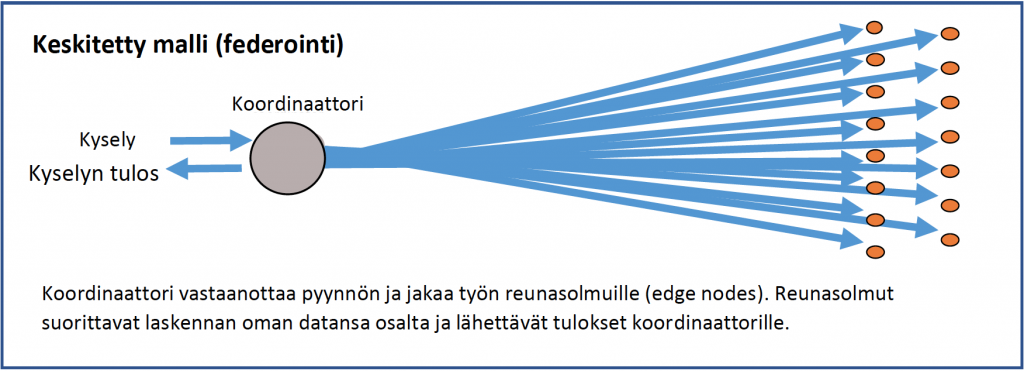
Datan federoinnin periaate (IBM:n ensimmäinen sukupolvi)
IBM:n uusi ratkaisu datan virtualisointiin muodostaa tietolähteiden verkoston, joka perustuu vertaissolmujen ympärille syntyvään itseohjautuvaan tähtikuvioon. Vertais- ja reunasolmuille hajautettu laskenta suorittaa valtaosan laskennasta jättäen koordinaattorille vain viimeistelytyön kuten alla olevassa kuvassa näkyy. Se on huomattavasti tehokkaampi kuin federointi ja takaa skaalautumisen käytännössä ilman rajoja.
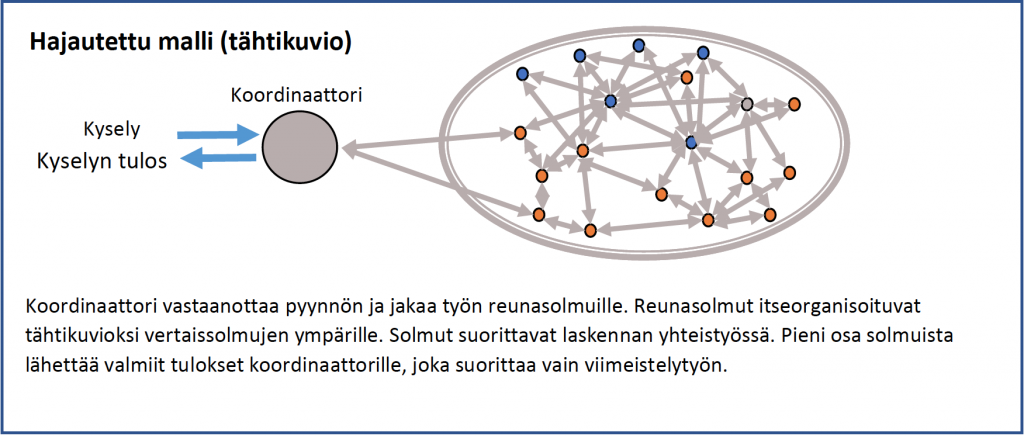
Hajautetun datan virtualisoinnin periaate (IBM:n toinen, nyt käytössä oleva, sukupolvi)
Hannu Löppönen
Data & AI Sales, IBM Finland
hannu.lopponen@fi.ibm.com
+358-400 839 730