
社内文書のテキストデータも貴重なデータ
これからの時代、企業の競争力はデータ活用が左右する――。そんなことが言われて久しいが、データをどのように活用するかだけでなく、それ以前に「活用するためのデータがない」と悩む企業が多い。しかし、どんな企業にも社内に数多くの文書が存在し、それらも活用可能なデータのひとつに数えられる。ちなみに、ここで言うデータとは、必ずしもデータベースや数値を指すのではなく、企業内の情報すべてが活用の対象となる。
では、具体的にどのようなデータを、どのように活用できるのか。今回は、IBMのテキスト検索・分析ツール「IBM Watson Explorer(以下、Watson Explorer)」を使った社内データの活用方法について紹介する。
日本で開発された言語解析エンジンを搭載
Watson Explorerは、企業内にあるテキストデータを検索・分析するためのソリューションで、強力な検索と高度なデータ分析という2つの機能を備え、非構造化データを扱える点が最大の特長となる。
非構造化データとは、コンピュータ処理上決まった形式で統一・整備されていないデータを指し、典型的な例として人が書いた文章(自然言語テキスト)が該当する。企業文書の多くは、この類のテキストデータであり、自然言語テキストを正しく分析するためには、いかに文章の意味内容を認識する必要があり、これまでコンピューターでの扱いは難しいとされてきた。
しかし、Watson Explorerは、長年にわたりIBM東京基礎研究所で研究開発されてきた言語解析エンジンを備え、日本語をはじめとする17カ国語の自然言語テキストを分析し、その意味を認識することができる。また、日本人の研究者が中心となって開発されたため、この手のツールの中でも、日本語への理解が深い。
顧客の声から「インサイト=重要な知見」を見つけ出す
Watson Explorerは、自然言語テキストを意味解釈できるという特長から、VoC(Voice of Customer:顧客の声)が蓄積されるコールセンターや顧客の窓口となっている現場で顧客が発信した情報をもれなく理解するために活用されることが多い。通常、コールセンターでは顧客からの問い合わせに対し、オペレーターが膨大なFAQから適切な回答を探し出すという作業が発生する。そのスピードが早ければ早いほど顧客満足度は向上し、オペレーター自身の負担も軽減される。しかし、そのスピードは担当者の経験やスキルに依存する部分が大きく、サービスの均質化が課題のひとつとなっていた。
ここで力を発揮するのが、Watson Explorerの自然言語処理能力だ。Watson Explorerは顧客からの問い合わせ内容を理解し、瞬時に回答を探し当てることで担当者の作業を的確にサポートしていく。
お客さまの「声」を商品・サービスの改善に役立てた三井住友海上火災保険株式会社のWatson Explorer活用事例はこちら
ITヘルプデスクもFAQとの組み合わせで効率化
ある総合商社では、Watson Explorerを社内FAQの検索システムと組み合わせることで、社員が自力で課題の解決策を見つけられるようにするITヘルプデスクの効率化に取り組んだ。このシステムでは、質問内容への答えとなる情報が掲載されたFAQの検索に加え、自然言語での質問にも対応しており、適切な回答を社員の検索スキルに左右されることなく返答することができる。さらに、質問の頻度や回答の適切度などを利用履歴に基づいて機械学習する仕組みを備えており、ITヘルプデスクを利用するほど、回答品質や精度が高まっていく。社員自らいつでも素早く解決策を見つけられる環境を実現することで、業務の効率化はもちろん、調査作業のストレス軽減にもつながる。ヘルプデスク担当者も、負担が減ることでより重要な業務に集中できるようになる。
Watson Explorerを活用して社内ポータルの検索機能を向上した全日本空輸様事例はこちら

専門領域や業務固有の表現の多いテクニカルドキュメントにも対応
また、ある通信会社では、SNSで位置情報を発信するユーザーが投稿したテキストの分析にWatson Explorerを活用している。SNSで発信された「〇〇の電波がつかまらない」「〇〇の回線が遅い」といった自社サービスに関する投稿のうち、位置情報が含まれているものをリアルタイムで検索・抽出して地図上に表示することで、障害や問題をいち早く把握できるようにしている。対象がSNSだと、収集する領域やワード量によっては、扱う投稿は数千万といった規模になることもある。しかし、ビッグデータに対応しているWatson Explorerであれば、そのような大量データの分析にも対応できる。
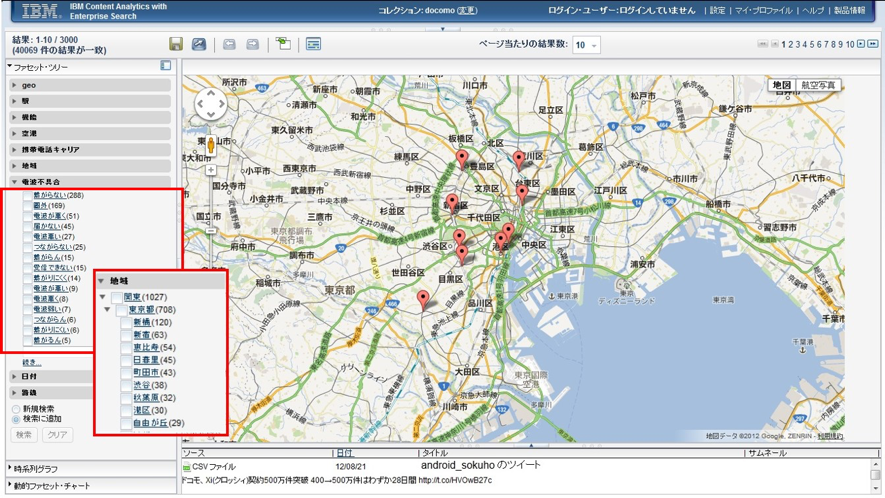
通信会社の例。SNSで発信された自社サービスへの投稿をリアルタイムで検索・抽出し、投稿に含まれる位置情報に基づいて地図上に表示する
また、医療の領域では「トプラマイシン剤の投与により発疹が軽減した」というテキストをWatson Explorerが読んだ場合には、内部的にそれぞれの単語に解釈を付加する仕組みがあることにより、トプラマイシン剤が症状を改善させた意味であることを正しく理解する。
他にも、膨大な量の学術文献から、あるタンパク質に関する知識や情報の抽出に活用している製薬会社や、ヒヤリ・ハットの業務報告書から重要キーワードを抽出し、事故防止に活用している石油会社の事例も存在する。また、製造業では請求項の文章の中からコアアイディアを抽出し、特許文書を分析して将来性のある技術トレンドを発見するという使い方もされている。
このような専門用語や専門的な言い回しが多い文書が対象だと、一般的な辞書や分類定義だけに基づいていては適切な分析ができない。しかし、Watson Explorerでは、独自の辞書や分類定義を構築できる仕組みが用意されているので、専門用語や専門的な言い回しの把握も可能になる。例えば、前述の石油会社の場合は「漏れ」という用語が重大な事故を示すワードになっていたが、事業所や装置に関する報告書で「漏れ」そのものではなく関連する表現が増加していたら、危険の前兆として注意することで事故発生を未然に防いでいる。
辞書の制作は一から構築すると非常に手間のかかる作業だが、分野辞書の制作ツールである「IBM Watson Knowledge Studio」では、機械学習モデルを取り入れることで、既存の文書を素材にして分野辞書を効率的に制作することができる。さらに、その制作した辞書はWatson APIでも利用可能だ。
冒頭で述べた「これからの時代、企業の競争力はデータ活用が左右する」との言葉は、既に現実のものとなっている。上記で紹介したユースケースは、ひとつの例に過ぎない。どんな会社でもデータとなる文書は存在しているが、その中には、ビジネスに多大な貢献をもたらす宝が隠されているかもしれない。
photo:Getty Images


