SPSS Modeler ヒモトク
第3回 複数ファイル同処理のループ処理 – IBM SPSS Modelerスクリプトによる分析作業の効率化
2016年03月05日
カテゴリー SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:
複数ファイル同処理のループ処理(ループ処理+リストのパラメータ展開)
前回(第2回)の100個の入力ファイルの例のように、同じストリームを複数のファイルに適用するにはどうしたらよいでしょうか。入力ファイル名が 自動的に変更されながら、繰り返し処理が出来ると便利です。そこで、例を示しながら具体的な処理をご紹介します。今回は、ある企業における全国6支店の データに対して同じ処理を行う例を見てみます。
使用するストリームは下記の通りです。
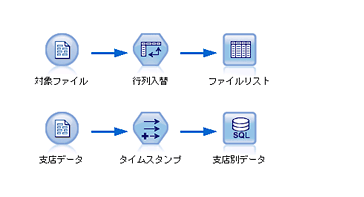
処理概要
最初に、読み込むファイルのリストを作成します。そして、スクリプトにファイル名の変数を用意し、リストから1つずつ読み込ませるようにします。
1. ファイル名の取得
事前にファイル名の一覧をファイルに保存しておきます。今回は1つのフォルダにある全ファイルを対象とし、MSDOSでコマンド「ls > ../filelist.txt」を実行してファイルリストを作成しました。これをループ処理で使えるように加工します。この方法は、特定のフォルダ内にある全ファイルを対象とする場合にファイル数がわからなくてもよいため、自動処理に向いています。
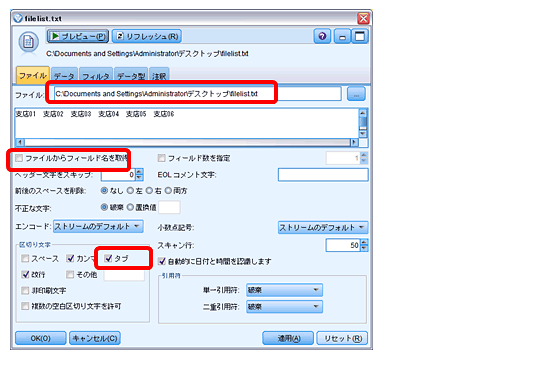
2. ストリーム:ファイルリスト作成
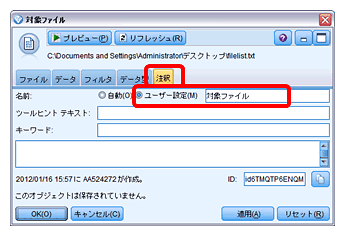
入力パレットの「可変長ファイル」ノードでfilelist.txtを指定して「ファイルからフィールド名を取得」のチェックを外し、区切り文字で 「タブ」をチェックします。また、スクリプト実行用にノードをユニークにするため、「注釈」タブの「名前」で「ユーザー設定」を選択し、ノード名を「対象 ファイル」とします。
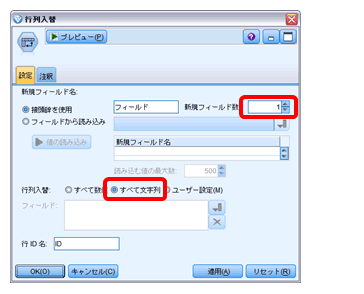
このままではファイル名が横持ちですので、フィールドパレットの「行列入替」ノードで縦持ちに加工します。「新規フィールド」を1、「行列入替」を「すべて文字列」に設定します。
「テーブル」ノードを繋いでノード名を「ファイルリスト」とします。テーブルを実行すると「フィールド1」にファイル名がリストされます。
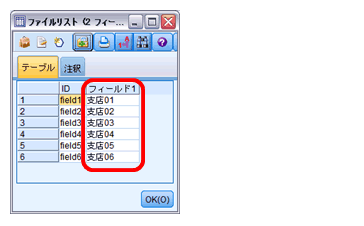
このようにリストを作成することで、ファイル数を固定する必要がなく、フォルダ内の全ファイルが対象となります。毎回ファイル数が変わる場合でも、スムーズに自動処理が行えます。
3. ストリーム:支店別データのエクスポート
次に、データ入力「支店データ」、データ加工「タイムスタンプ」、エクスポート「支店別データ」までのストリームを作成します。ここでは、データ加工として「タイムスタンプ」フィールドの追加を行います。
4. スクリプト
最後に、スクリプトを記述します。ポイントは、tablenodeオブジェクトのパラメータ「output」を使うことです。テーブル出力結果をループ処理で一行ずつ順に読み込ませることが出来ます。そして、ファイルリストのp行目2列目の値をファイル名「file_nm」とし、それを「支店データ」ノードの参照ファイルとして設定します。
また、テーブル行数をカウントできる「row_count」を使うと、「行数=ループ回数」として変数に当てはめられます。ループ回数を固定する必要がないので、毎回対象ファイル数が変わるバッチ処理にも最適です。ここでも、ループ処理をファイルリストの行数分だけ繰り返します。
「tablenode.output」を有効にするには、スクリプト内でテーブルノードを実行する必要があります。そして、リスト参照処理が終わったら、必要に応じてテーブル出力を閉じて(削除して)おきます。
スクリプト全体は下記の通りです。
set last_row= ファイルリスト:tablenode.output.row_count /* ファイルリストの行数カウント */
var p
set p=1
var file_nmfor p from 1 to last_row /* ループ処理 ここから*/set file_nm= value ファイルリスト:tablenode.output at ^p 2 /* p行目2列目の値をファイル名「file_nm」に設定 */
set 支店データ:variablefilenode.full_filename = “C:Documents and SettingsAdministratorデスクトップModelerScript_tecDoc\” >< ^file_nmif p=1 then
set 支店別データ:databaseexportnode.write_mode = Create /*初回はモードを「テーブ作成」に設定*/
else
set 支店別データ:databaseexportnode.write_mode = Append /*次の処理のためにモードを「テーブルへ挿入」に設定*/
endifexecute ‘支店別データ’set p=^p+1endfor /* ループ処理 ここまで*/delete output :tableoutput /* 出力されたテーブルを閉じる */
ループ処理やテーブル出力によるパラメータ展開は、自動化処理で重宝する手段の一つです。他にも様々な場面に利用できます。そこで、次章以降はこれらを使った効率的な処理方法をいくつかご紹介します。

データ分析者達の教訓 #19- ちゃぶ台返しを受けないため「最初に」現場と握っておく
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちはIBM の斉藤です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、デー ...続きを読む
データ分析者達の教訓 #18- データの向こうにある社会的背景や因果関係を洞察せよ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
こんにちは。IBM Data&AIでデータサイエンスTech Salesをしている西牧です。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を進める上で ...続きを読む
データ分析者達の教訓 #17- データ分析はチーム戦。個々がミス最小化の責任を持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。山下研一です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活 ...続きを読む