

























SPSS Modeler ヒモトク
身近な疑問をヒモトク#11-流行りのソーシャルリスニング!SNSのデータってどうやって活用するの?
2022年11月18日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさん、こんにちは。日立ソリューションズ東日本の柴田です。
SPSSやCognosなどIBM製品を活用したデータサイエンティストとして、お客様の課題解決に向けた支援を9年ほど担当しています。近年では、テキストデータの活用が増えてきており、楽しさの反面、覚える知識量の多さや分析の奥深さに四苦八苦している毎日です。今回は、前回のヒモトクに続いてテキスト分析に関するテーマで、SNSに投稿されたテキストデータを対象とした感情分析についてご紹介したいと思います。
SNSのテキストデータを活用した商品やサービスの分析やマーケティングは一般的な時代になり、多くの企業が炎上対策やブランディングに取り入れています。企業同士のコラボレーションを行ったり、インフルエンサーが商品の使用感やおすすめポイントを画像付きで紹介したりすることにより、潜在ユーザーへの効果的な広告に繋げるUGC(User Generated Contents=ユーザーの手によって制作・生成されたコンテンツ)など、様々な戦略が図られています。その中でも、一般ユーザーの素朴な投稿内容に対して、突如のリプライなどのコミュニケーションによって、一般ユーザーの顧客満足度の向上に繋げるような企業が増えています。
このような企業はどのようにして、SNS上の投稿に反応しているのでしょうか。
この記事ではこのような内容について、テキストマイニングの基礎知識を使って紐解いていきたいと思います。

今回、SNSのデータに注目したきっかけ
ICT総研が公表している「2022年度SNS利用動向に関する調査」では、日本のSNS利用者が2022年末には8270万人に達する見込みだと発表されています。2024年末には、国内ネットユーザーに対する普及率は83%を超え、8388万人までに拡大すると見られており、今や我々の生活になくてはならないものとなっています。
参照元;日本のSNS利用動向2022、利用目的は「情報収集」がトップ、満足度高いのは動画系
私も、日常でSNSのサービスをよく使用しており、いろんな企業がプロモーションしている風景をよく見ます。特にここ一年で印象的だったのは、「化粧がうまくいかないとSNSに書き込みしたら、化粧品の会社から使い方のコツを教えてもらえた!」という私の知人の事例でした。他の企業でも似たような事例があるかな?と探してみたところ、「○○のネットショッピングを何回も使っているのに、未だに初回購入者向けの宣伝が届いて迷惑!」といったSNS上のクレームに、企業側が20分弱の時間でクレーム対応していたという事例もありました。どうやら、その企業ではソーシャルリスニングツールを活用しているようでした。このような事例から、自然言語処理を活用したこのようなソーシャルリスニングの仕組みは、どのように行われているのだろうと思ったのが今回のきっかけとなります。
身近な疑問の設定
今回の疑問は、私の知人が経験した事例を参考に設定します。
私の知人の投稿内容の特徴は以下のような内容でした。
・化粧品に関する文章を3件程度投稿しており、一部投稿に商品名が記載されていた
・「化粧品Xでは〇〇ができなかった」など、一般ユーザーとしての不満や悩みが記載されていた
・投稿内容には化粧品の画像もアップされていた
・拡散されていなかった(不特定多数のユーザーの注目を浴びていたわけではなかった)
企業の立場から見ると、画像データから商品を特定したと考えることはできますが、連投された複数のSNSのテキスト情報を連結することで、商品を特定できるような気がします。
一般ユーザーの不満や悩みに対してSNSを活用した早急な対策をとることを想定とした目的設定とし、「化粧品に対するネガティブな文章」を抽出して確認するデータ分析をしてみたいと思います。
使用するデータ
・特定の企業の化粧品名が記載されている架空のテキストデータ
今回は公開されているAPIなどは使用せず、弊社内で作成したS社という架空の化粧品メーカーに関して記載されたテキストデータ1000件を使用します。SNSのサービスによっては、公開されているAPIの商用利用が制限されている場合がありますので、APIを利用する前にライセンス規約を事前にご確認ください。
・極性辞書
ポジティブ・ネガティブな単語が登録された極性辞書を使用して、テキストデータにネガティブな単語が含まれているかを判定することができます。日本語で公開されている極性辞書はあまり多くありませんが、以下の2つが公開されています。
日本語評価極性辞書:東北大の乾・岡崎研究室が公開
単語感情極性対応表:東工大の高村教授が公開
単語感情極性対応表は各単語のネガティブ度をスコア化したデータをもちますが、研究目的のみの利用に制限されています。今回は、日本語評価極性辞書を使用して、ポジティブな単語とネガティブな単語の個数をカウントしてみたいと思います。
SPSS Modelerでテキストマイニングする方法
SPSS Modelerで自然言語処理をする方法は主に以下2点の方法があります。
- 拡張ノードでPython・R連携する (→この方法を解説する記事はこちら)
- 有償のテキスト処理テンプレートを利用する (→SA社の製品説明はこちら)
今回は以下の流れでデータを加工・集計します。
・テキストデータに一意のIDを付与する
・拡張ノード(今回はRを使用)でテキストを形態素解析し、各テキストで出現した単語がわかるように一覧化する
・極性辞書を使用して、単語のネガティブ・ポジティブを判定し、それぞれのカウント値を各テキストのネガポジのスコアとする
ご参考までに、下図のようなストリームを作成して検証しました。
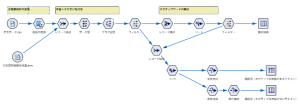
分析結果の例
S社または商品Aに関してネガティブな単語が検出された結果が以下となります。テキストデータの内容を見ていくと、ネガティブな単語数が少ないものであってもSNS上で対応を取ることで顧客満足度の向上に繋げることができると思われるテキストがありました。

#126は商品としての欠陥に対するクレームのように思います。SNSによる早急な対策は難しいかもしれませんが、今後の商品開発のアイデアとして参考にさせて頂く旨をユーザーに伝えると、ユーザーの不満を和らげることができるかもしれません。#750はサプライチェーンに課題があるように思われます。駅名が記載されているようなので、もし、近くの販売店があれば購入機会が生まれるかもしれません。
一方、ネガティブな単語が検出できなかったテキストデータの中にも、クレームと思われるテキストが見つかりました。特に、#479はメーカー側が交換対応などを実施することで顧客満足度の向上に繋がる投稿のように思えます。このようなテキストも抽出できるようにしたいです。

課題
抽出結果の精度がまだまだ低く、極性辞書を見直すことで精度改善ができるかと思います。ここで重要になってくるのはメーカー側の視点です。例えば、「シミ」や「肌荒れ」などはネガティブな単語として今回の極性辞書に登録されています。確かに、化粧品というジャンルとしてはネガティブな単語に該当し、ユーザーとしては悩ましいことではあります。しかし、メーカー側としてはなかなか早急に対策するのは難しい課題のようにも思えます。また、SNS上でメーカー側がユーザーに直接反応するトピックとしてはセンシティブな内容にも感じます・・・。
メーカー側の視点として、「商品として欠陥があったか」「ユーザーを商品に届けるまでの過程に不備があったか」というような仮説の下、不足している単語の存在を確認し、極性辞書に単語の追加を検討するのが好ましいのではないかと思います。例えば、分析結果の例にある#26はデザインに関するクレーム、#50と#479は商品流通に関するクレームとして分類し、ベイジアンネットワークでそれぞれのクレーム分類と単語の関係性モデル化すると、クレームに繋がる重要な単語を発見できるのではないかと考えられます。特に、「返品」は流通のクレームに関連するネガティブな単語として関連がありそうですね。なので、学習データを準備して実際にモデル生成を・・・と今回やってみたかったのですが、残念ながら時間切れとなってしまいました。
まとめ
現代のマーケティングでは、顧客理解のために最も優れた手法がソーシャルリスニングといっても過言ではないと思います。データ分析全般にいえることではありますが、SNSデータは特に非常に膨大で多様なので、売上成果の向上化やブランドイメージの生成など明確な目的設定をして、効果的に活用できるように分析を工夫していきたいです。
ちなみに、前回のヒモトクでIBM河村さんからご紹介頂いたWatsonDiscoveryでは、より強力なテキストマイニングの分析機能が搭載されているようです!もしかしたら、今回の課題も簡単に解決できるかもしれませんね。
次回で「身近な疑問をヒモトク」はリレー連載最終回。アンカーSPSSの牧野さんが「その統計本当に有意なの?」を執筆されます。お楽しみに。
→これまでのSPSS Modeler ブログ連載のバックナンバーはこちらから

柴田 直倫
株式会社日立ソリューションズ東日本
産業ソリューション事業部 ビジネスソリューション本部
アナリティクスソリューション部
・日立ソリューションズ東日本 データ分析ソリューション
https://www.hitachi-solutions-east.co.jp/products/dataanalytics/
・日立ソリューションズ東日本 予兆検知ソリューション(製造データ分析)
https://www.hitachi-solutions-east.co.jp/products/sign/

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む