

倉田 岳人
日本アイ・ビー・エム株式会社
技術理事
2004年入社。以来、同社東京基礎研究所にて、音声言語情報処理の研究に従事。2013年東京大学より博士号取得。現在はAI Technologies担当シニア・マネージャーとして、音声認識、自然言語処理の基礎研究、および国内外事業部門との協業を推進。IEEE SLTCメンバー。IEEE、情報処理学会各シニア会員。博士(情報理工学)。

吉田 一星
日本アイ・ビー・エム株式会社
東京基礎研究所 ナレッジ・インフラストラクチャー マネージャー
2001年入社。以来、自然言語処理(NLP)・テキストマイニングの基盤技術の研究・製品開発・お客様向けソリューション開発に従事。現在は主に製品向けNLP技術の研究プロジェクトのマネジメントを行う。隙あらば自らプログラムを書く。

金田 大樹
日本アイ・ビー・エム株式会社
Data & AI事業本部 テクニカル・セールス
2016年入社。入社後はGPUサーバーの技術営業職として活動。その後、画像解析や機械学習に関する製品・プロジェクトを担当し、お客様内における数百人規模の社内AI教育展開等を主導。お客様内でのデータ・AI活用の定着を目指し、ハンズオンや教育を交えた提案活動に従事。
はじめに
皆さんは「基盤モデル」という言葉を聞いたことがあるでしょうか?
基盤モデル(またはファウンデーション・モデル)とは、大量かつ多様なデータで訓練されたAIモデルの一種であり、様々なアプリケーションの”基盤”の役割を果たす大規模なAIモデルです。
本ブログでは、基盤モデルが生まれた背景/モデルの意味とその特長/IBMソリューションにおける応用例(Answer Finding)を挙げ、基盤モデルの意義を説明いたします。
AI開発とその課題
ここ10年の間に、AI(人工知能)アプリケーションの活用は爆発的に広がりました。当初は、純粋に学術的な試みだったAIは、今や様々な産業において、数えきれないほど多くの人々の生活に影響を及ぼす原動力になっています。例えば、人間の担当者の代わりに顧客と会話するチャットボットを動かすためには、音声認識や自然言語処理などのAI技術が欠かせません。より最近では、有名なアーティストの作品から学習して新しい芸術作品を生成したり、化学の教科書の知識を用いて新しい化学物質を生み出したりするようなAI技術も登場しています。
これらのAI技術の背後に共通して存在するのが、機械学習によるモデルです。モデルとは、特定の問題を解決するための知識が書かれたデータと、そのデータから知識を吸い上げる学習アルゴリズムによって作られる、問題を解く際にAIが参照する知識源のようなものです。
たくさんの新しいAI技術が様々な問題を解決するのに役立っていますが、モデルを学習するために問題ごとに別々に大量のデータを用意する必要があります。多くの場合、質の良いデータを作成するには人手に頼るしかなく、AI技術を幅広い分野に効率的に適用する上でのボトルネックとなっています。また、最近のモデルは学習に膨大な計算機資源を要します。例えば、一つの大規模自然言語処理モデルを学習する際にデータ・センターで消費されるエネルギーは、5台の自動車がその使用期間の間に排出するのとおよそ同量の二酸化炭素に相当するとも言われています。
これらの課題を解決するのが、次に述べる基盤モデルです。この言葉は米スタンフォード大学の研究者らによって初めて広められました。
基盤モデル
基盤モデルも、前述の機械学習モデルの一種です。これまでのモデルと大きく異なる点は、構築のために特定の問題向けのデータを必要としないことです。

自然言語処理の場合を例にして説明すると、要約生成や文書分類といった問題を解くための専用のデータを用意する代わりに、特別な工夫を施していない大量の文書データを用意します。
この文書データの一部の単語を隠した状態でデータを学習アルゴリズムに読ませることで、学習アルゴリズムは「隠された単語をその周囲の単語から予測する」モデルを構築することができます。
これは自己教師あり学習とも呼ばれ、自然言語の性質、つまり「ある単語の次にどのような単語が来やすいか」といった、単語の並びに関する傾向などをモデルに覚えさせることを可能とするのです。
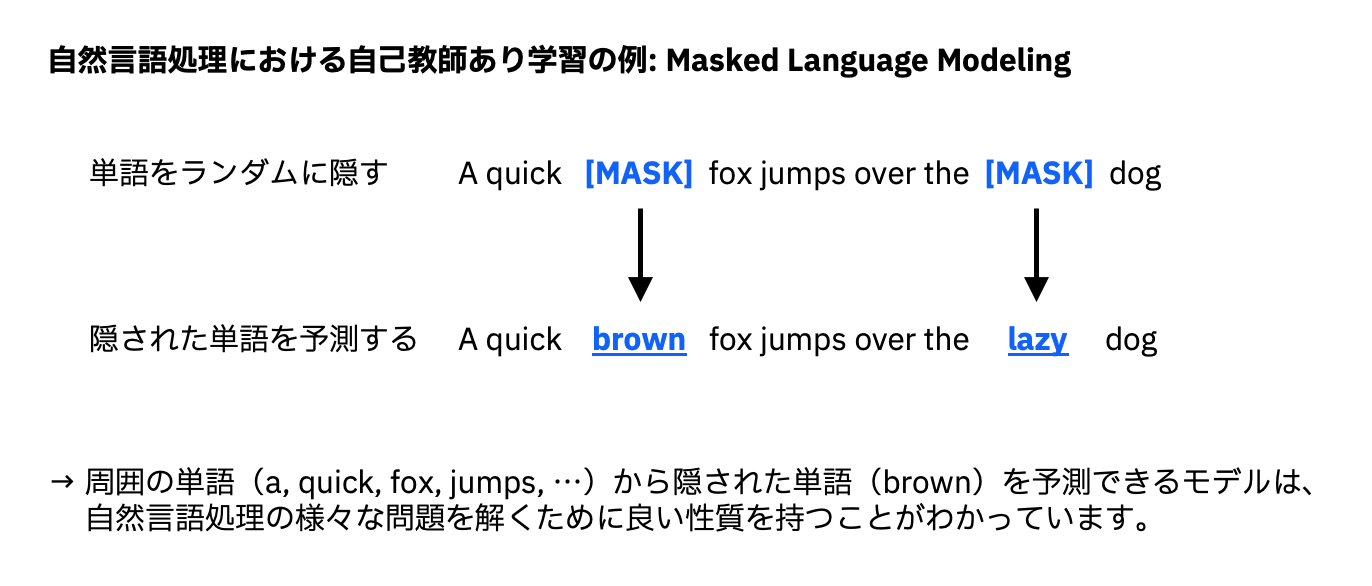
このように学習された基盤モデルを活用して、特定の問題、例えば要約生成のための専用モデルを、非常に少量の「要約生成向けデータ」から短期間で構築できるようになりました。基盤モデルが、文字通り新たな種々の問題を解く基盤となり、問題ごとに必要なデータの量と学習に要する計算機資源の大幅な削減を実現しました。
Answer Findingについて
基盤モデルの自然言語分野での実用化の例として、 Answer Finding を紹介いたします。
Answer Findingは、基盤モデルを用いて開発されたモデルを文書検索に利用したもので、文書からさまざまな情報を引き出し活用するためのプラットフォーム “Watson Discovery” の機能として、IBM Cloud上で提供しています。
Watson Discoveryは社内外に存在する文書を収集し、情報の抽出・知識の補完により文書の利用価値を高めるソリューションとして、2016年にリリースされました。Watson Discoveryに読み込まれた文書は自動的にその内容が解析され、ユーザーは必要とする情報を簡単に取り出すことができます。これまで、コールセンターでの対応品質向上や、機械故障時の対応速度向上など、多くのお客様において活用が進んでいます。
大量の文書の中から必要な情報を探し出すときには、Watson Discoveryの検索機能を利用することができますが、活用のケースによっては、さらに詳細に記述を特定したいケースがあります。例えば製造業のお客様において、製造ラインが故障しコンベアが稼働しなくなった場合には、「コンベアが停止した場合の復旧方法は?」と入力して答えを探し出したいとします。キーワードによる文書検索でそれらの単語を含む文書の一覧を得ることができますが、それらが必ずしも質問の趣旨と一致しているとは限りません。
このような場合にはAnswer Findingの機能を使うことで、ユーザーはよりピンポイントに質問の答えの書かれた文書とその箇所を絞り込むことができます。
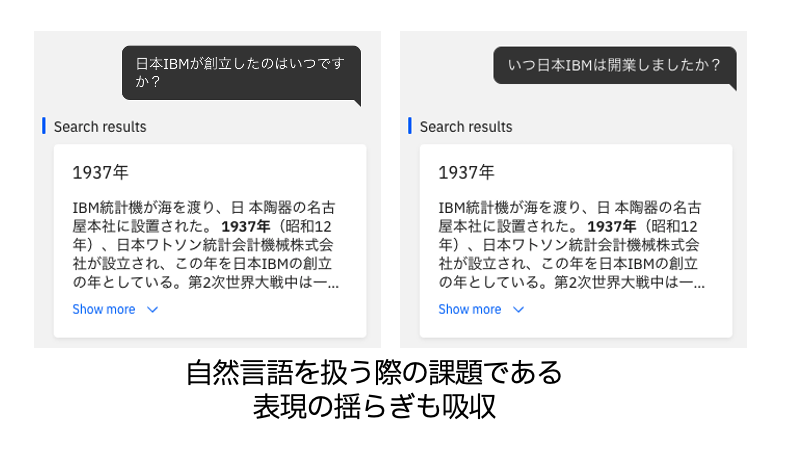
ここでは、Answer Findingに新たに日本IBMの会社情報を読み込ませた場合の応答実例を紹介します。
Answer Findingにいくつか質問をしてみると、下記のような回答を返します。
- 「日本IBMの代表取締役社長は誰ですか」と質問すると、「山口 明夫」と返します。
- 「基礎研究所は幾つありますか」と質問すると、「19カ所」と返します。

また、読み込ませた元の文書では、日本IBMが誕生した年度について「設立」という単語を用いて説明されていますが、「創立」や「開業」という表現に変えて質問しても回答を返しています。
Answer Findingには、基盤モデルから作られたAIモデルが組み込まれています。一般に、ユーザーはAnswer Findingを利用することで基盤モデルの力も借り、質問者の意図を高い精度で汲み取り、ピンポイントで求められた回答を導くことができます。
これは基盤モデルから作られたAIモデルが、質問に対する答えがどのようなものであるべきかを的確に把握することにより可能となっています。それにより多数の検索結果の中から最も質問の答えとしてふさわしい箇所を推測できるのです。
最後に
基盤モデルの利用方法は、Answer Finding のように、IBMが提供する学習済みのモデルをご利用いただくだけにとどまりません。
IBMは2023年5月、お客様ご自身のデータでのお客様専用の基盤モデルの構築や下流タスクにむけての追加学習、学習済みのモデルの利用まで行えるプラットフォームとして、watsonx.aiを発表しました。このプラットフォームでは、IBM Researchによって開発されたIBM独自の基盤モデルが用意されています。これらのモデルは透明性が担保され、ビジネス利用にも適しています。また、オープンソースの基盤モデルを利用することもできます。
このようにIBMは、お客様とのco-creationを通じて、基盤モデルのさらなる活用を目指しています。



